Yet another classifier
Instead of intro
Laziness is the engine of progress. You do not want to grind grain yourself - make a mill, you do not want to throw stones at enemies - build a catapult, get tired of burning inquisition on bonfires and bend your back under the feudal lord - muddle with the guys renaissance ... however, what is it about me.
Automation, gentlemen. You take some useful process in which a person participates, you replace a person with a complex mechanism, you get a profit. Relatively recently, it has also become fashionable to replace a person with a piece of code. Oh, how many noble professions can fall under the onslaught of informatization. Especially when you consider that a piece of code in our time is capable not only of predefined behavior, but also of “learning” some behavior.
Generalize a little
Generally speaking, such superpowers for the algorithm, which embodies our piece of code, are called not just training, but machine learning (machine learning). Usually we mean that only something endowed with intelligence is capable of learning. And, not surprisingly, the discipline of machine learning is included in a much more general discipline of artificial intelligence (artificial intelligence aka AI)

As is clear from the picture, many AI tasks are based on machine learning algorithms. It remains only to choose something fun and not less fun to solve.
And fantasize
Suppose you,% username%, were hired by a machine learning specialist for a company that owns the IMDb site. And they say they say, now we want aki from Russian Ivanov at their Kinopoisk, user reviews are marked with a color green or red depending on whether a positive or negative review. And here you seem to understand that it is necessary to take an indecent size base with reviews and issue a algorithm that will be well trained and will divide all of their sets into two non-intersecting subsets (classes), so that the probability of error is minimal.
Like a person, our algorithm can learn either from its mistakes (learning without a teacher, unsupervised learning), or using someone else's example (learning with a teacher, supervised learning). But, in this case, he himself cannot distinguish between positive and negative, since he was never called to parties and he had little contact with other people. Therefore, it is necessary to obtain a sample of reviews already marked up on classes (training sample) in order to carry out training on ready-made examples (precedents).
So, we want to solve the problem of the analysis of opinions (sentiment analysis) related to the tasks of processing natural language (natural language processing), having trained a certain classifier, which for each new review will tell us whether it is positive or negative. Now you need to choose a classifier and code the whole thing.
God how naive
In general, a huge number of different classifiers are found in the wild. The simplest thing we could think of here is to attribute all the articles, for example, to positive ones. Result: no need to learn, classifier accuracy 50%, interest 0%.
But if you think about it ... How do we choose the class to which we will place the next object? We choose it so that the probability of the object belonging to this class is maximum (captain!), I.e.

where C is a class and d is an object, in our case it is a review. Thus, we are trying to maximize the a posteriori probability of a review belonging to a positive or negative class.
Having seen the conditional probability, it immediately suggests itself to apply the Bayes theorem to it, and since we are still looking for the maximum, it still suggests that we should reject, as unnecessary, the denominator, having received as a result:

All this is cool, you say, but where do you get these miracle probabilities in real life? Well, with P everything is simple: if you have a training sample that adequately reflects the distribution of classes, you can evaluate:

where n is the number of objects belonging to the class C, N is the sample size.
With P (d | C) everything is a bit more complicated. Here we must make a “naive” assumption about the independence of individual words in a document from each other:

and understand that the recovery of n one-dimensional densities is a much simpler task than one n-dimensional one.
In this case, the training sample can be estimated:

where m is the number of words w in the class C, M is the number of words (or more precisely, tokens) in the class C. So we got:

such a classifier is called the naive Bayes classifier.
A few words about the validity of the naive assumption of independence. Such an assumption is rarely true, in this case, for example, it is clearly incorrect. But, as practice shows, naive Bayes classifiers show surprisingly good results in many problems, including those where the assumption of independence, strictly speaking, is not fulfilled.
The advantages of the naive Bayes classifier are insensitivity to the size of the training sample, high learning speed and resistance to the so-called retraining (overfitting is a phenomenon in which the algorithm works very well on a training sample and is bad on a test one). Therefore, they are used either when the initial data is very small, or when there is a lot of such data, and the speed of learning comes first. Disadvantages: not the best accuracy, especially if the assumption of independence is violated.
')
Developers, developers, developers
And now for those who are desperate to see the code . The IMDb review collection, prepared by Cornell University (whose employees themselves conducted an interesting study with this data), was taken as a training sample .
The most interesting methods are add_example and classify. The first, respectively, is engaged in training, restoring the necessary probability density, the second - applies the resulting model.
def add_example(self, klass, words): """ * Builds a model on an example document with label klass ('pos' or 'neg') and * words, a list of words in document. """ self.docs_counter_for_klass[klass] += 1 for word in words: self.token_counter_for_klass[klass] += 1 self.word_in_klass_counter_for[klass][word] += 1 Education is very straightforward - we get the words from the review and its labeled class. We count the number of documents in the class n, the number of words in the class M, and the number of words w in the class are m. All further classify.
def classify(self, words): """ 'words' is a list of words to classify. Return 'pos' or 'neg' classification. """ score_for_klass = collections.defaultdict(lambda: 0) num_of_docs = sum(self.docs_counter_for_klass.values()) for klass in self.klasses: klass_prior = float(self.docs_counter_for_klass[klass]) / num_of_docs score_for_klass[klass] += math.log(klass_prior) klass_vocabulary_size = len(self.word_in_klass_counter_for[klass].keys()) for word in words: score_for_klass[klass] += math.log(self.word_in_klass_counter_for[klass][word] + 1) score_for_klass[klass] -= math.log(self.token_counter_for_klass[klass] + klass_vocabulary_size) sentiment = max(self.klasses, key=lambda klass: score_for_klass[klass]) return sentiment Because the probabilities can be very small numbers, and we are still engaged in maximization, we can, without a twinge of conscience, predict everything:
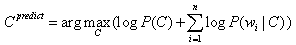
- this explains what is happening. The resulting classes, respectively, is the one that received the maximum score.
def cross_validation_splits(self, train_dir): """Returns a lsit of TrainSplits corresponding to the cross validation splits.""" print '[INFO]\tPerforming %d-fold cross-validation on data set:\t%s' % (self.num_folds, train_dir) splits = [] for fold in range(0, self.num_folds): split = TrainSplit() for klass in self.klasses: train_file_names = os.listdir('%s/%s/' % (train_dir, klass)) for file_name in train_file_names: example = Example() example.words = self.read_file('%s/%s/%s' % (train_dir, klass, file_name)) example.klass = klass if file_name[2] == str(fold): split.test.append(example) else: split.train.append(example) splits.append(split) return splits For the most complete use of available data, cross-validation was applied (k-fold cross-validation): the available data is divided into k parts, then the model is trained in k − 1 data parts, and the remaining data is used for testing. The procedure is repeated k times, as a result, each of the k parts of the data is used for testing. The resulting efficiency of the classifier is simply calculated as the average.
Well, in order to fully achieve Zen, I attach a picture depicting the learning process with the teacher (in general):

What is the result of all this?
$ python NaiveBayes.py ../data/imdb1
[INFO] Performing 10-fold cross-validation on data set: ../data/imdb1
[INFO] Fold 0 Accuracy: 0.765000
[INFO] Fold 1 Accuracy: 0.825000
[INFO] Fold 2 Accuracy: 0.810000
[INFO] Fold 3 Accuracy: 0.800000
[INFO] Fold 4 Accuracy: 0.815000
[INFO] Fold 5 Accuracy: 0.810000
[INFO] Fold 6 Accuracy: 0.825000
[INFO] Fold 7 Accuracy: 0.825000
[INFO] Fold 8 Accuracy: 0.765000
[INFO] Fold 9 Accuracy: 0.820000
[INFO] Accuracy: 0.806000
With filtering stop words:
$ python NaiveBayes.py -f ../data/imdb1
[INFO] Performing 10-fold cross-validation on data set: ../data/imdb1
[INFO] Fold 0 Accuracy: 0.770000
[INFO] Fold 1 Accuracy: 0.815000
[INFO] Fold 2 Accuracy: 0.810000
[INFO] Fold 3 Accuracy: 0.825000
[INFO] Fold 4 Accuracy: 0.810000
[INFO] Fold 5 Accuracy: 0.800000
[INFO] Fold 6 Accuracy: 0.815000
[INFO] Fold 7 Accuracy: 0.830000
[INFO] Fold 8 Accuracy: 0.760000
[INFO] Fold 9 Accuracy: 0.815000
[INFO] Accuracy: 0.805000
I leave the reader to think about why filtering stop words has affected the result so much (well, that is why it almost didn’t have any effect at all).
Examples
If we move away from stingy numbers, what did we really get?
For seed:
"Yes, it IS awful! The books are good, but this movie is a travesty of epic proportions! 4 people in front of me stood up and walked out of the movie. It was that bad. Yes, 50 minutes of wedding...very schlocky accompanied by sappy music. I actually timed the movie with a stop watch I was so bored. There is about 20 minutes of action and the rest is Bella pregnant and dying. The end. No, seriously. One of the worst movies I have ever see" Such a review is clearly recognized as negative, which is not surprising. It is more interesting to look at errors.
" `Strange Days' chronicles the last two days of 1999 in los angeles. as the locals gear up for the new millenium, lenny nero (ralph fiennes) goes about his business of peddling erotic memory clips. He pines for his ex-girlfriend, faith (juliette lewis ), not noticing that another friend, mace (angela bassett) really cares for him. This film features good performances, impressive film-making technique and breath-taking crowd scenes. Director kathryn bigelow knows her stuff and does not hesitate to use it. But as a whole, this is an unsatisfying movie. The problem is that the writers, james cameron and jay cocks ,were too ambitious, aiming for a film with social relevance, thrills, and drama. Not that ambitious film-making should be discouraged; just that when it fails to achieve its goals, it fails badly and obviously. The film just ends up preachy, unexciting and uninvolving." This review has been marked as positive, but has been recognized as negative. Here you can ask a question about the correctness of the original mark, because even a person, in my opinion, is difficult to determine whether this review is positive or negative. It is not surprising, at least, why the classifier referred it to the negative: unsatisfying, fails, badly, unexciting, uninvolving, are quite strong indicators of the negative, outweighing the rest.
And, of course, the classifier does not understand sarcasm and in this case easily takes the negative for the positive:
"This is what you call a GREAT movie? AWESOME acting you say?Oh yeah! Robert is just so great actor that my eyes bleeding when I'm see him. And the script is so good that my head is exploding. And the ending..ohhh, you gonna love it! Everything is so perfect and nice - I dont got words to describe it!" Conclusion
Classifiers, including naive Bayes, are used in many areas besides analyzing opinions: spam filtering, speech recognition, credit scoring, biometric identification, etc.
In addition to the naive Bayesian, there are many other classifiers: perceptrons, decision trees, classifiers based on the support vector method (SVM), nuclear classifiers (kernel classifiers), etc. But besides learning with a teacher, there is also learning without a teacher, reinforcement learning (reinforcement learning), learning to rank, and much more ... but that is another story
This article was written as part of the Technopark @ Mail.Ru student article competition.
Source: https://habr.com/ru/post/146903/
All Articles