ABBYY FlexiCapture Engine 10.0: we train flexibility with the new tool
 In the range of our products for developers replenishment - the next version of ABBYY FlexiCapture Engine has been released. Let me remind you that this is a product that allows you to embed data entry technology from images (data capture) into user solutions.
In the range of our products for developers replenishment - the next version of ABBYY FlexiCapture Engine has been released. Let me remind you that this is a product that allows you to embed data entry technology from images (data capture) into user solutions.One of the interesting features of the new version was the ability to quickly configure to extract data from documents of simple types. My colleagues have already told Habr readers how this function is implemented in FlexiLayout Studio 10. An API has been added to the new version of the product, which gives full programmatic access to this functionality. In addition, we made an easy-to-use tool (also available as source code) that allows you to tune in to the user's task in just a few minutes (as shown here in this video ) and make a quick working prototype of the solution, without going deep into the subtleties of technology.
This article is written by a developer for developers and will tell you about the possibilities and limitations of this technology - something that you will not find in marketing materials.
')
One of the well-known problems that stand in the way of the wide use of data capture technologies is the high initial investment of time and effort to customize work with the required types of images. Developing an integrator needs to learn how to work with a variety of tools and understand the intricacies of a fairly complex technology, which often does not correspond to its main job profile and previous experience. Only after that he can assemble the simplest prototype of a ready-made solution and evaluate the effectiveness and feasibility of the entire project.
The new toolkit allows you to postpone a deep acquaintance with the technology either at the stage of fine-tuning the ready-made solution before release, or even at version two. It cannot completely replace an advanced tool such as FlexiLayout Studio, but it allows you not to over-work in simple cases or in more complex cases to quickly get a simplified working prototype.
As we already described in this article , the actual data extraction using the API requires only a few lines of code, among which, however, there is this:
// IFlexiCaptureProcessor processor = engine.CreateFlexiCaptureProcessor(); processor.AddDocumentDefinitionFile( sampleFolder + "Invoice_eng.fcdot" ); This single line of code sets up a job for a specific type of document. The file with the FCDOT extension ( F lexi C apture DO cument T emplate) contains a description of the extracted data with constraints imposed, a way to find this data on the image, recognition settings and, optionally, settings for exporting document data.
When working with examples, everything is simple - the required document definition file is attached. However, how to get a similar definition of the document for the current task, just to “touch”, how will it work?
Before the release of the 10-ki, in any case, it was necessary to install the desktop version of FlexiCapture and learn how to work with the document definition editor (for working with documents with a rigid structure with well-defined reference frames), and in most cases even more learn to work with the tool for describing the flexible layout of documents FlexiLayout Studio. At the same time, you would hardly have been able to create even the simplest working version of a “gathering” - you almost certainly would have to thoughtfully read the documentation for both tools or take a course.
What now? Now we have a simple example, the Automatic Template Generation tool, made in the form of a wizard that will help you get a satisfactory working prototype in a few minutes. Let's look at an example of how this works.
Task
 Suppose we want to write an application for registering checks in some accounting system and we have a pack of scanned checks. We will select the same type checks from this pack and try to make a prototype of the document definition (document template) for our application.
Suppose we want to write an application for registering checks in some accounting system and we have a pack of scanned checks. We will select the same type checks from this pack and try to make a prototype of the document definition (document template) for our application.I will tell you in advance about the possibilities and limitations:
• we can not make a universal template that works well with arbitrary checks - our template will work well with more or less of the same type of checks, preferably from one source
• in the current version we will not be able to describe complex structures of the type of tables; for such things you need to study FlexiLayout Studio
• but we can completely extract such “flat” data as number, date, amount , etc.
Decision
So, let's begin. First we need a daddy with several (3-5 pcs.) Images of the type of interest to us. This will be the training images folder. At this stage, we would like good-quality images so that there is no excessive “noise” in the data and the pattern would match the case with perfect recognition.
1. Run the wizard and specify the path to our folder:

2. Choose a language:

3. “Draw” the extracted fields and give them the names:
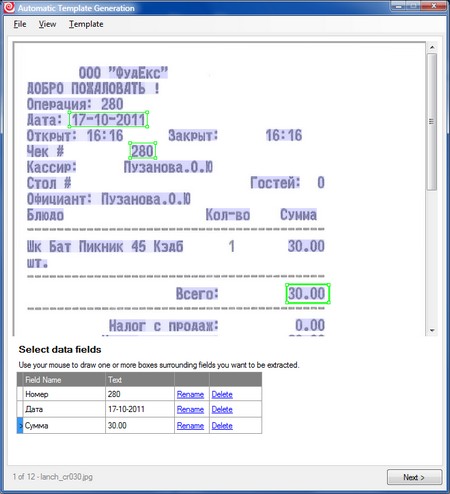
4. Now we need to draw reference elements. This is the only not quite trivial step in the whole process. Supporting elements are a few selected static (that is, permanent) objects in the image (usually text) for which fields with variable content are searched. Usually, as in our example (see screenshot), field names are good candidates for supporting elements.
Mistress note
Nb. The reference element does not have to be in each field. This may be one permanent line on a small document, relative to which the fields are fairly rigid. There should not be too many supporting elements so as not to cause unnecessary confusion. The text of the support element can change, the main thing is that the semantics be preserved: in our case, instead of “Total:”, on some checks there could be “Total:” - in the process of learning it would be necessary to simply indicate once that this is the same thing. It is important that the text is unique - for example, if “Total” and “Total with VAT” are simultaneously present on the document, then the separate word “Total” will be a poor support.
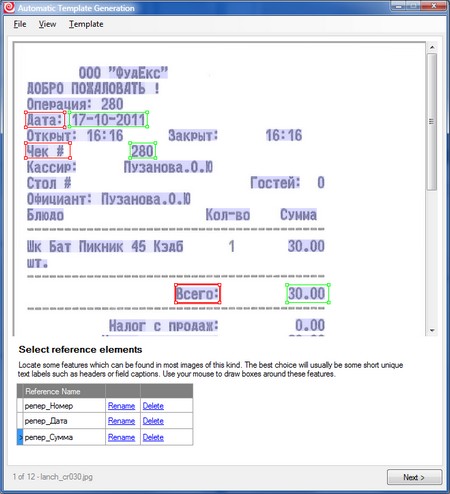
5. Next we sequentially go through all the images in our training package and check the markup. The system for each image offers a variant of the markup, which is obtained from the results of training on the already proven images. Our task is to correct the errors: correct the geometry of the fields, draw the missing ones, delete the extra ones. In our case, there are no errors in the overlay after the first picture, but there are minor problems with recognition.
Mistress note
Nb. Problems with recognition happen due to the fact that we use the default recognition parameters where we could refine them (for example, set the font type - dot matrix printer and limit the possible alphabet or set a regular expression for some fields). In the API, this possibility is already now, but in the considered tool there is no such functionality yet.
Nb. Some field may be missing in some images.
Nb. Through the menu Template \ Modify Language and Fields, you can return to editing the language and fields at any time if you have forgotten something.
Nb. Some field may be missing in some images.
Nb. Through the menu Template \ Modify Language and Fields, you can return to editing the language and fields at any time if you have forgotten something.

6. After we have completed training on selected images, it is suggested to check the resulting template. We answer “yes” and select as a test folder where all the images of the desired type that we have are located.
Consistently for each image from the folder we are offered the results of the overlay. Our task is to click Succeeded or Failed to collect statistics. If the template is not superimposed on some image, and the image looks quite normal, we can add it to the test package by clicking the Add current image to the training batch button. After the test is completed, it will be possible to “learn from the added pictures” and, thus, consistently improve the template.
Mistress note
Nb. At this stage, you can mix in the package for training images of lower quality, to take into account common errors. The main thing is not to overdo it.
Nb. You can stop working with the application at any time. When you restart, you can continue from where you left off. Moreover, we can always return to our “project” if in a week or a month we have new images in which we want to improve our work.
Nb. You can stop working with the application at any time. When you restart, you can continue from where you left off. Moreover, we can always return to our “project” if in a week or a month we have new images in which we want to improve our work.

7. After we are satisfied with the result, the last thing left for us to do is export the resulting template to the FCDOT file, which is how it all started, and go back to writing the code for our application.

Result
As a result, we received a pattern that superimposes very well on our images (with a quality higher than 90), but there are some problems in recognizing fields, since the font features and data types of the fields (date, number, etc.) are not taken into account. For the prototype, it is quite good.
Once again, the tool described does not claim to be universal. If versatility is needed, you will have to learn how to use FlexiLayout Studio and the language of flexible descriptions. But for really simple tasks like “extract a few fields”, it works quite well and allows you to get a working solution faster and easier.
About API
The described tool is written entirely on the public API, comes with source codes, and our customers can modify it to fit their needs or use as a base for making tools for end users. Such functionality may be useful for end users in order to be able to quickly set up the system for new documents.
The work of the example at the level of API calls looks like this (see further comments):
SCENARIO 1 - LINEAR. GOING PREDICTABLE FROM START TO END. EASIER FOR UNDERSTANDING
Code
// ITrainingBatch trainingBatch = engine.CreateTrainingBatch( rootFolder, "_TrainingBatch", "English" ); try { trainingBatch.AddImageFile( rootFolder + "\\00.jpg" ); trainingBatch.AddImageFile( rootFolder + "\\01.jpg" ); // ITrainingPage firstPage = trainingBatch.Pages[0]; // . // ( UI ) firstPage.PrepareLayout(); // “” . for( int j = 0; j < firstPage.ImageObjects.Count; j++ ) { ITrainingImageObject obj = firstPage.ImageObjects[j]; string text = obj.RecognizedText; // “” if( text == "978-1-4095-3439-6" ) { // “” ITrainingField isbnField = trainingBatch.Definition.Fields.AddNew( "ISBN", TrainingFieldTypeEnum.TFT_Field ); firstPage.SetFieldBlock( isbnField, obj.Region ); break; } } for( int j = 0; j < firstPage.ImageObjects.Count; j++ ) { ITrainingImageObject obj = firstPage.ImageObjects[j]; string text = obj.RecognizedText; // “” if( text == "ISBN" ) { // “” ITrainingField isbnTag = trainingBatch.Definition.Fields.AddNew( "ISBNTag", TrainingFieldTypeEnum.TFT_ReferenceText ); firstPage.SetFieldBlock( isbnTag, obj.Region ); break; } } assert( trainingBatch.Definition.Fields.Count == 2 ); // trainingBatch.SubmitPageForTraining( firstPage ); // for( int i = 1; i < trainingBatch.Pages.Count; i++ ) { ITrainingPage page = trainingBatch.Pages[i]; // , page.PrepareLayout(); // trainingBatch.SubmitPageForTraining( page ); } // . CreateDocumentDefinitionFromAFL trainingBatch.Definition.ExportToAFL( rootFolder + "\\_TrainingBatch\\NewTemplate.afl" ); } finally { trainingBatch.Close(); } SCENARIO 2 - NONLINEAR. THE USER LITERATING THROUGH THE PAGES AND MAY CHANGE THE DESCRIPTION TO ANY MOMEN. CONVENIENT FOR USER
Code
// ITrainingBatch trainingBatch = engine.CreateTrainingBatch( rootFolder, "_TrainingBatch", "English" ); try { trainingBatch.AddImageFile( rootFolder + "\\00.jpg" ); trainingBatch.AddImageFile( rootFolder + "\\01.jpg" ); // , ITrainingPage page = trainingBatch.PrepareNextPageNotSubmittedForTraining(); while( page != null ) { // , . // , if( page == trainingBatch.Pages[0] ) { for( int j = 0; j < page.ImageObjects.Count; j++ ) { TrainingImageObject obj = page.ImageObjects[j]; string text = obj.RecognizedText; // “” if( text == "978-1-4095-3439-6" ) { // “” ITrainingField isbnField = trainingBatch.Definition.Fields.AddNew( "ISBN", TrainingFieldTypeEnum.TFT_Field ); page.SetFieldBlock( isbnField, obj.Region ); break; } } for( int j = 0; j < page.ImageObjects.Count; j++ ) { ITrainingImageObject obj = page.ImageObjects[j]; string text = obj.RecognizedText; // “” if( text == "ISBN" ) { // “” ITrainingField isbnTag = trainingBatch.Definition.Fields.AddNew( "ISBNTag", TrainingFieldTypeEnum.TFT_ReferenceText ); page.SetFieldBlock( isbnTag, obj.Region ); break; } } assert( trainingBatch.Definition.Fields.Count == 2 ); } // trainingBatch.SubmitPageForTraining( page ); // page = trainingBatch.PrepareNextPageNotSubmittedForTraining(); } // . CreateDocumentDefinitionFromAFL trainingBatch.Definition.ExportToAFL( rootFolder + "\\_TrainingBatch\\NewTemplate.afl" ); } finally { trainingBatch.Close(); } Finally
In addition to the described from the new features interesting to developers, we now have:
• Advanced image preprocessing tools . Among them, advanced noise control and customizable filter operating in the frequency domain, like wavelets. After adjustment, this filter can significantly improve the quality of work with photos (light defocusing, noise).
• API to access word and character recognition options . This allows, in some cases, when the model of extracted data is well known, to programmatically select the option that best suits this model and improve the quality of the output. For example, you can meaningfully compare with the data contained in a certain database, or read the checksum.
• According to the comments of readers Habra! Decent Java support - the distribution includes a JAR containing the structure of objects and interfaces (repeating the interfaces as they appear from .Net), and a dll with all the necessary JNI adapters for calls. For 99% of cases, you can use it straight out of the box. There is no only support for callbacks that users can selectively implement themselves when strongly needed (we will tell you how).
You can read more about ABBYY FlexiCapture Engine on the ABBYY website .
Aleksey Kalyuzhny AlekseyKa
Head of FlexiCapture Engine Development Group
Source: https://habr.com/ru/post/146679/
All Articles