MySQL Master-Master Operating Experience - How to Survive a Data Center Accident
Hello!
Today we will talk about for which tasks the MySQL Master-Master replication is really useful, for which it is completely useless and harmful, what myths and delusions are associated with it and what practical benefits you can quickly get from this technology. I will give specific examples of customization and architecture schemes.
It is fashionable to talk about the MySQL Master-Master replication - in the context of high availability and performance - but, unfortunately, many do not understand its essence and the serious limitations associated with technology.
Let's start with the fact that in the classic MySQL “real” Master-Master replication - not yet :-) But if you try, you can still simply and quickly set up an effective survival scheme for one data center and get your share of happiness.

')
It is known that to set the Master-Master, you need to set the offset ID and set a unique identifier for each server:
The procedure is described in detail in the network, it is done simply and quickly ... But it is only at first everything is simple. In fact, many corpses, surprises and pitfalls await us on the road to success :-)
Bottom line: you have configured MySQL Master-Master on two servers yourself and are ready to investigate further.

You need to clearly understand once and for all that classic MySQL replication is asynchronous (version 5.6 has added support for FLOOR-synchronous replication; FLOOR is allocated because it remains not completely synchronous until now).
To hell with the theory, let's see how we face replication asynchrony. Data between databases are transmitted with an arbitrary delay (from milliseconds to days). For the Master-Slave architecture with Slave, it is possible for an application to simply not read data that is behind for, say, 30 seconds. But for the Master-Master everything is worse - we do not have and will not (even in the case of SEMI- synchronous replication) any guarantees that the copies of the database are synchronous. Those. the same query can be executed differently on each of the databases. And simultaneous execution of commands:
also lead to data out of sync in both databases (forgive us Codd and Data ).
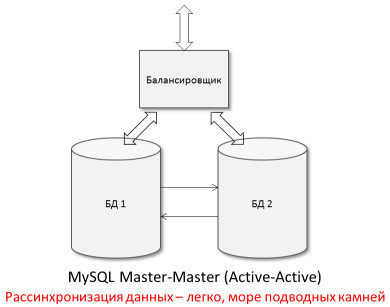
Simultaneous insertion into both databases of the same unique column value (not auto-increment!) Will cause replication to be stopped by mistake. There are many such "creepy" examples.
And although it is sometimes advised to make decisions like “ON DUPLICATE KEY UPDATE”, ignoring errors, etc., and at the same time shovel the application — common sense dictates that such approaches are slippery and unreliable.
I think, obviously, to what kind of collapse and inconsistency this can lead your application.
The bottom line: using an asynchronous Master-Master to simultaneously write to both DBs without knowing the pitfalls is dangerous and unreliable and is used in rare cases.

It is technically possible to merge the MySQL server into a ring. However, the aforementioned problems become even more acute - non-determinism is added that is associated with the distribution of the record around the ring: you can perform the update simultaneously on 1 and 3 nodes, and in passing, on 2 nodes. What comes out of it on each node is scary to think. And to support such a replication economy is “sheer pleasure,” a nightmare for the system administrator.
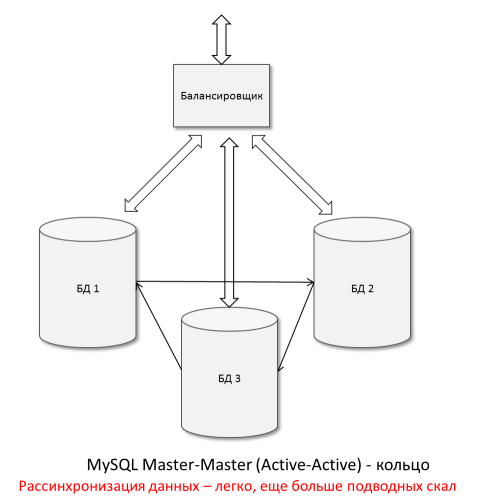
Now, in the context of the present synchronous Master-Master replication (when data integrity is guaranteed and you can write simultaneously to all the nodes of the cluster) they talk a lot about Galera . Someone will say that for this you can try to use the long-known MySQL NDB Cluster - but it is widely known that this “gyro” is suitable for a very narrow circle of applications, rarely from the world of the web.
We are following Galera with interest - it will be possible to build genuine Master-Master clusters on it in the future, but for now let's see what can be gained from existing well-tested stable tools.

However, everything is not so sad. No matter how they scold the classic MySQL Master-Slave replication for:
This "workhorse" is used very widely and brings a lot of benefits and happiness to system administrators:
Asynchronous Master-Master replication can be quickly turned into a “useful horse”. Usually this architecture is called Master-Master (Active-Passive):
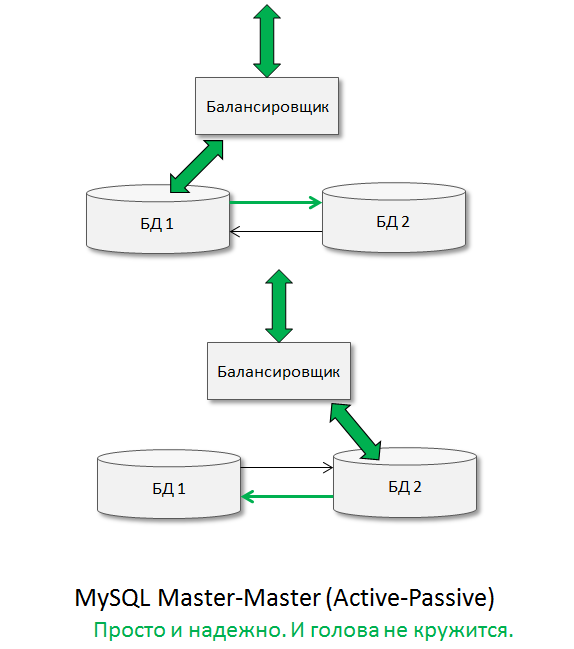
The ideas are simple: we write to one database, the second is used as a hot backup, in which you can, if necessary, QUICKLY START WRITING DATA! It is “quickly begin to write data” that gives this architecture such utility and HighAvailability -ness.

Having a little smoked and thinking, you can see another remarkable application of this “workhorse” - the ability to withstand an accident in a local data center. You just need to keep a hot database in Master-Master (Active-Passive) in another data center, you can on another continent:
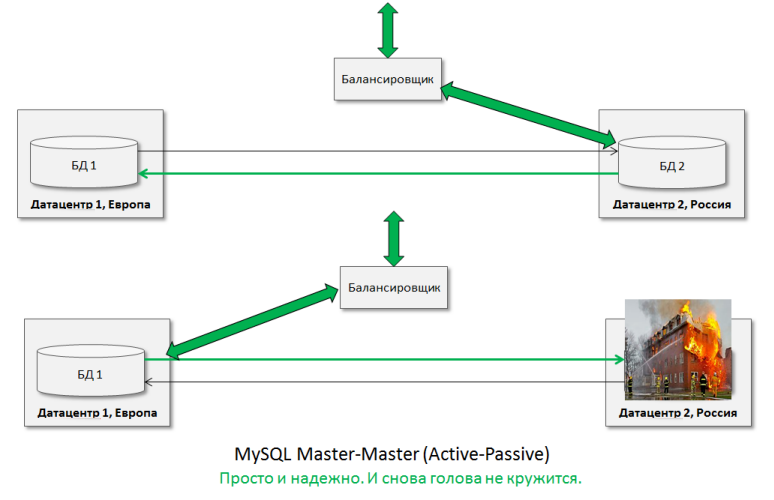
Yes, I see, the arrow to the burning data center is no longer needed, but we will leave for the integrity of the perception of the picture :-)
Well, then no one prohibits us from scaling reads on this architecture, having obtained a cluster local relative to the data center:
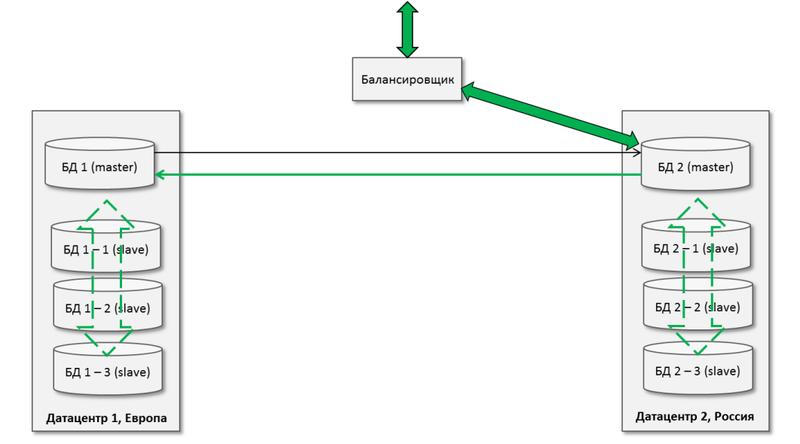
Just do not forget to enable the option of logging updates on the master for subordinate servers .
Honestly, this replication scheme works quite reliably and we successfully use it on Bitrix24 in the Amazon cloud and in the Geographic Web Cluster solution. The features of its operation are the following:

Forgot about the synchronization of content between the DC. Here everything is basically standard:
Cloud storage for spheres of files - Clodo.ru , Selectel.ru , Amazon S3, Google Storage and others. Intensive use of CDN. Transfer of statics between DC through csync2, rsync and other similar tools. Usually there is no problem.
You should look at the linux-ha project and, apparently, make it easier on bash ;-) Galera looks very promising. Let's also hope that MySQL will finally do the “real” Master-Master replication, which is so much in demand today.
And of course, I completely forgot - the data can still be desynchronized between the Master-Master (Active-Passive). This is due to the collapse of mysql, a sudden reboot of the server, loss of replication position, errors in its code. It's okay, there is a cure - more complicated:
and simpler than the type of this simple bash script (do not use on large tables):
At the Bitrix24 project, we intensively use the described technology - and this helped us out more than once. The last fall of the data center in Amazon on June 15 of this year passed unnoticed by customers - we automatically switched to the backup master in another DC.
In the article, we sorted out the MySQL Master-Master topic so that in the future we don’t look for hidden meaning in this technology. We considered dangerous and poorly described in the network pitfalls. We chose a simple and practical application for the Master-Master (Active-Passive) to provide a hot MySQL Master-server in another data center (on another continent) and now the sysdam can go on vacation without fear that at all replication nodes the data will become different (no longer I mention the names of the fathers of the founders of relational theory) or the lightning will strike the data center :-) Good luck, good mood and reliable replication to everyone!
Today we will talk about for which tasks the MySQL Master-Master replication is really useful, for which it is completely useless and harmful, what myths and delusions are associated with it and what practical benefits you can quickly get from this technology. I will give specific examples of customization and architecture schemes.
It is fashionable to talk about the MySQL Master-Master replication - in the context of high availability and performance - but, unfortunately, many do not understand its essence and the serious limitations associated with technology.
Let's start with the fact that in the classic MySQL “real” Master-Master replication - not yet :-) But if you try, you can still simply and quickly set up an effective survival scheme for one data center and get your share of happiness.
')
Setup Master-Master
It is known that to set the Master-Master, you need to set the offset ID and set a unique identifier for each server:
- dev.mysql.com/doc/refman/5.5/en/replication-options-master.html#sysvar_auto_increment_increment
- dev.mysql.com/doc/refman/5.5/en/replication-options-master.html#sysvar_auto_increment_offset
- dev.mysql.com/doc/refman/5.5/en/replication-options.html#option_mysqld_server-id
The procedure is described in detail in the network, it is done simply and quickly ... But it is only at first everything is simple. In fact, many corpses, surprises and pitfalls await us on the road to success :-)
Bottom line: you have configured MySQL Master-Master on two servers yourself and are ready to investigate further.
Synchronicity
You need to clearly understand once and for all that classic MySQL replication is asynchronous (version 5.6 has added support for FLOOR-synchronous replication; FLOOR is allocated because it remains not completely synchronous until now).
To hell with the theory, let's see how we face replication asynchrony. Data between databases are transmitted with an arbitrary delay (from milliseconds to days). For the Master-Slave architecture with Slave, it is possible for an application to simply not read data that is behind for, say, 30 seconds. But for the Master-Master everything is worse - we do not have and will not (even in the case of SEMI- synchronous replication) any guarantees that the copies of the database are synchronous. Those. the same query can be executed differently on each of the databases. And simultaneous execution of commands:
UPDATE mytable SET mycol=mycol+1; - UPDATE mytable SET mycol=mycol*3; - also lead to data out of sync in both databases (forgive us Codd and Data ).
Simultaneous insertion into both databases of the same unique column value (not auto-increment!) Will cause replication to be stopped by mistake. There are many such "creepy" examples.
And although it is sometimes advised to make decisions like “ON DUPLICATE KEY UPDATE”, ignoring errors, etc., and at the same time shovel the application — common sense dictates that such approaches are slippery and unreliable.
I think, obviously, to what kind of collapse and inconsistency this can lead your application.
The bottom line: using an asynchronous Master-Master to simultaneously write to both DBs without knowing the pitfalls is dangerous and unreliable and is used in rare cases.
Magic ring
It is technically possible to merge the MySQL server into a ring. However, the aforementioned problems become even more acute - non-determinism is added that is associated with the distribution of the record around the ring: you can perform the update simultaneously on 1 and 3 nodes, and in passing, on 2 nodes. What comes out of it on each node is scary to think. And to support such a replication economy is “sheer pleasure,” a nightmare for the system administrator.
MySQL synchronous replication support
Now, in the context of the present synchronous Master-Master replication (when data integrity is guaranteed and you can write simultaneously to all the nodes of the cluster) they talk a lot about Galera . Someone will say that for this you can try to use the long-known MySQL NDB Cluster - but it is widely known that this “gyro” is suitable for a very narrow circle of applications, rarely from the world of the web.
We are following Galera with interest - it will be possible to build genuine Master-Master clusters on it in the future, but for now let's see what can be gained from existing well-tested stable tools.
Benefits of Asynchronous MySQL Master-Master Replication
However, everything is not so sad. No matter how they scold the classic MySQL Master-Slave replication for:
- asynchrony (desync data on nodes, backlog ...)
- insufficient reliability (flush_log_at_trx_commit = 1, sync_binlog = 1, sync_relay_log = 1, sync_relay_log_info = 1, sync_master_info = 1, - sometimes not enough, and replication during server restart falls off)
- insufficient transactional support (thanks to the Percona Server patch in which this feature is implemented)
This "workhorse" is used very widely and brings a lot of benefits and happiness to system administrators:
- to create hot "almost" current backup
- for clustering reads from MySQL slaves
- for vertical sharding (filter which tables to transfer to which slaves)
- in order to safely back up the Slave server using mysqldump, without loading the combat database server
- and etc.
Asynchronous Master-Master replication can be quickly turned into a “useful horse”. Usually this architecture is called Master-Master (Active-Passive):
The ideas are simple: we write to one database, the second is used as a hot backup, in which you can, if necessary, QUICKLY START WRITING DATA! It is “quickly begin to write data” that gives this architecture such utility and HighAvailability -ness.
Having smoked a little ...
Having a little smoked and thinking, you can see another remarkable application of this “workhorse” - the ability to withstand an accident in a local data center. You just need to keep a hot database in Master-Master (Active-Passive) in another data center, you can on another continent:
Yes, I see, the arrow to the burning data center is no longer needed, but we will leave for the integrity of the perception of the picture :-)
Well, then no one prohibits us from scaling reads on this architecture, having obtained a cluster local relative to the data center:
Just do not forget to enable the option of logging updates on the master for subordinate servers .
Risks
Honestly, this replication scheme works quite reliably and we successfully use it on Bitrix24 in the Amazon cloud and in the Geographic Web Cluster solution. The features of its operation are the following:
- Start operation in statement-based replication mode. If there are messages in the MySQL log that it is dangerous to perform this query in this mode, because The order of its execution on the Slave may be different - turn on the replication mode “mixed” (this may require increasing the isolation mode of transactions in InnoDB to Repeatable Read ). I do not recommend including row-based.
- If you are worried about performance, then most likely you will not include parameters: flush_log_at_trx_commit = 1, sync_binlog = 1, sync_relay_log = 1, sync_relay_log_info = 1, sync_master_info = 1 (sarcasm :-)). So sometimes you will have to manually increase replication from the last position after MySQL emergency restarts - smoke with the mysqlbinlog command, you can find a lot of interesting and useful information.
- Try not to lift the replication on the one hand not to switch back the balancer - otherwise the porridge with data may begin (and the second time Codd and Date can no longer be forgiven :-)).
"And compote?"
Forgot about the synchronization of content between the DC. Here everything is basically standard:
Cloud storage for spheres of files - Clodo.ru , Selectel.ru , Amazon S3, Google Storage and others. Intensive use of CDN. Transfer of statics between DC through csync2, rsync and other similar tools. Usually there is no problem.
What to read on this topic
You should look at the linux-ha project and, apparently, make it easier on bash ;-) Galera looks very promising. Let's also hope that MySQL will finally do the “real” Master-Master replication, which is so much in demand today.
And of course, I completely forgot - the data can still be desynchronized between the Master-Master (Active-Passive). This is due to the collapse of mysql, a sudden reboot of the server, loss of replication position, errors in its code. It's okay, there is a cure - more complicated:
and simpler than the type of this simple bash script (do not use on large tables):
#!/bin/bash DATABASES=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -B -N -e"SHOW DATABASES" | grep -vE '(^binlogs$)|(^performance_schema$)|(^test.*$)|(^information_schema$)'` for DB in $DATABASES; do TABLES=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -B -N -D $DB -e"SHOW TABLES" for TABLE in $TABLES; do CS_L=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -D $DB -B -N -e"CHECKSUM TABLE $TABLE" | awk '{print $2}'` CS_R=`mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_R -D $DB -B -N -e"CHECKSUM TABLE $TABLE" | awk '{print $2}'` if [ "$CS_L" != "$CS_R" ]; then echo "${DB}-${TABLE} : DIFF" mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_L -D $DB -B -N -e"SELECT * FROM $TABLE" > /var/tmp_data/table_diff_${SHARD_L}.tmp mysql -u root -p${MYSQL_ROOT_PASSWORD} -h $SHARD_R -D $DB -B -N -e"SELECT * FROM $TABLE" > /var/tmp_data/table_diff_${SHARD_R}.tmp diff -u /var/tmp_data/table_diff_${SHARD_L}.tmp /var/tmp_data/table_diff_${SHARD_R}.tmp rm -f /var/tmp_data/table_diff_${SHARD_L}.tmp /var/tmp_data/table_diff_${SHARD_R}.tmp else echo "${DB}-${TABLE} : OK" fi done done Results
At the Bitrix24 project, we intensively use the described technology - and this helped us out more than once. The last fall of the data center in Amazon on June 15 of this year passed unnoticed by customers - we automatically switched to the backup master in another DC.
In the article, we sorted out the MySQL Master-Master topic so that in the future we don’t look for hidden meaning in this technology. We considered dangerous and poorly described in the network pitfalls. We chose a simple and practical application for the Master-Master (Active-Passive) to provide a hot MySQL Master-server in another data center (on another continent) and now the sysdam can go on vacation without fear that at all replication nodes the data will become different (no longer I mention the names of the fathers of the founders of relational theory) or the lightning will strike the data center :-) Good luck, good mood and reliable replication to everyone!
Source: https://habr.com/ru/post/146490/
All Articles