We get lost articles from network storages
The solution is considered (for now) only for one site - the one on which we are located. The idea came as a result of the fact that one user made a user script that redirects the page to the Google cache, if instead of the article we see “Publication access is closed”. It is clear that this solution will work only partially, but there is no complete solution yet. You can increase the probability of finding a copy by choosing a result from several services. The HabrAjax script (along with dozens of other functions) has become involved in this. Now (from version 0.859), if the user has seen a half-empty page, from which you can go only to the main page, to the personal page of the author (if you are lucky) and back, user scripts provide several alternative links where you can try to find a loss. And here the most interesting begins, because not a single service is focused on high-quality archiving of a single site.
By the way, the article and the research are generated by an interesting survey. Does the annoying “Access to publication closed” annoy you? and dotneter user script - comment habrahabr.ru/post/146070/#comment_4914947 .
Of course, a better service is required, therefore, in addition to describing the current modest functionality (the probability of being found in the Google Cache and on several copying sites), we will raise in the article crowdsourcing issues - in order for the “whole world” to solve the problem more, the solution seems close to those who have a content copying service. But let's get everything in order, consider all the solutions proposed at the moment.
Unlike the Yandex cache, it has direct access to the link, no need to ask the user "then press the" copy "button. However, all cachers, like the well-known archive.org, have a number of unnecessary features.
')
1) they simply do not have time to instantly and repeatedly copy the links that appear. Although it is necessary to pay tribute to the fact that they frequently refer to popular sites, and for 2 hours or more they cache new pages. Everyone in their own time.
2) further, there is such a ridiculous feature that they can later cache a blank page saying that “access is denied”.
3) therefore, the result of caching is as lucky. You can bypass all such caching links, if you really need to, but from there you should copy the information yourself, because it may soon disappear or be replaced with a “more relevant” meaningless copy of a blank page.
It works on the entire Internet with capacities smaller than those of search engines, so it rarely bypasses the pages of some distant Russian-language site. The frequency can be seen here: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
And the purpose of the site is to capture fragments of the history of the web, and not all the events on each site. Therefore, we will rarely get to useful information.
There is no direct link, so you need to ask the (simplest) user to click on the “copy” link on the search page, which will have this article alone (if Yandex has seen it at all).
As experience shows, the article, hung a couple of hours and closed by the author, is quite successfully stored in search engine caches. Subsequently, most likely, rather quickly replaced by empty. All this, of course, does not suit the users of the web, which, by definition, must store information that has entered it.
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 and others.
Quite an interesting decision. Those who can customize them will probably fully solve the problem of archiving RSS. From the existing one, I did not find the payp with the search for the article by its number, so there is not yet a direct link to such saved full articles. (Who knows how to work with him - please make such a link for the script.)
All of them suffer because they do not link to the article by its number, do not cite the full text of the article, and some are generally limited to “zahabrenny” or “so lazy” that they rarely copy (for example, once a day), which is not relevant is always. However, if at least one copywriter author tweaks the engine to preserve high-grade and relevant content, he will provide an invaluable service to the Internet, and his service will take the main place in the HabrAjax script.
From living I have found so far 4, some long-existing (itgator) at the moment did not work. In general, for now they are almost useless, because they force you to search for an article by title or keywords, and not by the address at which the user came to a closed page (and according to the words, he is perfectly looking for Yandex and not just one of their sites). Given in the script for some useful information.
The community faces the challenge, without troubling the site organizers, to bring the product to a quality resource that does not lose information. To do this, as correctly noted in the comments to the survey, you need an archiver of current full-fledged articles (and comments to them at the same time).
Currently, its incomplete solution, as described above, looks like this:
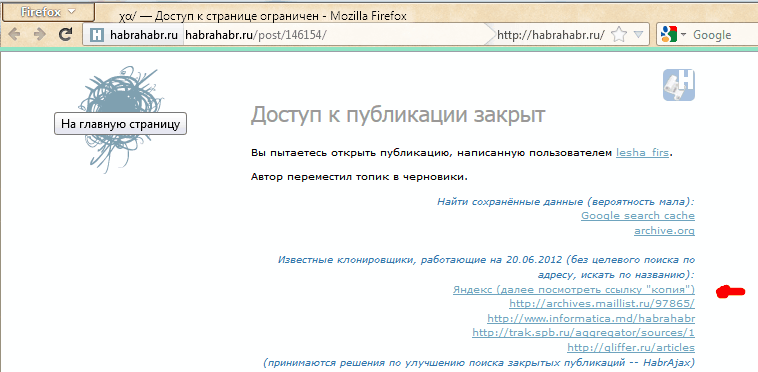
If you search in Yandex, the selected address will display a single link (or nothing):

Clicking the “copy” link, we will see (if lucky) the saved copy (the page is selected only for the currently relevant example):
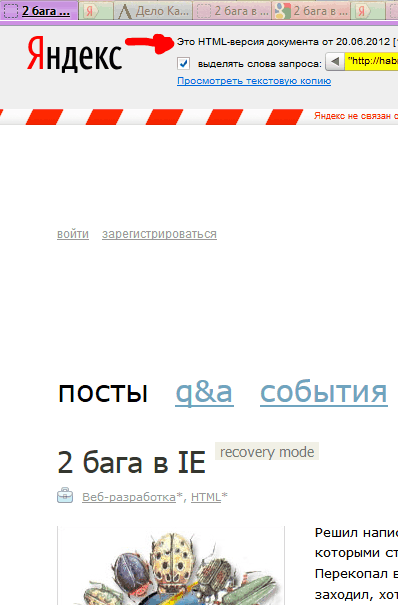
In Google it is somewhat simpler - we immediately get to the copy, if we are also lucky, and Google managed to save exactly what we need, and not double the missing page.
It's funny that the script now offers “a choice of alternative services” in this case (“maintenance”):

I am waiting for proposals for adding services and copyists (or at least projects) (for unauthorized ones, send mail to spmbt0 on a known Google resource, then choose a convenient format).
UPD 23:00: by practical experience for mail.ru , the structure of the direct link to the cache was found:
Added links of mail and VC to the script update (habrAjax) (0.861), now there are 2 lines more.
By the way, the article and the research are generated by an interesting survey. Does the annoying “Access to publication closed” annoy you? and dotneter user script - comment habrahabr.ru/post/146070/#comment_4914947 .
Of course, a better service is required, therefore, in addition to describing the current modest functionality (the probability of being found in the Google Cache and on several copying sites), we will raise in the article crowdsourcing issues - in order for the “whole world” to solve the problem more, the solution seems close to those who have a content copying service. But let's get everything in order, consider all the solutions proposed at the moment.
Kesh google
Unlike the Yandex cache, it has direct access to the link, no need to ask the user "then press the" copy "button. However, all cachers, like the well-known archive.org, have a number of unnecessary features.
')
1) they simply do not have time to instantly and repeatedly copy the links that appear. Although it is necessary to pay tribute to the fact that they frequently refer to popular sites, and for 2 hours or more they cache new pages. Everyone in their own time.
2) further, there is such a ridiculous feature that they can later cache a blank page saying that “access is denied”.
3) therefore, the result of caching is as lucky. You can bypass all such caching links, if you really need to, but from there you should copy the information yourself, because it may soon disappear or be replaced with a “more relevant” meaningless copy of a blank page.
Archive archive.org
It works on the entire Internet with capacities smaller than those of search engines, so it rarely bypasses the pages of some distant Russian-language site. The frequency can be seen here: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
And the purpose of the site is to capture fragments of the history of the web, and not all the events on each site. Therefore, we will rarely get to useful information.
Cash Yandex
There is no direct link, so you need to ask the (simplest) user to click on the “copy” link on the search page, which will have this article alone (if Yandex has seen it at all).
As experience shows, the article, hung a couple of hours and closed by the author, is quite successfully stored in search engine caches. Subsequently, most likely, rather quickly replaced by empty. All this, of course, does not suit the users of the web, which, by definition, must store information that has entered it.
Yahoo pipes
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 and others.
Quite an interesting decision. Those who can customize them will probably fully solve the problem of archiving RSS. From the existing one, I did not find the payp with the search for the article by its number, so there is not yet a direct link to such saved full articles. (Who knows how to work with him - please make such a link for the script.)
Numerous cloners
All of them suffer because they do not link to the article by its number, do not cite the full text of the article, and some are generally limited to “zahabrenny” or “so lazy” that they rarely copy (for example, once a day), which is not relevant is always. However, if at least one copywriter author tweaks the engine to preserve high-grade and relevant content, he will provide an invaluable service to the Internet, and his service will take the main place in the HabrAjax script.
From living I have found so far 4, some long-existing (itgator) at the moment did not work. In general, for now they are almost useless, because they force you to search for an article by title or keywords, and not by the address at which the user came to a closed page (and according to the words, he is perfectly looking for Yandex and not just one of their sites). Given in the script for some useful information.
Task
The community faces the challenge, without troubling the site organizers, to bring the product to a quality resource that does not lose information. To do this, as correctly noted in the comments to the survey, you need an archiver of current full-fledged articles (and comments to them at the same time).
Currently, its incomplete solution, as described above, looks like this:
If you search in Yandex, the selected address will display a single link (or nothing):
Clicking the “copy” link, we will see (if lucky) the saved copy (the page is selected only for the currently relevant example):
In Google it is somewhat simpler - we immediately get to the copy, if we are also lucky, and Google managed to save exactly what we need, and not double the missing page.
It's funny that the script now offers “a choice of alternative services” in this case (“maintenance”):
I am waiting for proposals for adding services and copyists (or at least projects) (for unauthorized ones, send mail to spmbt0 on a known Google resource, then choose a convenient format).
UPD 23:00: by practical experience for mail.ru , the structure of the direct link to the cache was found:
'http://hl.mailru.su/gcached?q=cache:'+ window.location Added links of mail and VC to the script update (habrAjax) (0.861), now there are 2 lines more.
Source: https://habr.com/ru/post/146200/
All Articles