Password Generator / Validator for LinkedIn Hacking
 After analyzing the selected passwords for LinkedIn , the idea to create a password generator combined with a validator that prevents easily matching passwords appeared. A simple analysis of the length, the presence of special characters is not enough here - some passwords can be easily assembled from very likely “pieces” and their search takes much less time than theoretically stated. And there is no guarantee that the generator program will not give you such a password - it is an accident, it’s an accident. My creation does not pretend to a complete solution of the issue, rather it is a reason for reflection, but it is quite workable (source codes and a little analysis are also present).
After analyzing the selected passwords for LinkedIn , the idea to create a password generator combined with a validator that prevents easily matching passwords appeared. A simple analysis of the length, the presence of special characters is not enough here - some passwords can be easily assembled from very likely “pieces” and their search takes much less time than theoretically stated. And there is no guarantee that the generator program will not give you such a password - it is an accident, it’s an accident. My creation does not pretend to a complete solution of the issue, rather it is a reason for reflection, but it is quite workable (source codes and a little analysis are also present).Reliability vs trust
Initially I wanted to design the idea as a kind of Web service, but changed my mind; a competent user should first think about where his possible password can go, and for network technologies this question is without an obvious answer, and there are all reasons not to trust such services in general. You just finished entering the password, but with AJAX, it has already been pulled and saved on the server. No, thanks.
Unknown desktop application in this regard is no better, it has many opportunities to quietly send a request to the Internet. It is because of this that I do not use the generator software myself. And despite the huge lists of sources of entropy, there is no guarantee that your password will not be in someone's base.
Therefore, I myself propose a program in source codes (in C #, on the basis of the fact that I did not want to spend more than a couple of hours on development) and I strongly recommend collecting it from source.
')
Password generation
The simplest and most universal generation scheme is to get some entropy and convert it to a string of target length, with a given set of characters.
There is a rather standard solution for the conversion, which comes down to calling the hash function as an effective convolution of the entropy pool (that is, some random values):
string generatePassword(string charset, int length) { byte[] result; SHA1 sha = new SHA1CryptoServiceProvider(); result = sha.ComputeHash(seed); // <--- // create password StringBuilder output = new StringBuilder(); for (int i = 0; i < result.GetLength(0) && output.Length < length; i++) output.Append(charset[result[i] % charset.Length]); // update seed for (int i = 0; i < result.GetLength(0); i++) addToSeed(result[i]); return output.ToString(); } The random values themselves can be typed in different ways:
- hardware solutions
- system environment (values in memory, process properties),
- receiving data from Internet services,
- user interaction.
But I consider the first three points to be completely redundant in the ideal, but in reality also poorly predictable. There is no certainty that the hardware sensor will not break, and will not give out the same thing, the environment of the system may not be dynamic enough, and the Internet service may specifically return (and save) the data generated for personal gain. These are random numbers, and even having the opportunity to look at them, we will not understand anything.
So it was decided to use the data, the process of obtaining which depends on the user, and one of the most simple and convenient options is to save mouse movements. Each movement is characterized by coordinates and time, which, although it has a predictable overall appearance, is always distinguishable and concrete in specific numbers, especially if you measure time with a high resolution counter (in processor ticks).
void handleMouseData(int x, int y) { /* store information in seed array */ addToSeed(x); addToSeed(y); addToSeed(ticks()); } That small part of the code that relates to the formation of entropy from the environment is contained in this simple function:
int ticks() { long timer; if (QueryPerformanceCounter(out timer) == false) { // high-performance counter not supported throw new Win32Exception(); } /* ignore significant bits due its stability - we prefer using fast-changing low bits only */ return (int)timer; } The QueryPerformanceCounter counter has a different resolution depending on the system, and its value changes depending on the current processor load, the number of processes, the fact of the context switch. One quantity, which, although it has a predictable growth, is very difficult to express in specific numbers.
As a result, we get good passwords without forcing the user to press some tricky combinations, wait for hours for the generation to finish, and suffer with a complex program interface. I do not pretend to be neat in the design of the interfaces (even it became ridiculous after realizing the screenshot below), but I suppose that there is no more convenient solution than to stick in the ComboBox and choose the one you like from the generated ones.
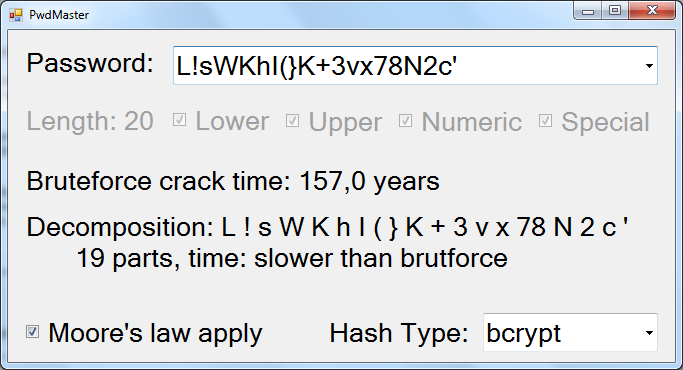
Estimate of time for hacking
For a direct search, the total time can be calculated based on the following parameters:
- check speed,
- power of the alphabet
- Characters.
The power of the alphabet is the minimum (with a reasonable description criterion) a set containing characters of a specific password. As a rule, these are sets of the form:
- small letters,
- capital letters,
- numbers,
- special marks.
Therefore, to calculate the time, we simply check the characters from which sets our password contains, and include in the power of the set all the characters in the set:
double bruteforceCombinations = Math.Pow(26 * upper + 26 * lower + 10 * numeric + specials.Length * special, pwd.Length); The hash rate varies for different algorithms, I provide a list with roughly estimated values for popular methods (but in reality we do not know which one is used on the server, so it would be more correct to leave only the fastest algorithm that is popular, now it is MD5).
And do not forget about the law of Moore , why all the calculations claiming "millions of years of hacking" seem very naive. Although the growth dynamics of computing power cannot be predicted for sure, but using the current growth rate is better than nothing at all.
And now, in fact, the main thing is to estimate the attack time by decomposition .
It is not so difficult, you just need to calculate the minimum splitting of our password into words of some dictionary of relevant combinations (fairly frequent substrings) == password length. And calculate the "power" of the dictionary == the number of words in it. The total number of combinations is still “power” to the degree of length.
If our password is “Good123 Password”, then it decomposes into “Good”, “123”, “Password”, which are very common separately and the time required to go through just “very little” in a cube.
The question, of course, is the quality of such a dictionary, but again, any option is better than nothing. I attached to the program a dictionary obtained after an audit on LinkedIn, made up of the most frequent combinations found in 2.5 million passwords found. Dictionary itself - only 40 kilobytes.
results
Link to the program and source code: dl.dropbox.com/u/243445/md5h/pwdmaster.zip
One of the pleasant results is the fact that most of the pseudo-randomly generated passwords are not decomposed into plausible combinations. If there are no obvious errors or “loopholes” in other generators, and they are no worse than mine in terms of generation quality, then “you can sleep in peace”. The share of passwords for 14-character alphanumeric combinations, decomposed by a dictionary (so that a dictionary is faster than a direct search) is less than one thousandth of a percent.
Source: https://habr.com/ru/post/146068/
All Articles