Java: Compression Algorithm Testing - 16 files, 5 types
Hello "HabraCommunity"!
I post a small review and test results of basic compression algorithms with Java.
To whom it is interesting to ask for a cat, who does not - please do not minus and say that the topic is not worthy of Habr - I will remove it in drafts.
So:
Steria.LZH 100
java.util.zip.GZIP (stream) 1000
java.util.zip.Deflater.BEST_COMPRESSION (block) 1000
java.util.zip.Deflater.BEST_SPEED (block) 1000
java.util.zip.Deflater.HUFFMAN_ONLY (block) 1000
apache.commons.compress.BZIP2 (stream) 10
apache.commons.compress.GZIP (stream) 1000
apache.commons.compress.XZ (stream) 10
com.ning.LZF (block) 1000
com.ning.LZF (stream) 10
QuickLZ (block) 1000
org.xerial.snappy.Snappy (block) 1000
The code is my creation, everyone has their own style. So please RIGHT not to discuss much.
')
TextDat_1Kb.txt - simple text of some Wikipedia article (eng).
TextDat_100Kb.txt - a simple text of some Wikipedia articles (eng).
TextDat_1000Kb.txt - a simple text of some articles from Wikipedia (English, German, Spanish ..).
PdfDat_200Kb.pdf - the same as * .doc is only converted and the size is adjusted.
PdfDat_1000Kb.pdf - the same as * .doc is only converted and the size is adjusted.
PdfDat_2000Kb.pdf - the same as * .doc is only converted and resized.
HtmlDat_10Kb.htm - the text of some documentation without pictures with tags, formatted html.
HtmlDat_100Kb.htm - the text of some documentation without pictures with tags, is formatted html.
HtmlDat_1000Kb.htm - the text of some documentation without pictures with tags, is formatted html.
ExcelDat_200Kb.xls - filled with random numbers from 0 to 1 by the excel function random ().
ExcelDat_1000Kb.xls - filled with random numbers from 0 to 1 by the excel function random ().
ExcelDat_2000Kb.xls - filled with random numbers from 0 to 1 by the excel function random ().
DocDat_500Kb.doc - texts of Wikipedia articles with several drawings (English, German, Spanish ..).
DocDat_1000Kb.doc - Wikipedia articles texts with several drawings (English, German, Spanish ..).
DocDat_2000Kb.doc - Wikipedia articles texts with several drawings (English, German, Spanish ..).
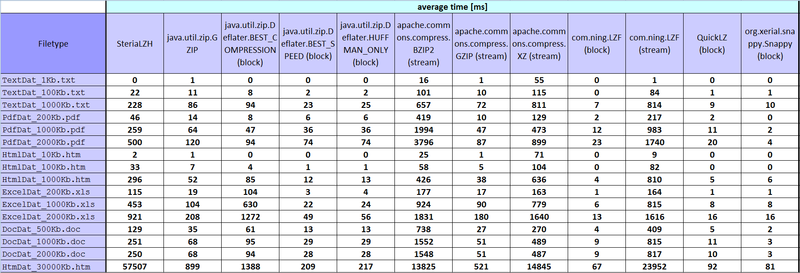
HtmDat_30000Kb.htm - formatted text and tables with numbers.




...
I did it right, not right, - I hope that was right, but I did it! Who has any considerations, ready for criticism! I post it - can someone come in handy.
Some results for me are strange, but such numbers turned out in the end, then I put it in a tablet.
I don’t know if it is possible to gently insert excel-tables, so I throw pictures. If someone needs an excel file, I'll upload it without problems.
PS Thank you for your attention, I am glad that you have read to the end. :)
I post a small review and test results of basic compression algorithms with Java.
To whom it is interesting to ask for a cat, who does not - please do not minus and say that the topic is not worthy of Habr - I will remove it in drafts.
So:
- SteriaLZH is the implementation of the lzh algorithm which is currently relevant in the project the company is working on, and because of what the task appeared to find the best alternative.
- not all found algorithms were tested (implementation of file and data compression). For example, JZip from JCraft, and a few more, everything that I tested can be seen in the tablet.
- only compression was tested, decompression was not tested.
- 5 parameters were calculated during testing: compression rate, min time [ms], average time [ms], median time [ms], max time [ms].
- good compressors chased files 1000 times, not very 10. Below is a sign that what, how much and by what.
- stream - implementation (algorithms): we take the name of the file, then read the file accordingly in the InputStream and create (save) with the help of the OutputStream.
- block - implementation (algorithms): we take the file as byte [], compress it, back we get compressed byte [].
- With streaming compression, compressed files were deleted before being recreated.
- tested on a working machine lenovo thinkpad T420 (Intel Core i5-2540M, CPU 2.6GHz, 4 GR RAM), WinXP: SP3.
The plate that and how many times was banished:
Steria.LZH 100
java.util.zip.GZIP (stream) 1000
java.util.zip.Deflater.BEST_COMPRESSION (block) 1000
java.util.zip.Deflater.BEST_SPEED (block) 1000
java.util.zip.Deflater.HUFFMAN_ONLY (block) 1000
apache.commons.compress.BZIP2 (stream) 10
apache.commons.compress.GZIP (stream) 1000
apache.commons.compress.XZ (stream) 10
com.ning.LZF (block) 1000
com.ning.LZF (stream) 10
QuickLZ (block) 1000
org.xerial.snappy.Snappy (block) 1000
This is how measurements were made.
The code is my creation, everyone has their own style. So please RIGHT not to discuss much.
')
time: for each individual algorithm (implementation) a class with a public function was created which I call passing it as an argument or path to a file or byte [].
start = System.nanoTime(); byte[] compressedArray = compressor.compressing(arrayToCompress); end = System.nanoTime(); resultTime = end - start; start = System.nanoTime(); compressor.compressing(fileToCompress); end = System.nanoTime(); resultTime = end - start; Measurement min time [ms], average time [ms], median time [ms], max time [ms]: ArrayList received all the measured time values of a specific file.
private void minMaxMedianAverCalculation(int element) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); ArrayList<Long> elementsList = new ArrayList<Long>(); for (int i = 0; i < TEST_COUNT; i++) { long timeElement = resultsSaver.getNanoSecondsTime(i, element); elementsList.add(timeElement); } Collections.sort(elementsList); this.min = (elementsList.get(0)) / 1000000; this.max = (elementsList.get(elementsList.size() - 1)) / 1000000; int elementsListLength = elementsList.size(); if (elementsListLength % 2 == 0) { int m1 = (elementsListLength - 1) / 2; int m2 = m1 + 1; this.median = ((elementsList.get(m1) + elementsList.get(m2)) / 2) / 1000000; } else { int m = elementsListLength / 2; this.median = elementsList.get(m) / 1000000; } long totalTime = 0; for (int i = 0; i < elementsListLength; i++) { totalTime += elementsList.get(i); } this.average = (totalTime / TEST_COUNT)/1000000; } Measurement of stream compression rate:
private void setStreamCompressionRatio(String toCompressFileName, String compressedFileName) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); File fileToCompress = new File(toCompressFileName); long fileToCompressSize = fileToCompress.length(); File compressedFile = new File(compressedFileName); long compressedFileSize = compressedFile.length(); double compressPercent = Math.round(((double) compressedFileSize * 100) / fileToCompressSize * 100) / 100.0d; resultsSaver.setCompressionRatio(compressPercent); } Measurement of block compression rate:
private void setBlockCompressionRatio(byte[] arrayToCompress, byte[] compressedArray) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); long arrayToCompressSize = arrayToCompress.length; long compressedArraySize = compressedArray.length; double compressPercent = Math.round(((double) compressedArraySize * 100) / arrayToCompressSize * 100) / 100.0d; resultsSaver.setCompressionRatio(compressPercent); } What compressed:
TextDat_1Kb.txt - simple text of some Wikipedia article (eng).
TextDat_100Kb.txt - a simple text of some Wikipedia articles (eng).
TextDat_1000Kb.txt - a simple text of some articles from Wikipedia (English, German, Spanish ..).
PdfDat_200Kb.pdf - the same as * .doc is only converted and the size is adjusted.
PdfDat_1000Kb.pdf - the same as * .doc is only converted and the size is adjusted.
PdfDat_2000Kb.pdf - the same as * .doc is only converted and resized.
HtmlDat_10Kb.htm - the text of some documentation without pictures with tags, formatted html.
HtmlDat_100Kb.htm - the text of some documentation without pictures with tags, is formatted html.
HtmlDat_1000Kb.htm - the text of some documentation without pictures with tags, is formatted html.
ExcelDat_200Kb.xls - filled with random numbers from 0 to 1 by the excel function random ().
ExcelDat_1000Kb.xls - filled with random numbers from 0 to 1 by the excel function random ().
ExcelDat_2000Kb.xls - filled with random numbers from 0 to 1 by the excel function random ().
DocDat_500Kb.doc - texts of Wikipedia articles with several drawings (English, German, Spanish ..).
DocDat_1000Kb.doc - Wikipedia articles texts with several drawings (English, German, Spanish ..).
DocDat_2000Kb.doc - Wikipedia articles texts with several drawings (English, German, Spanish ..).
HtmDat_30000Kb.htm - formatted text and tables with numbers.
Results, results: habrastorage.org - issued such pictures, full sized 1800 * 615, can anyone know how to make an increase by click?
...
I did it right, not right, - I hope that was right, but I did it! Who has any considerations, ready for criticism! I post it - can someone come in handy.
Some results for me are strange, but such numbers turned out in the end, then I put it in a tablet.
I don’t know if it is possible to gently insert excel-tables, so I throw pictures. If someone needs an excel file, I'll upload it without problems.
PS Thank you for your attention, I am glad that you have read to the end. :)
Source: https://habr.com/ru/post/145712/
All Articles