Object collections in PHP. Part two
Almost 3 weeks have passed since the publication of my first post about object collections in PHP . During this time, a lot of work has been done and a lot of experience has been gained that I want to share. The greatest number of changes have undergone maps, most of the attention will be paid to them.
In this post you will see:
')
After the publication of my last post and the end of his discussion, I made a plan for further development:
In addition to the above list, there were also candidates who were not included in the plan for the current release:
The interfaces of collections developed earlier reacted rather stably to the new development plan. The interface diagram of the current version looks like this:
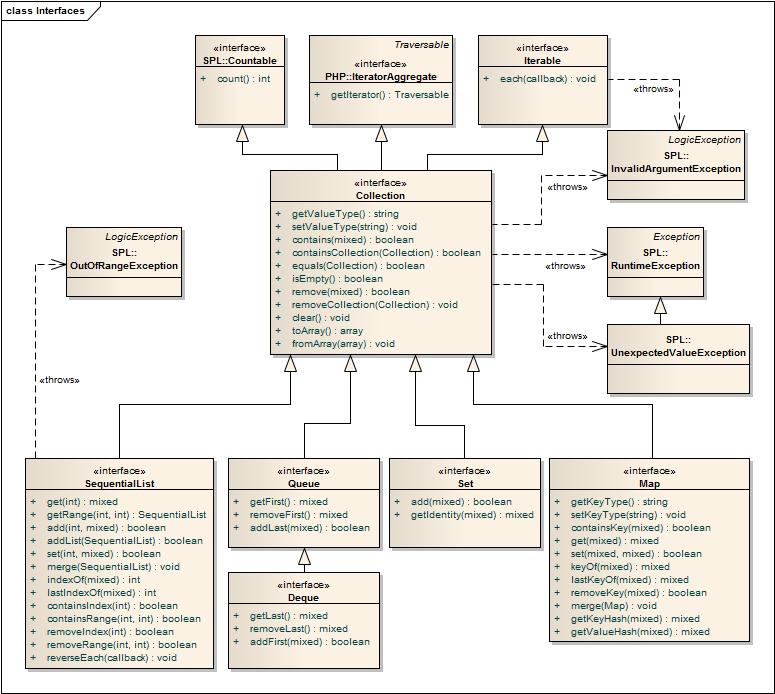
As you can see from the diagram, all collection interfaces inherit the IteratorAggregate interface, which makes it possible to crawl collections using foreach (). The problem with warning that pops up when processing maps <object - object> with the help of foreach () still remains, but since such situations really happen rarely, I decided to close my eyes to this.
Maps are represented by implementations of HashMap, HashSet and HashTable. Each of these implementations has its own specializations for simplified use.
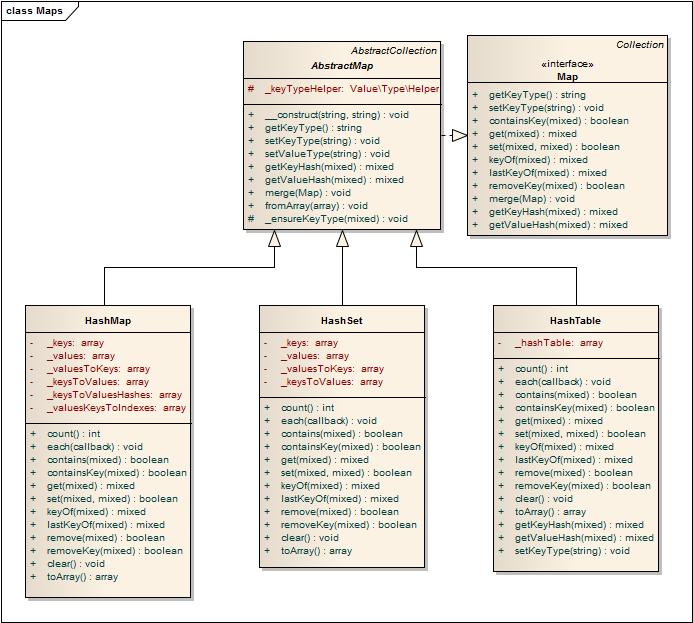
The internal structure of the HashTable map is based on a single PHP array. This makes it possible to work quickly using the O (1) key, but it is bad for the ability to work by value, which is performed by the usual search O (n).
HashTable map keys are unique. HashTable map values are not unique, which allows you to associate one value with multiple keys.
The HashTable map supports strings and integers for keys and strings, integers and objects for values.
Key and value hashing is not performed. The getKeyHash () and getValueHash () methods throw an exception.
HashTable class diagram.
The internal structure of the HashMap and HashSet maps is based on a network of associative links. This makes it possible to implement all map operations using associative samples. The complexity of the card algorithms is O (1), which means that the installation / retrieval time of objects does not change depending on the size of the maps.
The keys of the HashMap card are unique. HashMap map values are not unique, which allows you to associate one value with multiple keys.
The keys and values of the HashSet map are unique, which allows you to organize a repository of unique associations.
HashMap and HashSet support strings, integers, and objects for keys and values.
HashMap class diagram.
HashSet class diagram.
The implementation of the sets has undergone some cosmetic changes and overgrown with specializations for easy use.
Chart of classes of sets.
The implementation of lists and queues remained virtually unchanged.
Chart of lists and queues.
All submitted code is covered with PHPUnit tests.
These were my first Unit tests and I am very pleased with the experience. This type of testing allowed me to catch about ten typos and one fundamental error, for fixing which I had to change the implementation.
I would like to note three things:
The most interesting for me was how productive the collections were. I discarded implementations of sets and sequential lists and focused on testing cards.
Test objects:
Testing criteria:
I will not describe the testing platform in detail, since I do not see much sense in this. The fact is that these tests are not intended to determine quantitative characteristics, but rather to demonstrate the ratios. Ratios of test results practically did not change either on different hardware or on different operating systems.
The test results in this post I shot from my laptop on Windows Vista 32 bit.
Schedule:
Test files:
Schedule:
Test files:
Schedule:

Test files:
Schedule:
Test files:
In the process, some interesting facts surfaced that I want to share.
I think many people know the spl_object_hash () function.
It turns out she has one, in my opinion, not a very good feature - the inconstancy of hashes.
The variability test of spl_object_hast ():
What follows from this and why is this feature unpleasant?
For me and my work, this behavior was not appropriate, since I relied on this function as the source of fast hashing of objects.
In the comments to my previous post, the user Athari left a valuable comment, part of which I quote:
This is really a big deal of sense, but still I decided to check it out.
Results:
The same user, Athari, left another good comment on the previous post:
To recreate the context, let me remind you that it was a question of supporting the array as the data type of the collection keys. To do this, it was serialized to cast to a string, and after hashing this string using md5 ().
Really "expensive" price. In the current implementation, I generally refused to support arrays as card keys.
The reasons why I refused to support arrays:
I especially want to stop at the item “Unsafe.” The point is the lack of feedback between the data and the hash (no matter how “expensive” we got it). If the client code saves the reference to the array that we have hashed and changes it, the hash will become obsolete. Get information that this is the same array of opportunities will not be. The same applies to other scalar data types.
Is there a way out? The only thing that comes to mind is to use an array through a wrapper object (ArrayObject, etc ...). In this case, you can at least get a "non-permanent" spl_object_hash ().
Perhaps the most important question that needs to be answered is: “Are you ready to pay such a performance price for this decision?”. I'm sure no one is ready. And me as well. When I created a graph of performance test results, I was surprised. I expected much smaller ratios in comparison with standard implementations, although I was well aware that this solution was clearly losing in this aspect. At first I even tried to find a solution to the problems, but, alas, nothing happened. The main problem is that even a method call is an “expensive” operation in this case. As for the amount of consumed RAM, I still do not understand what so many resources are spent on. The only useful innovation is the two-way hashing of the card, which makes it possible to choose from it by value within O (1).
In general, I believe that this project has failed, and the reason for this is the performance aspect.
Based on my analytics, a similar solution will appear over time. The best place for him is the SPL package . Maybe it will not be SPL, but some other PECL module that will eventually go into the standard PHP build. In any case, something satisfactory or good will come out only with competent implementation in C. By the way, if someone is interested in this project and wants to help implement it as a PECL module, I will be glad to cooperate.
Perhaps just be content with what we have at the moment and wait. Even now everything is pretty good.
Personally, I decided to create more lightweight implementations that will just help a little in everyday life and will not be anything more than standard PHP arrays. Already there are some sketches:
Class diagram:
MixedArray & ObjectArray UML Diagram
Source codes:
MixedArray
ObjectArray
If it is interesting to someone, write, I will tell about the idea in more detail.
https://github.com/rmk135/Rmk-Framework
I thank everyone for the constructive comments on the previous post. They were very helpful. I will be glad to hear your opinion again.
Thank you for reading to the end and sorry for the abundance of graphics, I tried to place it only where necessary.
In this post you will see:
- Project and implementation of collections of objects in PHP.
- Performance tests
- Impressions about writing the first Unit tests.
- Interesting information about working with sets of PHP objects.
What was done?
')
After the publication of my last post and the end of his discussion, I made a plan for further development:
- Implementing the ability to iterate collections using foreach ().
- Specialization of the main implementations of collections for more convenient use.
- Creating a new implementation of the map interface based on a single PHP array.
- Improving hashing algorithms.
- Waiver of certain data types for maps. The final list of supported types is as follows: int, string, object.
- Testing functionality.
- Performance Testing
In addition to the above list, there were also candidates who were not included in the plan for the current release:
- Filtering and sorting functions.
- Utilitarian functions of collections.
Collection interfaces
The interfaces of collections developed earlier reacted rather stably to the new development plan. The interface diagram of the current version looks like this:
As you can see from the diagram, all collection interfaces inherit the IteratorAggregate interface, which makes it possible to crawl collections using foreach (). The problem with warning that pops up when processing maps <object - object> with the help of foreach () still remains, but since such situations really happen rarely, I decided to close my eyes to this.
Card implementations
Maps are represented by implementations of HashMap, HashSet and HashTable. Each of these implementations has its own specializations for simplified use.
Hashtable
The internal structure of the HashTable map is based on a single PHP array. This makes it possible to work quickly using the O (1) key, but it is bad for the ability to work by value, which is performed by the usual search O (n).
HashTable map keys are unique. HashTable map values are not unique, which allows you to associate one value with multiple keys.
The HashTable map supports strings and integers for keys and strings, integers and objects for values.
Key and value hashing is not performed. The getKeyHash () and getValueHash () methods throw an exception.
HashTable class diagram.
HashMap & HashSet
The internal structure of the HashMap and HashSet maps is based on a network of associative links. This makes it possible to implement all map operations using associative samples. The complexity of the card algorithms is O (1), which means that the installation / retrieval time of objects does not change depending on the size of the maps.
The keys of the HashMap card are unique. HashMap map values are not unique, which allows you to associate one value with multiple keys.
The keys and values of the HashSet map are unique, which allows you to organize a repository of unique associations.
HashMap and HashSet support strings, integers, and objects for keys and values.
HashMap class diagram.
HashSet class diagram.
Implementing Sets, Lists, and Queues
The implementation of the sets has undergone some cosmetic changes and overgrown with specializations for easy use.
Chart of classes of sets.
The implementation of lists and queues remained virtually unchanged.
Chart of lists and queues.
Functionality testing
All submitted code is covered with PHPUnit tests.
These were my first Unit tests and I am very pleased with the experience. This type of testing allowed me to catch about ten typos and one fundamental error, for fixing which I had to change the implementation.
I would like to note three things:
- If you do not use Unit tests yet, start right now. Personally, I had an interesting situation: I spawned quite a lot of code that I had to maintain and I learned, I learned a lot of tricks that should help to do it, but did not write a single Unit test. Why? - Just afraid to start. Only now I realized that my life could have been much easier.
- Having written the first few tests, I realized that there is a big unknown (for me) world inside. Of the variety of assert *, I have used only a few. The test code was often not effective and was duplicated. After a quick look at the PHPUnit documentation , I realized that tests can be much better than those I created.
- Unit tests do not cure all diseases. We can test the method, all the logic inside it, we even have a convenient platform to test certain small scenarios, but do not forget about other testing methods. From what can be adequately automated, I would choose Behavior tests as an additional test option.
Performance testing
The most interesting for me was how productive the collections were. I discarded implementations of sets and sequential lists and focused on testing cards.
Test objects:
- Normal PHP array.
- SPL implementation of an ArrayObject array.
- HashTable map implementation.
- Implementation of the HashSet card.
- Implementation of the HashMap card.
Testing criteria:
- The average installation time of a key / value pair.
- Average time to sample values by key.
- Average key sampling time by value.
- The amount of consumed RAM.
I will not describe the testing platform in detail, since I do not see much sense in this. The fact is that these tests are not intended to determine quantitative characteristics, but rather to demonstrate the ratios. Ratios of test results practically did not change either on different hardware or on different operating systems.
The test results in this post I shot from my laptop on Windows Vista 32 bit.
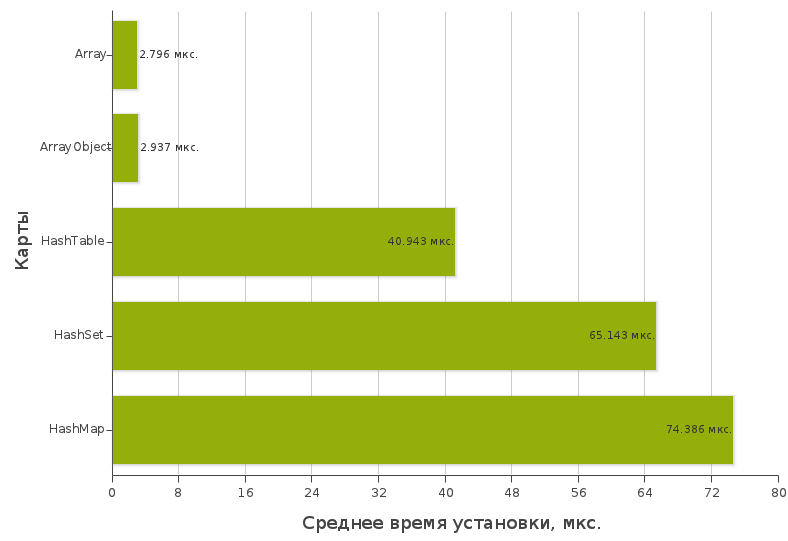
Testing the installation time of a key / value pair
Schedule:
Test files:
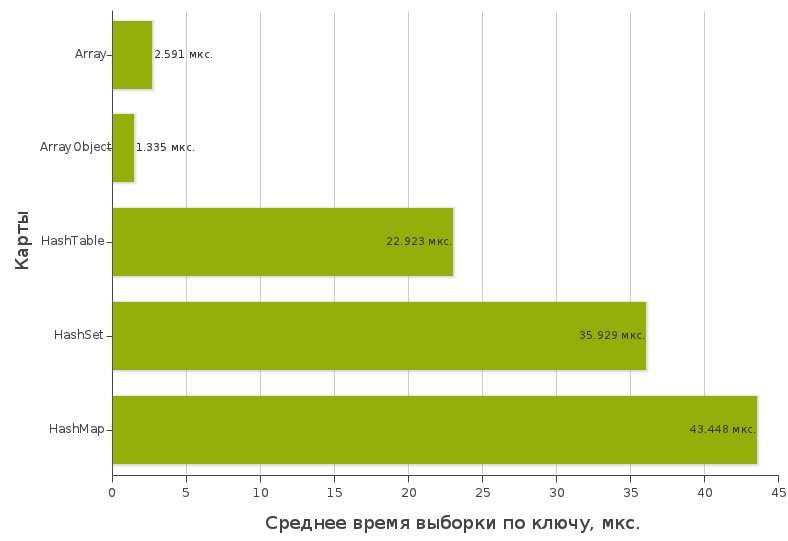
Testing value sampling time by key
Schedule:
Test files:
Testing key sampling time by value
Schedule:
Test files:
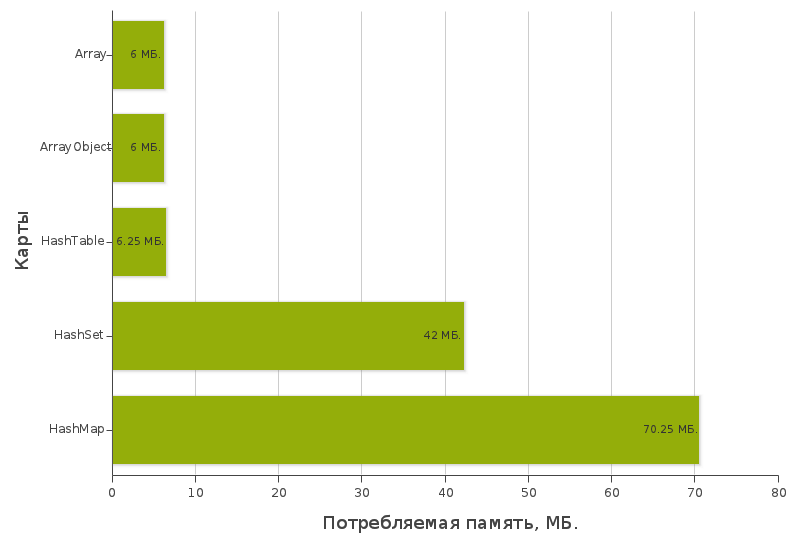
Testing the amount of consumed RAM
Schedule:
Test files:
Some interesting facts
In the process, some interesting facts surfaced that I want to share.
Inconsistency spl_object_hash ()
I think many people know the spl_object_hash () function.
It turns out she has one, in my opinion, not a very good feature - the inconstancy of hashes.
The variability test of spl_object_hast ():
<?php $object1 = new stdClass(); $hash1 = spl_object_hash($object1); unset($object1); $object2 = new stdClass(); $hash2 = spl_object_hash($object2); var_dump($hash1); var_dump($hash2); var_dump($hash1 === $hash2); //string '000000004974d03c000000005560c408' (length=32) //string '000000004974d03c000000005560c408' (length=32) //boolean true What follows from this and why is this feature unpleasant?
- You cannot rely on spl_object_hash () as a unique object identifier, even within a process.
- You cannot serialize any data structures that store spl_object_hash () hashes without updating the hashes when deserializing.
For me and my work, this behavior was not appropriate, since I relied on this function as the source of fast hashing of objects.
Internal hashing of array keys
In the comments to my previous post, the user Athari left a valuable comment, part of which I quote:
Why calculate md5 for strings? Pohapeshnye arrays - and so hashtables, no need to calculate hashes at two levels. Only memory and computational resources are wasted.
This is really a big deal of sense, but still I decided to check it out.
Results:
- If the string key is small, say 100 characters, then calculating its md5 hash really only consumes resources.
- If the string key is long enough, say 20k characters, then the size of the RAM consumed by the array grows ~ 70% compared to its md5 hashed analog. At the same time, the installation and access time remains commensurate, but, of course, in favor of a “clean” key.
Hash arrays
The same user, Athari, left another good comment on the previous post:
The serialize call is fun. I understand that “it is necessary” to support all types, but not at the same price.
To recreate the context, let me remind you that it was a question of supporting the array as the data type of the collection keys. To do this, it was serialized to cast to a string, and after hashing this string using md5 ().
Really "expensive" price. In the current implementation, I generally refused to support arrays as card keys.
The reasons why I refused to support arrays:
- "Expensive" in performance.
- Few claimed.
- Not safe.
I especially want to stop at the item “Unsafe.” The point is the lack of feedback between the data and the hash (no matter how “expensive” we got it). If the client code saves the reference to the array that we have hashed and changes it, the hash will become obsolete. Get information that this is the same array of opportunities will not be. The same applies to other scalar data types.
Is there a way out? The only thing that comes to mind is to use an array through a wrapper object (ArrayObject, etc ...). In this case, you can at least get a "non-permanent" spl_object_hash ().
Conclusion
Perhaps the most important question that needs to be answered is: “Are you ready to pay such a performance price for this decision?”. I'm sure no one is ready. And me as well. When I created a graph of performance test results, I was surprised. I expected much smaller ratios in comparison with standard implementations, although I was well aware that this solution was clearly losing in this aspect. At first I even tried to find a solution to the problems, but, alas, nothing happened. The main problem is that even a method call is an “expensive” operation in this case. As for the amount of consumed RAM, I still do not understand what so many resources are spent on. The only useful innovation is the two-way hashing of the card, which makes it possible to choose from it by value within O (1).
In general, I believe that this project has failed, and the reason for this is the performance aspect.
Development
Based on my analytics, a similar solution will appear over time. The best place for him is the SPL package . Maybe it will not be SPL, but some other PECL module that will eventually go into the standard PHP build. In any case, something satisfactory or good will come out only with competent implementation in C. By the way, if someone is interested in this project and wants to help implement it as a PECL module, I will be glad to cooperate.
What to do next?
Perhaps just be content with what we have at the moment and wait. Even now everything is pretty good.
Personally, I decided to create more lightweight implementations that will just help a little in everyday life and will not be anything more than standard PHP arrays. Already there are some sketches:
Class diagram:
MixedArray & ObjectArray UML Diagram
Source codes:
MixedArray
ObjectArray
If it is interesting to someone, write, I will tell about the idea in more detail.
Source codes
https://github.com/rmk135/Rmk-Framework
Acknowledgments
I thank everyone for the constructive comments on the previous post. They were very helpful. I will be glad to hear your opinion again.
Thank you for reading to the end and sorry for the abundance of graphics, I tried to place it only where necessary.
Source: https://habr.com/ru/post/145575/
All Articles