Free soup will no longer be
Fundamental turn towards concurrency in programming
Posted by:
Translation: Alexander Kachanov
The Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
')
Link to the original article: www.gotw.ca/publications/concurrency-ddj.htm
Translator's note : This article provides an overview of current trends in processor development, as well as what these trends mean for us - programmers. The author believes that these trends are of fundamental importance, and that every modern programmer will have to relearn something in order to keep up with life.
This article is quite old. She is already 7 years old, if you count from the moment of her first publication in early 2005. Keep this in mind when reading the translation, as many things that have already become familiar to you were new to the author of the article in 2005 and just appeared.
The biggest software development revolution since the PLO revolution is knocking on your door, and its name is Parallelism.
This article was first published in the journal “Dr. Dobb's Journal ”in March 2005. A shorter version of this article was published in the C / C ++ Users Journal in February 2005 under the title The Concurrency Revolution.
Update: Processor growth trend graph was updated in August 2009. New data has been added to it, which shows that all predictions of this article come true. The rest of the text of this article remained unchanged as it was published in December 2004.
Free soup will soon be no more. What will you do about this? What are you doing about this?
The leading manufacturers of processors and architectures, ranging from Intel and AMD to Sparc and PowerPC, have largely exhausted the traditional possibilities of increasing productivity. Instead of further increasing the frequency of the processors and their linear bandwidth, they massively turn to hyperthreading and multicore architectures. Both of these architectures are already present in today's processors. In particular, modern PowerPC and Sparc IV processors are multi-core, and in 2005 Intel and AMD will join the flow. By the way, the major topic of the In-Stat / MDR Fall Processor Forum, held in the fall of 2004, was the topic of multi-core devices, since it was there that many companies presented their new and updated multi-core processors. It would not be an exaggeration to say that 2004 was a year of multi-core.
So we are approaching a fundamental turning point in software development, at least a few years ahead, and for applications designed for general-purpose desktops and for the lower server segment (which, by the way, in dollar terms make up an enormous share of all programs sold today On the market). In this article I will describe how the hardware is changing, why these changes have suddenly become important for us, how exactly the parallelization revolution will affect you, and how you will most likely be writing programs in the future.
Perhaps the free soup is over a year or two ago. We just now began to notice it.
You've probably heard such an interesting saying: “No matter how much Andy gives out, Bill will take everything away” (“Andy giveth and Bill taketh away”)? (comment of the translator - Means Andy Grove - the head of the Intel company, and Bill Gates - the head of the Microsoft company). No matter how many processors increase the speed of their work, programs will always figure out how to spend this speed. Make the processor ten times faster, and the program will find ten times more work for it (or, in some cases, allow itself to do the same work ten times less efficiently). Over the course of several decades, most applications have been working faster and faster, doing absolutely nothing for it, even without the release of new versions or fundamental changes in the code. Just the manufacturers of processors (in the first place) and the manufacturers of memory and hard disks (in the second place) each time created more and more new, ever faster computer systems. The clock frequency of the processor is not the only criterion for evaluating its performance, and even not the most correct, but nevertheless it says a lot: we have seen how processors with a clock frequency of 1 GHz replaced the 500 MHz processors, followed by 2 GHz marketing processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary.
Now let us ask ourselves the question: When will this race end? It seems that Moore's Law predicts exponential growth. It is clear that such growth cannot continue forever, it will inevitably rest on physical limits: after all, over the years the speed of light does not become faster. So growth will sooner or later slow down and even stop. (Small clarification: Yes, Moore's law speaks mainly of the density of transistors, but it can be said that there was an exponential growth in such areas as clock speeds. In other areas, growth was even greater, for example, the growth of storage capacities, but topic of a separate article.)
If you are a software developer, most likely you have been relaxing for a long time in the wake of increasing productivity of desktop computers. Is your program running slowly when performing some operation? “Why worry?”, You will say, “tomorrow even faster processors will come out, but in general programs are slow not only because of a slow processor and slow memory (for example, because of slower I / O devices, because of calls to databases) ". The correct course of thought?
It is quite true. For yesterday. But absolutely wrong for the foreseeable future.
The good news is that processors will become more and more powerful. The bad news is that, at least in the near future, the growth of processor power will go in a direction that will in no way automatically speed up the work of most existing programs.
Over the past 30 years, processor developers have been able to increase performance in three main areas. The first two of them are related to the execution of the program code:
Increasing the clock frequency means an increase in speed. If you increase the speed of the processor, it will more or less lead to the fact that it will execute the same code faster.
Optimizing the execution of the program code means doing more work per cycle. Today's processors are equipped with very powerful instructions, and they perform various optimizations, from trivial to exotic, including pipelining of code, branch predictions, execution of several instructions for the same clock cycle, and even execution of program instructions in a different order (instructions reordering). All these technologies were designed to ensure that the code was executed as best as possible and / or as quickly as possible in order to squeeze as much as possible from each clock cycle, reducing delays to a minimum and performing more operations per clock clock.
A small digression about the implementation of instructions in a different order (instruction reordering) and memory models (memory models): I want to note that by the word “optimizations” I meant something really more. These “optimizations” can change the meaning of the program and lead to results that would be contrary to the programmer’s expectations. It makes a huge difference. Processor developers are not insane, and in life they will not offend flies, they never would even spoil your code ... in a normal situation. But over the past few years they have decided on aggressive optimizations for the sole purpose: to squeeze even more out of each processor tick. At the same time, they are well aware that these aggressive optimizations jeopardize the semantics of your code. Well, are they from harm doing this? Not at all. Their pursuit is a reaction to the pressure of the market, which requires faster and faster processors. This pressure is so great that such an increase in the speed of your program puts its correctness and even its ability to work at risk.
I will give two most striking examples: changing the order of write data operations (write reordering) and the order of their reading (read reordering). Changing the order of data write operations leads to such surprising consequences and confuses so many programmers that this function usually has to be turned off, since when it is turned on, it becomes too difficult to judge correctly how a written program will behave. Permutation of data reading operations can also lead to surprising results, but this function is usually left enabled, since there are no special difficulties for programmers, and the performance requirements of operating systems and software products force programmers to make at least some compromise and reluctantly choose less of the "evil" of optimization.
Finally, increasing the size of the internal cache means striving to access RAM as rarely as possible. The computer's RAM runs much slower than the processor, so it's best to place the data as close as possible to the processor so as not to run after them in RAM. The closest thing is to store them on the same piece of silicon where the processor is located. The increase in the size of the cache in recent years has been simply staggering. Today, no one can be surprised by processors with built-in level 2 (L2) cache memory of 2MB or more. (Of the three historical approaches to increase processor performance, cache growth will be the only promising approach for the near future. I’ll talk a little more about the importance of cache memory.)
Good. Why am I all this?
The main meaning of this list is that all the listed directions are not related to concurrency. Breakthroughs in all the listed areas will lead to acceleration of sequential (non-parallel, single-process) applications, as well as those applications that use parallelism. This conclusion is important because most of today's applications are single-threaded, I will discuss the reasons for this below.
Of course, the compilers had to keep up with the processors; From time to time, you had to recompile your application, choosing a certain processor model as the minimum acceptable, in order to benefit from new instructions (for example, MMX, SSE), new functions and new characteristics. But in general, even old programs always worked much faster on new processors than on old ones, even without any recompilation and use of the newest instructions of the newest processors.
How beautiful was this world. Unfortunately, this world no longer exists.
The usual growth of processor performance for us two years ago came upon a wall. Most of us have already begun to notice this.
A similar schedule can be created for other processors, but in this article I am going to use data on Intel processors. Figure 1 presents a graph showing when which Intel processor was on the market, its clock frequency and the number of transistors. As you can see, the number of trasistors continues to grow. But with the clock frequency we have problems.
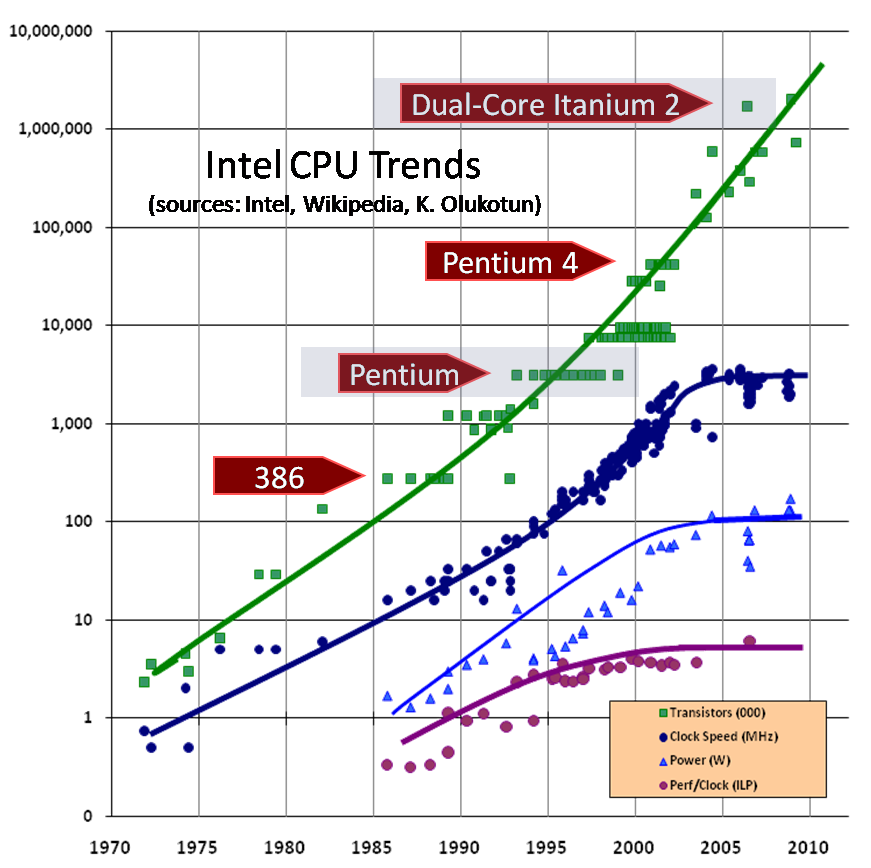
Please note that in the 2003 region, the clock frequency curve drastically and strangely deviates from the usual trend of continuous growth. Between the points, I drew lines to make the trend clearer; instead of continuing to grow, the chart suddenly becomes horizontal. The growth of the clock frequency is given more and more cost, and there are many physical obstacles to growth, for example, processor heat (too much heat is released and it is too difficult to dissipate), energy consumption (too high) and parasitic leakage current.
Short digression: see what is the processor clock speed on your computer? Maybe 10GHz? Intel processors reached the 2GHz level a long time ago (in August 2001), and if the upward trend in clock frequency that existed before 2003 continued, now - in early 2005 - the first 10GHz Pentium processors should have appeared. Look around, do you see them? Moreover, no one even has plans for processors with such a clock speed, and we do not even know when such plans will appear.
Well, what about a 4GHz processor? Already, there are processors with a frequency of 3.4 GHz, so 4 GHz is just around the corner? Alas, we can not even reach 4 GHz. In mid-2004, you probably remember how Intel moved the release of its 4GHz processor to 2005, and then in the fall of 2004 officially announced the complete abandonment of these plans. At the time of this writing, Intel plans to move slightly ahead, releasing a 3.73GHz processor in early 2005 (in Figure 1, this is the highest point on the frequency growth graph), but it can be said that the race for hertz is over, at least present moment. In the future, Intel and most processor manufacturers will seek growth in other ways: they all actively began to turn to multicore solutions.
Maybe sometime we will still see 4GHz s processor in our desktop computers, but this will not be in 2005. Of course, Intel’s laboratories have prototypes that work at higher speeds, but these speeds are achieved by heroic efforts, for example, using bulky cooling equipment. Do not expect that such cooling equipment will ever appear in your office, and certainly not in the plane where you would like to work on a laptop.
“There is no free soup (BSNB)” - R.A. Heinlein, “The moon is a strict hostess”
Does this mean that Moore's Law is no longer valid? The most interesting is that the answer will be “no”. Of course, like any exponential progression, Moore's law will once cease to work, but it does not seem to threaten the law for the next few years. Despite the fact that processor designers can no longer increase the clock frequency, the number of transistors in their processors continues to grow at an explosive rate, and in the coming years, the growth according to Moore's law will continue.
The main difference from previous trends, for the sake of which this article was written, is that the performance gain of several future generations of processors will be achieved in fundamentally other ways. And the majority of current applications on these new, more powerful processors will no longer automatically run faster, unless significant changes are made to their design.
In the near future, more precisely in the next few years, performance gains in new processors will be achieved in three main ways, only one of which remains from the previous list. Namely:
Hyperthreading is a technology for executing two or more threads in parallel on the same processor. Hyper-threaded processors are already on the market now, and they do allow you to execute several instructions in parallel. However, in spite of the fact that the hyper-threaded processor for performing this task has additional hardware, for example, additional registers, it still has only one cache, one computing unit for integer mathematics, one unit for floating-point operations and one by one all that is available in any simple processor. It is believed that hyperthreading allows you to increase the performance of well-written multi-stream programs by 5-15 percent, and the performance of well-written multi-thread programs under ideal conditions increases by as much as 40%. Not bad, but this is not a doubling of performance, and single-threaded programs cannot win anything here.
Multicore (Multicore) is the technology of placing two or more processors on the same chip. Some processors, such as SPARC and PowerPC, are already available in multi-core versions. The first attempts of Intel and AMD, which should be realized in 2005, differ from each other in the degree of processor integration, but functionally they are very similar. The AMD processor will have several cores on a single chip, which will lead to a greater performance gain, while the first Intel multi-core processor is just two coupled Xeon processors on a single large substrate. The gain from such a decision will be the same as from the presence of a two-processor system (only cheaper, since the motherboard does not need two sockets to install two chips and additional chips to coordinate them). Under ideal conditions, the speed of program execution will almost double, but only with fairly well-written multi-threaded applications. Single-threaded applications will not receive any increment.
Finally, on-die cache growth is expected, at least in the near future. Of all three trends, only this one will lead to an increase in the performance of most existing applications. Growth of the size of the built-in cache for all applications is important simply because size means speed. Access to RAM is too expensive, and by and large I want to access RAM as rarely as possible. In case of cache miss, it will take 10-50 times longer to extract data from RAM than to retrieve it from the cache. Until now, people are surprised, because it was considered that RAM runs very quickly. Yes, fast compared to disks and the network, but the cache is even faster. If the entire amount of data with which the application is to work, is placed in the cache, we are in chocolate, and if not, in something else. That is why the growing size of the cache will save some of today's programs and breathe a little more life into them for several years ahead without any significant alterations on their part. As they said during the Great Depression: "Cash is not enough." ("Cache is king")
(A brief digression: here is a story that happened to our compiler, as a demonstration of the statement “size means speed.” The 32-bit and 64-bit versions of our compiler are created from the same source code, just when compiling we indicate which process you need to create: 32-bit or 64-bit. It was expected that the 64-bit compiler should run faster on a 64-bit processor, if only because the 64-bit processor had a lot more registers, and there were optimizing functions for faster code execution. Sun It's just fine. What about data? The transition to 64 bits did not change the size of most of the data structures in memory, except, of course, for pointers, the size of which became twice as large. It turned out that our compiler uses pointers much more often than some or another application. Since the size of the pointers is now 8 bytes, instead of 4 bytes, the total size of the data that the compiler needed to work with has increased. An increase in the amount of data has worsened the performance just as much as it has improved due to faster processors and availability of additional registers. At the time of this writing, our 64-bit compiler works at the same speed as its 32-bit companion, despite the fact that both compilers are assembled from the same source code, and the 64-bit processor is more powerful than the 32-bit one. Size means speed!)
Truly, the cache will rule the ball. Since neither hyper-threading nor multi-core will increase the speed of most of today's programs.
So what do these hardware changes mean for us - programmers? You have probably already understood what the answer will be, so let's discuss it and draw conclusions.
If a dual-core processor consists of two 3 GHz s cores, then we get the performance of a 6 GHz processor. Right?
Not! If two threads are executed on two physically separate processors, this does not mean that the overall performance of the program is doubled. Similarly, a multithreaded program will not work twice as fast on dual-core processors. Yes, it will work faster than on a single-core processor, but the speed will not grow linearly.
Why not? First, we have the costs of matching the cache contents (cache coherency) of the two processors (consistent caches and shared memory), as well as the costs of other interactions. Today, two- or four-processor machines do not overtake their single-processor counterparts in speed of two or four times, even when performing multi-threaded applications. The problems remain essentially the same in those cases when instead of several separate processors we have several cores on a single chip.
Secondly, several cores are fully used only when they are performing two different processes, or two different threads of the same process, which are written in such a way that they can work independently of each other and never wait for each other.
(In contradiction with my previous statement, I can imagine the real situation where a single-threaded application for an ordinary user will run faster on a dual-core processor. This will not happen at all because the second core will be occupied with something useful. On the contrary it will run some kind of trojan or virus that has previously eaten away computing resources from a uniprocessor machine. I’ll let you decide whether you need to purchase another processor in addition to the first one in order to run viruses and viruses on it Oyany.)
If your application is single threaded, you use only one processor core. Of course, there will be some acceleration, since the operating system or background application will run on other cores, but as a rule, the operating systems do not load the processors by 100%, so the neighboring core will mostly stand idle. (Or again, a Trojan or a virus will spin on it)
In the late 90s we learned how to work with objects. In programming, there was a transition from structured programming to object-oriented, which was the most significant revolution in programming in the last 20, and maybe even 30 years. There have been other revolutions, including the recent emergence of web services, but in our entire career we have not seen a revolution more fundamental and significant in consequences than the object revolution.
Up to this day.
Starting from today for the "soup" will have to pay. Of course, you can get some performance gains for free, mainly due to the increased cache size. But if you want your program to benefit from the exponential growth of the power of new processors, it will have to become a correctly written parallelized (usually multithreaded) application. It is easy to say, yes it is difficult to do, because not all tasks can be parallelized easily, and also because it is very difficult to write parallel programs.
I hear the cries of indignation: “Parallelism? What is this news!? People have been writing parallel programs for a long time. ” Right. But this is only a tiny proportion of programmers.
, - 60- , Simula. . 90- . ? , , . , – – .
Similarly with concurrency. We know about it from time immemorial, when writing coroutines and monitors and other such clever utilities. And over the past ten years, more and more programmers have begun to create parallel (multiprocess or multi-threaded) systems. But it was still too early to talk about a revolution, a turning point. Therefore, today most programs are single-threaded.
, : , « ». , , . . , , , , . : ( ). , , , . , , , , , . , , .
(Concurrency) — . , , . , , , ( ), .
, . -, , ; , , ( ). -, , , , , – . , .
. . , , , , , . .
, , . .
And yet the main difficulty of parallelism lies in itself. The parallel programming model, i.e. the model of images that develops in the programmer’s head, and with which he judges the behavior of his program, is much more complicated than the model of sequential code execution.
, , - , . , (race conditions), , . , , , , , , . , , , , , , . , - , , . , , , .
, , , : , . , , : , , , . , , - , , . .
- ( ? ? ? «» «», – ?), – ( «»? « » (deadlock)? ? ? (message queue)? «» «», – ?)
Most of today's programmers do not understand parallelism. Similarly, 15 years ago, most programmers did not understand OOP. But parallel programming models can be learned, especially if we master the concepts of message passing and blocking (message- and lock-based programming). After this, parallel programming will be no more difficult than OOP, and I hope it will become quite familiar. Just prepare yourself and your team will have to spend some time retraining.
( . (concurrent lock-free programming), Java 5 ++. , . , , , . , .)
OK.Let's return to what all this means for us - programmers.
1. The first major consequence that we have already covered is that applications should become parallel if you want to fully use the growing throughput of processors that have already begun to appear on the market and will reign on it in the next few years. For example, Intel claims that in the near future it will create a processor of 100 cores; A single-threaded application can only use 1/100 of the power of this processor.
, (, , , ) . , , , . – . - , 9 , , , 9 1 . . ? , : « , ?» , , «, », . , , — . , ( )! , . , , .
2. , , - (CPU-bound). , , , , . , , , - -, - . ( Wi-Fi?). . : 3. , , ( - ). , . , - , . . ; . , , , .
. , , . , , , . :
3. , . , , , , , , . , .
4. , . Java, , , , , Java . ++ . ( ISO- ++ , ), - . ( , , , , ++ ). , ++, pthreads OpenMP, : (implicit) (explicit). , , , , , . , , . , . , . .
If you have not done it yet, do it now: look carefully at the design of your application, determine which operations require or will require later large computing power from the processor, and decide how these operations can be parallelized. In addition, right now you and your team need to master parallel programming, all its secrets, styles and idioms.
- , – , . , , , ; . , ; , .
, . – , , . , , 100% .
Posted by:
Translation: Alexander Kachanov
The Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
')
Link to the original article: www.gotw.ca/publications/concurrency-ddj.htm
Translator's note : This article provides an overview of current trends in processor development, as well as what these trends mean for us - programmers. The author believes that these trends are of fundamental importance, and that every modern programmer will have to relearn something in order to keep up with life.
This article is quite old. She is already 7 years old, if you count from the moment of her first publication in early 2005. Keep this in mind when reading the translation, as many things that have already become familiar to you were new to the author of the article in 2005 and just appeared.
The biggest software development revolution since the PLO revolution is knocking on your door, and its name is Parallelism.
This article was first published in the journal “Dr. Dobb's Journal ”in March 2005. A shorter version of this article was published in the C / C ++ Users Journal in February 2005 under the title The Concurrency Revolution.
Update: Processor growth trend graph was updated in August 2009. New data has been added to it, which shows that all predictions of this article come true. The rest of the text of this article remained unchanged as it was published in December 2004.
Free soup will soon be no more. What will you do about this? What are you doing about this?
The leading manufacturers of processors and architectures, ranging from Intel and AMD to Sparc and PowerPC, have largely exhausted the traditional possibilities of increasing productivity. Instead of further increasing the frequency of the processors and their linear bandwidth, they massively turn to hyperthreading and multicore architectures. Both of these architectures are already present in today's processors. In particular, modern PowerPC and Sparc IV processors are multi-core, and in 2005 Intel and AMD will join the flow. By the way, the major topic of the In-Stat / MDR Fall Processor Forum, held in the fall of 2004, was the topic of multi-core devices, since it was there that many companies presented their new and updated multi-core processors. It would not be an exaggeration to say that 2004 was a year of multi-core.
So we are approaching a fundamental turning point in software development, at least a few years ahead, and for applications designed for general-purpose desktops and for the lower server segment (which, by the way, in dollar terms make up an enormous share of all programs sold today On the market). In this article I will describe how the hardware is changing, why these changes have suddenly become important for us, how exactly the parallelization revolution will affect you, and how you will most likely be writing programs in the future.
Perhaps the free soup is over a year or two ago. We just now began to notice it.
Free performance soup
You've probably heard such an interesting saying: “No matter how much Andy gives out, Bill will take everything away” (“Andy giveth and Bill taketh away”)? (comment of the translator - Means Andy Grove - the head of the Intel company, and Bill Gates - the head of the Microsoft company). No matter how many processors increase the speed of their work, programs will always figure out how to spend this speed. Make the processor ten times faster, and the program will find ten times more work for it (or, in some cases, allow itself to do the same work ten times less efficiently). Over the course of several decades, most applications have been working faster and faster, doing absolutely nothing for it, even without the release of new versions or fundamental changes in the code. Just the manufacturers of processors (in the first place) and the manufacturers of memory and hard disks (in the second place) each time created more and more new, ever faster computer systems. The clock frequency of the processor is not the only criterion for evaluating its performance, and even not the most correct, but nevertheless it says a lot: we have seen how processors with a clock frequency of 1 GHz replaced the 500 MHz processors, followed by 2 GHz marketing processors and so on. So now we are going through a stage when a processor with a clock frequency of 3 GHz is quite ordinary.
Now let us ask ourselves the question: When will this race end? It seems that Moore's Law predicts exponential growth. It is clear that such growth cannot continue forever, it will inevitably rest on physical limits: after all, over the years the speed of light does not become faster. So growth will sooner or later slow down and even stop. (Small clarification: Yes, Moore's law speaks mainly of the density of transistors, but it can be said that there was an exponential growth in such areas as clock speeds. In other areas, growth was even greater, for example, the growth of storage capacities, but topic of a separate article.)
If you are a software developer, most likely you have been relaxing for a long time in the wake of increasing productivity of desktop computers. Is your program running slowly when performing some operation? “Why worry?”, You will say, “tomorrow even faster processors will come out, but in general programs are slow not only because of a slow processor and slow memory (for example, because of slower I / O devices, because of calls to databases) ". The correct course of thought?
It is quite true. For yesterday. But absolutely wrong for the foreseeable future.
The good news is that processors will become more and more powerful. The bad news is that, at least in the near future, the growth of processor power will go in a direction that will in no way automatically speed up the work of most existing programs.
Over the past 30 years, processor developers have been able to increase performance in three main areas. The first two of them are related to the execution of the program code:
- CPU clock speed
- code execution optimization
- cache
Increasing the clock frequency means an increase in speed. If you increase the speed of the processor, it will more or less lead to the fact that it will execute the same code faster.
Optimizing the execution of the program code means doing more work per cycle. Today's processors are equipped with very powerful instructions, and they perform various optimizations, from trivial to exotic, including pipelining of code, branch predictions, execution of several instructions for the same clock cycle, and even execution of program instructions in a different order (instructions reordering). All these technologies were designed to ensure that the code was executed as best as possible and / or as quickly as possible in order to squeeze as much as possible from each clock cycle, reducing delays to a minimum and performing more operations per clock clock.
A small digression about the implementation of instructions in a different order (instruction reordering) and memory models (memory models): I want to note that by the word “optimizations” I meant something really more. These “optimizations” can change the meaning of the program and lead to results that would be contrary to the programmer’s expectations. It makes a huge difference. Processor developers are not insane, and in life they will not offend flies, they never would even spoil your code ... in a normal situation. But over the past few years they have decided on aggressive optimizations for the sole purpose: to squeeze even more out of each processor tick. At the same time, they are well aware that these aggressive optimizations jeopardize the semantics of your code. Well, are they from harm doing this? Not at all. Their pursuit is a reaction to the pressure of the market, which requires faster and faster processors. This pressure is so great that such an increase in the speed of your program puts its correctness and even its ability to work at risk.
I will give two most striking examples: changing the order of write data operations (write reordering) and the order of their reading (read reordering). Changing the order of data write operations leads to such surprising consequences and confuses so many programmers that this function usually has to be turned off, since when it is turned on, it becomes too difficult to judge correctly how a written program will behave. Permutation of data reading operations can also lead to surprising results, but this function is usually left enabled, since there are no special difficulties for programmers, and the performance requirements of operating systems and software products force programmers to make at least some compromise and reluctantly choose less of the "evil" of optimization.
Finally, increasing the size of the internal cache means striving to access RAM as rarely as possible. The computer's RAM runs much slower than the processor, so it's best to place the data as close as possible to the processor so as not to run after them in RAM. The closest thing is to store them on the same piece of silicon where the processor is located. The increase in the size of the cache in recent years has been simply staggering. Today, no one can be surprised by processors with built-in level 2 (L2) cache memory of 2MB or more. (Of the three historical approaches to increase processor performance, cache growth will be the only promising approach for the near future. I’ll talk a little more about the importance of cache memory.)
Good. Why am I all this?
The main meaning of this list is that all the listed directions are not related to concurrency. Breakthroughs in all the listed areas will lead to acceleration of sequential (non-parallel, single-process) applications, as well as those applications that use parallelism. This conclusion is important because most of today's applications are single-threaded, I will discuss the reasons for this below.
Of course, the compilers had to keep up with the processors; From time to time, you had to recompile your application, choosing a certain processor model as the minimum acceptable, in order to benefit from new instructions (for example, MMX, SSE), new functions and new characteristics. But in general, even old programs always worked much faster on new processors than on old ones, even without any recompilation and use of the newest instructions of the newest processors.
How beautiful was this world. Unfortunately, this world no longer exists.
Obstacles or why we don’t see 10GHz processors
The usual growth of processor performance for us two years ago came upon a wall. Most of us have already begun to notice this.
A similar schedule can be created for other processors, but in this article I am going to use data on Intel processors. Figure 1 presents a graph showing when which Intel processor was on the market, its clock frequency and the number of transistors. As you can see, the number of trasistors continues to grow. But with the clock frequency we have problems.
Please note that in the 2003 region, the clock frequency curve drastically and strangely deviates from the usual trend of continuous growth. Between the points, I drew lines to make the trend clearer; instead of continuing to grow, the chart suddenly becomes horizontal. The growth of the clock frequency is given more and more cost, and there are many physical obstacles to growth, for example, processor heat (too much heat is released and it is too difficult to dissipate), energy consumption (too high) and parasitic leakage current.
Short digression: see what is the processor clock speed on your computer? Maybe 10GHz? Intel processors reached the 2GHz level a long time ago (in August 2001), and if the upward trend in clock frequency that existed before 2003 continued, now - in early 2005 - the first 10GHz Pentium processors should have appeared. Look around, do you see them? Moreover, no one even has plans for processors with such a clock speed, and we do not even know when such plans will appear.
Well, what about a 4GHz processor? Already, there are processors with a frequency of 3.4 GHz, so 4 GHz is just around the corner? Alas, we can not even reach 4 GHz. In mid-2004, you probably remember how Intel moved the release of its 4GHz processor to 2005, and then in the fall of 2004 officially announced the complete abandonment of these plans. At the time of this writing, Intel plans to move slightly ahead, releasing a 3.73GHz processor in early 2005 (in Figure 1, this is the highest point on the frequency growth graph), but it can be said that the race for hertz is over, at least present moment. In the future, Intel and most processor manufacturers will seek growth in other ways: they all actively began to turn to multicore solutions.
Maybe sometime we will still see 4GHz s processor in our desktop computers, but this will not be in 2005. Of course, Intel’s laboratories have prototypes that work at higher speeds, but these speeds are achieved by heroic efforts, for example, using bulky cooling equipment. Do not expect that such cooling equipment will ever appear in your office, and certainly not in the plane where you would like to work on a laptop.
BSNB: Moore's Law and the next generation of processors
“There is no free soup (BSNB)” - R.A. Heinlein, “The moon is a strict hostess”
Does this mean that Moore's Law is no longer valid? The most interesting is that the answer will be “no”. Of course, like any exponential progression, Moore's law will once cease to work, but it does not seem to threaten the law for the next few years. Despite the fact that processor designers can no longer increase the clock frequency, the number of transistors in their processors continues to grow at an explosive rate, and in the coming years, the growth according to Moore's law will continue.
The main difference from previous trends, for the sake of which this article was written, is that the performance gain of several future generations of processors will be achieved in fundamentally other ways. And the majority of current applications on these new, more powerful processors will no longer automatically run faster, unless significant changes are made to their design.
In the near future, more precisely in the next few years, performance gains in new processors will be achieved in three main ways, only one of which remains from the previous list. Namely:
- hyperthreading
- multicore
- cache
Hyperthreading is a technology for executing two or more threads in parallel on the same processor. Hyper-threaded processors are already on the market now, and they do allow you to execute several instructions in parallel. However, in spite of the fact that the hyper-threaded processor for performing this task has additional hardware, for example, additional registers, it still has only one cache, one computing unit for integer mathematics, one unit for floating-point operations and one by one all that is available in any simple processor. It is believed that hyperthreading allows you to increase the performance of well-written multi-stream programs by 5-15 percent, and the performance of well-written multi-thread programs under ideal conditions increases by as much as 40%. Not bad, but this is not a doubling of performance, and single-threaded programs cannot win anything here.
Multicore (Multicore) is the technology of placing two or more processors on the same chip. Some processors, such as SPARC and PowerPC, are already available in multi-core versions. The first attempts of Intel and AMD, which should be realized in 2005, differ from each other in the degree of processor integration, but functionally they are very similar. The AMD processor will have several cores on a single chip, which will lead to a greater performance gain, while the first Intel multi-core processor is just two coupled Xeon processors on a single large substrate. The gain from such a decision will be the same as from the presence of a two-processor system (only cheaper, since the motherboard does not need two sockets to install two chips and additional chips to coordinate them). Under ideal conditions, the speed of program execution will almost double, but only with fairly well-written multi-threaded applications. Single-threaded applications will not receive any increment.
Finally, on-die cache growth is expected, at least in the near future. Of all three trends, only this one will lead to an increase in the performance of most existing applications. Growth of the size of the built-in cache for all applications is important simply because size means speed. Access to RAM is too expensive, and by and large I want to access RAM as rarely as possible. In case of cache miss, it will take 10-50 times longer to extract data from RAM than to retrieve it from the cache. Until now, people are surprised, because it was considered that RAM runs very quickly. Yes, fast compared to disks and the network, but the cache is even faster. If the entire amount of data with which the application is to work, is placed in the cache, we are in chocolate, and if not, in something else. That is why the growing size of the cache will save some of today's programs and breathe a little more life into them for several years ahead without any significant alterations on their part. As they said during the Great Depression: "Cash is not enough." ("Cache is king")
(A brief digression: here is a story that happened to our compiler, as a demonstration of the statement “size means speed.” The 32-bit and 64-bit versions of our compiler are created from the same source code, just when compiling we indicate which process you need to create: 32-bit or 64-bit. It was expected that the 64-bit compiler should run faster on a 64-bit processor, if only because the 64-bit processor had a lot more registers, and there were optimizing functions for faster code execution. Sun It's just fine. What about data? The transition to 64 bits did not change the size of most of the data structures in memory, except, of course, for pointers, the size of which became twice as large. It turned out that our compiler uses pointers much more often than some or another application. Since the size of the pointers is now 8 bytes, instead of 4 bytes, the total size of the data that the compiler needed to work with has increased. An increase in the amount of data has worsened the performance just as much as it has improved due to faster processors and availability of additional registers. At the time of this writing, our 64-bit compiler works at the same speed as its 32-bit companion, despite the fact that both compilers are assembled from the same source code, and the 64-bit processor is more powerful than the 32-bit one. Size means speed!)
Truly, the cache will rule the ball. Since neither hyper-threading nor multi-core will increase the speed of most of today's programs.
So what do these hardware changes mean for us - programmers? You have probably already understood what the answer will be, so let's discuss it and draw conclusions.
Myths and realities: 2 x 3 GHz <6 GHz
If a dual-core processor consists of two 3 GHz s cores, then we get the performance of a 6 GHz processor. Right?
Not! If two threads are executed on two physically separate processors, this does not mean that the overall performance of the program is doubled. Similarly, a multithreaded program will not work twice as fast on dual-core processors. Yes, it will work faster than on a single-core processor, but the speed will not grow linearly.
Why not? First, we have the costs of matching the cache contents (cache coherency) of the two processors (consistent caches and shared memory), as well as the costs of other interactions. Today, two- or four-processor machines do not overtake their single-processor counterparts in speed of two or four times, even when performing multi-threaded applications. The problems remain essentially the same in those cases when instead of several separate processors we have several cores on a single chip.
Secondly, several cores are fully used only when they are performing two different processes, or two different threads of the same process, which are written in such a way that they can work independently of each other and never wait for each other.
(In contradiction with my previous statement, I can imagine the real situation where a single-threaded application for an ordinary user will run faster on a dual-core processor. This will not happen at all because the second core will be occupied with something useful. On the contrary it will run some kind of trojan or virus that has previously eaten away computing resources from a uniprocessor machine. I’ll let you decide whether you need to purchase another processor in addition to the first one in order to run viruses and viruses on it Oyany.)
If your application is single threaded, you use only one processor core. Of course, there will be some acceleration, since the operating system or background application will run on other cores, but as a rule, the operating systems do not load the processors by 100%, so the neighboring core will mostly stand idle. (Or again, a Trojan or a virus will spin on it)
Value for software: Another Revolution
In the late 90s we learned how to work with objects. In programming, there was a transition from structured programming to object-oriented, which was the most significant revolution in programming in the last 20, and maybe even 30 years. There have been other revolutions, including the recent emergence of web services, but in our entire career we have not seen a revolution more fundamental and significant in consequences than the object revolution.
Up to this day.
Starting from today for the "soup" will have to pay. Of course, you can get some performance gains for free, mainly due to the increased cache size. But if you want your program to benefit from the exponential growth of the power of new processors, it will have to become a correctly written parallelized (usually multithreaded) application. It is easy to say, yes it is difficult to do, because not all tasks can be parallelized easily, and also because it is very difficult to write parallel programs.
I hear the cries of indignation: “Parallelism? What is this news!? People have been writing parallel programs for a long time. ” Right. But this is only a tiny proportion of programmers.
, - 60- , Simula. . 90- . ? , , . , – – .
Similarly with concurrency. We know about it from time immemorial, when writing coroutines and monitors and other such clever utilities. And over the past ten years, more and more programmers have begun to create parallel (multiprocess or multi-threaded) systems. But it was still too early to talk about a revolution, a turning point. Therefore, today most programs are single-threaded.
, : , « ». , , . . , , , , . : ( ). , , , . , , , , , . , , .
(Concurrency) — . , , . , , , ( ), .
, . -, , ; , , ( ). -, , , , , – . , .
. . , , , , , . .
, , . .
And yet the main difficulty of parallelism lies in itself. The parallel programming model, i.e. the model of images that develops in the programmer’s head, and with which he judges the behavior of his program, is much more complicated than the model of sequential code execution.
, , - , . , (race conditions), , . , , , , , , . , , , , , , . , - , , . , , , .
, , , : , . , , : , , , . , , - , , . .
- ( ? ? ? «» «», – ?), – ( «»? « » (deadlock)? ? ? (message queue)? «» «», – ?)
Most of today's programmers do not understand parallelism. Similarly, 15 years ago, most programmers did not understand OOP. But parallel programming models can be learned, especially if we master the concepts of message passing and blocking (message- and lock-based programming). After this, parallel programming will be no more difficult than OOP, and I hope it will become quite familiar. Just prepare yourself and your team will have to spend some time retraining.
( . (concurrent lock-free programming), Java 5 ++. , . , , , . , .)
?
OK.Let's return to what all this means for us - programmers.
1. The first major consequence that we have already covered is that applications should become parallel if you want to fully use the growing throughput of processors that have already begun to appear on the market and will reign on it in the next few years. For example, Intel claims that in the near future it will create a processor of 100 cores; A single-threaded application can only use 1/100 of the power of this processor.
, (, , , ) . , , , . – . - , 9 , , , 9 1 . . ? , : « , ?» , , «, », . , , — . , ( )! , . , , .
2. , , - (CPU-bound). , , , , . , , , - -, - . ( Wi-Fi?). . : 3. , , ( - ). , . , - , . . ; . , , , .
. , , . , , , . :
3. , . , , , , , , . , .
4. , . Java, , , , , Java . ++ . ( ISO- ++ , ), - . ( , , , , ++ ). , ++, pthreads OpenMP, : (implicit) (explicit). , , , , , . , , . , . , . .
Finally
If you have not done it yet, do it now: look carefully at the design of your application, determine which operations require or will require later large computing power from the processor, and decide how these operations can be parallelized. In addition, right now you and your team need to master parallel programming, all its secrets, styles and idioms.
- , – , . , , , ; . , ; , .
, . – , , . , , 100% .
Source: https://habr.com/ru/post/145432/
All Articles