Asterisk under real load - distributed failover call center for> 500 operators
About 600 operators in 4 countries handle customer calls to US (and some to Russian) numbers.
Approximately 200 simultaneous conversations at peak times.
Approximately 15,000 calls per day.
An opportunity to scale this solution several times in several minutes (according to our estimates, up to ~ 1000 parallel calls before the problems start).
And of course, tight integration with internal systems (CRM, shopping support, priorities of operators and customers, and many, many other buns).
Who cares how it works and why this is so - welcome
')
Immediately make a reservation, this whole structure grew and developed over 6 years in parallel with the constantly changing needs of the business, if we started building it now, maybe everything would have been different, but ... it is what it is and it works.
To begin with the general scheme:
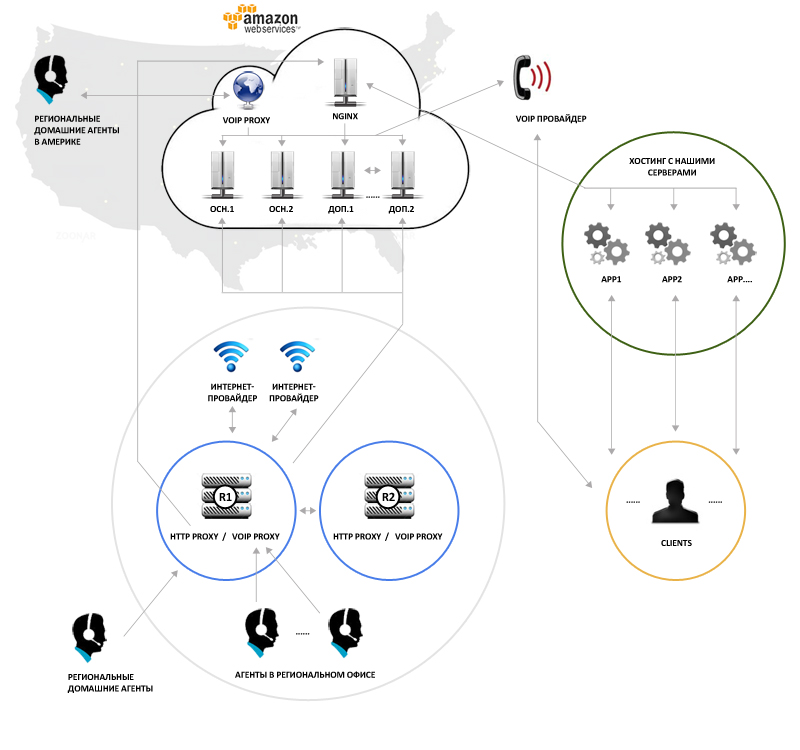
The SIP telephony provider calls to our servers. Servers, at the moment, on Amazon, but we are not strongly attached to it, there are just some amenities that help us solve some tasks easier and more elegant. The telephony provider is configured to failover: if one server did not answer, the call will automatically go to the other, if it will go to the third, and so on (4 IP is actually registered, now 2 are used, but if something happens, you can quickly new main nodes without shamanism with IP-shki and correspondence with the provider).
The server that received the call (one of the main servers) looks at which servers are now available and where there is some load on them at the moment, and either processes the call itself, or throws the SIP-redirect provider to our other server, which should handle this call. Total servers now 2 + N:
2 are two fully interchangeable main servers that know how to balance the load, as well as holding on them some additional services, such as a distributed file system (glusterfs) for files that should be identical on all nodes, memcache for locks, and any other small change. These two nodes are running constantly. N - the rest of the nodes, they are started as needed (after reaching certain threshold values for the number of simultaneous calls), at the moment there are also 2 of them.
Each server, receiving a call, completely independently of the others, as required, conducts it through the IVR, depending on various factors, drives it through different queues, casts a call to voicemail (answering machine), or to a specific person (operator) in one of the offices then keeps the call and writes logs and statistics, and the conversation itself, if allowed, also writes. In general, it conducts it through the entire business logic, which is implemented partly in the MySQL-config, partly in scripts through the agi interface (which again look in MySQL), partly in curl queries.
The list of calls on each server is different, but IVR and queues (and operators waiting for a call in queues) are duplicated on all servers. Accordingly, for some actions, such as transferring a call from a queue to a free operator, the server first hangs the lock on the corresponding objects (on this operator) through a curl request to a certain internal URL, which is answered by a simple memcache script, and only if the request returned OK, this action is performed. Thus, for example, an operator cannot receive several new calls from a queue simultaneously from different servers, but there is no need to synchronize all their state between the machines.
The operator, in turn, has a VoIP-phone on his desk, some have a Soft-Phone, but this is not welcome. When Soft-Phone suffers quality, there is no normal call, and if the agent took off the headphones and turned away from the screen (drinking tea), he can miss the call. In addition, then you need more expensive hardware for the agent's company (now these are low-end diskless stations based on ubuntu, ~ $ 300 per set), and support becomes noticeably more difficult (and therefore more expensive). Soft-phone support is more expensive because iron phones, unlike Soft-Phone, receive IP addresses and a link to their configuration via DHCP. The configuration is given to them by all the same servers on Amazon, after which the phones happily and completely independently register on the servers via a VoIP proxy, which is located in LAN. That is, the work on manual configuration is reduced to almost zero (thanks to provisioning, which is supported by all the phones that we use). Almost all support is just a phone replacement. Software phones, as practice has shown, on a company scale, eat up quite a lot of time for user consultations, installation and configuration, problem solving with sound or something else, in general, 600 people can create an endless stream of problems if you give them a tool to create them ... :)
All communication between the phone and the outside world takes place only through a VoIP proxy (+ transparent HTTP proxy, for receiving a config). But the VoIP proxy already communicates with servers on Amazon, which in turn communicate only with the list of proxy pre-assigned to them, with the provider, and with no one else.
VoIP proxy is the same asterisk, only in the most simplified configuration: everything that is possible is maximally simplified and thrown away; its task is only to pass traffic between phones and servers through itself, pushing it through jitter-buffer (it noticeably improves quality when traffic walks through half of the globe), remove some of the load from the servers (and traffic) communicating with phones locally, respond to all sorts of tests to catch problems, well, every little thing. This is the entry point for operators working from home (as a rule, home users’s links to Amazon are noticeably less stable and faster than our office, but the link to the nearest office is usually within the same country and is usually very good) to improve quality and simplify schemes (all phones only through a proxy). In addition, it is also the "first line of defense." Although in the near future we will most likely switch to VPN connections for such users, since it’s not so expensive in terms of hardware as it was 5 years ago.
The phones themselves are fully interchangeable and practically do not require manual configuration: you only need to assign an IP and type to it in DHCP, after which everything happens by itself: the phone will receive an IP and a link to the config, download it, then, knowing what and where, it will register via a proxy to servers. At the same time, new phones automatically receive a certain new internal number (extention). Calls from this number cannot be made, calls to him will not be received either, he can only do some very basic things, including the possibility for an operator who has sat down for him to login to this device with his personal telephone number, after which calls for this operator’s number will start to be sent to this device will no longer go where it was received before (if the operator is not logged in anywhere - calls are sent to his voice mail). If, by analogy with network technologies, telephone extention is something like a MAC address, to which, after the operator's login, something like an IP address is hung - the operator's personal extention. In this way, decoupling the logic of the call center from its physical component is achieved: all business logic, reports, priorities, and so on are made with the operator's extension (which in essence is not something physical, it is rather a logical object), the extension of the device itself - this is just the point where this operator is currently logged in.
A few words about fault tolerance.
Communication with the telephony provider, as already mentioned, has a failover mechanism on their part. Unfortunately, there is no filer in terms of the operator itself. Firstly, there are not too many operators themselves who are able to provide everything we need, with high quality, with support, and even at a reasonable price. Secondly, in telephony, in contrast to IP networks, it’s so simple, with one movement of the router you cannot switch to another provider. Transfer your numbers to another provider - this is time and money, not much, but with about 1500 numbers, this is already a couple of days and a significant amount of money for each switch is cheaper to wait for a solution. Fortunately (to the credit of telephonists) they fail very rarely and very briefly. So there are only two providers who give incoming calls, one in the USA, one in Russia.
Servers (asterisks) all that is possible (and a little else) configuration is put and read as "realtime" to / from MySQL. In order to notice the changes made by other servers and through the web interface. At first it was a bit buggy, and the asterisk dropped every few hours, but after several patches we managed to make it more or less stable. Thus, whatever node and in what way it makes changes in the config, the next action, depending on this config location, all the nodes do already knowing about the change.
Every few seconds, all nodes write their status (number of calls, load average, active services, etc.) to MySQL. Accordingly, the nodes that distribute calls, on the basis of these data, determine which of the servers online and to whom it is better to give the call (and the load changes quite smoothly). Thus, while mysql is alive and at least one of the main nodes, calls will go, everything will work and the load will be distributed almost equally among the available machines (± small peaks, but as a rule there is always some stock). If, for some reason, the load on the node begins to exceed some reasonable limits, the node (through simple scripts) itself starts to stop or block some less important services on itself in order to prevent loss of quality and stability of the actual calls. So, for example, all sorts of heavy reports become unavailable first.
As MySQL, we have Amazon RDS with the Multi-Availability Zone enabled. And of course, own off-site backups. In theory, if RDS Instance dies, everything should switch itself and without our participation. I don’t know if this happened in practice or not, they didn’t receive notifications, but so far everything works like a watch. But even if RDS dies completely, within half an hour, you can again run everything from the nearest backup. There will be no statistics and logs (which is terrabayty) and therefore part of the reports will be incorrect, but the entire configuration will be no older than one and a half hours (for it is just very compact).
We have VoIP proxies in our offices on routers for Linux. Routers 2 in each office, with a heartbeat running between them. If one dies, all services (including the VoIP proxy) immediately start working on the second router with the same IP.
We also have two providers in each office. If one is dying / buggy - go to the second. This is where the problems with phone registrations begin - the IP is changing (the server needs to know on which IP to send calls). To do this, every proxy once a minute goes to the server on Amazon on some special URL in the web admin and says that "my current IP is such and such." On the same side, the script compares this value with the fact that it is in the database and, if it has suddenly changed, updates everything connected with it in the database (for example, current phone registrations). Since most of the realtime configuration - the next action on many objects will already operate on the correct IP - calls to and from this office will go again.
This whole construction (server with all software, voip-proxy, etc.) is designed as projects in svn with its installation scripts, and is deployed on a fresh clean Linux just by svn checkout ... && ./install.sh. Of course It requires a certain amount of configuration, but it is quite small. For servers, on Amazon there is also up-to-date snapshots, from which you can quickly deploy a +1 primary or secondary server.
Each node has apache + php and a full set of php scripts and in terms of the web all the nodes are completely identical (all go to one mysql, all use memcached on the main nodes). You can control and watch in realtime what is happening with all this design through the web interface on any of the machines. The web interface works with the same MySQL. In addition, some commands are sent asterisk on the desired node directly. For example, “I want to hear what this operator and client are talking about right now” in the web panel of the team leader or the quality control department (which is indispensable when training new operators and catching dishonest ones - we work with money).
On a separate small instance, nginx is spinning, which resolves all external requests to the web (auto configuration of phones, updating IP from proxies, access to admin panel / statistics) on a real server. This player has a snapshot and a script that can raise a new machine in a few seconds and hang an old IP on it, if there is such a need. This machine is so simple and primitive that there is simply nothing to fail and die there, except for iron. The latter is decided by the above-mentioned script (for the time being, except for the test, it has never been used).
Well, of course, monitoring everything and everything with notifications to e-mail and SMS (about critical situations). We monitor using NetXMS + heaps of self-made scripts to collect information about the components of the whole structure.
About the load.
Oddly enough, the main burden does not create conversations. Actually conversations with customers - this is 15-25% of the load. Very resource-intensive actions from the point of view of an asterisk, this is primarily music on hold and IVR. When a client communicates with an operator, an asterisk only pushes traffic away. When a client is in a queue and listens to music and assurances of how important and valuable he is, all this time we are creating an audio stream for him on the fly. If we have 50 people in a queue, we have to create 50 audio streams for them on the fly, and send these streams to clients already (this is simple, in practice they are often different queues, different IVRs, etc., that is, one stream you can't give it all at once, as you did at some telephone stations).
It is quite expensive to convert call records (or voice mail) to mp3. But if there is a desire to listen to it in the browser / on a working computer, and not just from the phone, then this will not go away. And the desire is there. Yes, and space on the disk again saved.
The web interface is even more expensive. All sorts of reports and realtime statistics is a black hole in resources. Everywhere, wherever possible, a sea of agi-shek is stumbled, who write logs and collect statistics for its further use in all sorts of reports. About 5MB of different data per call, including a full SIP-Trace call in case something was wrong.
When all this is processed, you can get a lot of useful information. “From which states did this agent call in the evening over the past 3 months?”, “What% of the missed calls did this department have?”, “Who does this customer call us this month?”, “What is the average percentage of SIP packet loss when calling Pakistan? ”and so on.
Each internal system of the company (CRM, advertising management, fronted) periodically requests all kinds of realtime statistics. For example, the frontend of the project yaturist.ru shows the phones by which you can talk to the operator only if the queue of calls for this project is currently serviced by at least 1 agent. In other cases, the form is shown to submit the application in electronic form.
The admin of each project can also do a lot of non-trivial things through XMLRPC calls. For example, agents who better serve customers receive a higher priority when servicing the queue, but after processing a certain daily sales limit, they receive a lower priority and receive calls only if there is no one left. Thus, they have to work more thoroughly with each client, and not “take it at the expense of turnover”. Calls of VIP-clients come only to operators having the right to work with them, and if they are not there, then the best operators available online. And all this, on the basis of constantly requested statistics, is constantly “wound up” from the depths of these very systems by means of a heap of XLMRPC requests, constantly (“on the fly”) “twisting” the configuration of an asterisk (in MySQL).
If you disable reports and statistics, turn off the recording of conversations / voice mail and music on hold, temporarily block XMLRPC, in theory, even at peak times, we could run it all on one node, and there would be resources left. But ... if we would have done this, it would have lost its meaning, because, in my opinion, the asterisk is just perfect for creating such deep integrations with business needs that can be constantly “docked out” simultaneously with the development of the company. As practice has shown, it is a platform on the basis of which you can build anything from mini-ATS for 3 people to huge installations of almost any level of complexity.
Conclusion
This is rather an overview article, many technical details were left behind the scenes. We are all too different, I do not know what exactly you will be interested. If you are interested in this topic, ask questions. I am pleased to answer or even describe the technical details of interest in a separate article.
Approximately 200 simultaneous conversations at peak times.
Approximately 15,000 calls per day.
An opportunity to scale this solution several times in several minutes (according to our estimates, up to ~ 1000 parallel calls before the problems start).
And of course, tight integration with internal systems (CRM, shopping support, priorities of operators and customers, and many, many other buns).
Who cares how it works and why this is so - welcome
')
Immediately make a reservation, this whole structure grew and developed over 6 years in parallel with the constantly changing needs of the business, if we started building it now, maybe everything would have been different, but ... it is what it is and it works.
To begin with the general scheme:
The SIP telephony provider calls to our servers. Servers, at the moment, on Amazon, but we are not strongly attached to it, there are just some amenities that help us solve some tasks easier and more elegant. The telephony provider is configured to failover: if one server did not answer, the call will automatically go to the other, if it will go to the third, and so on (4 IP is actually registered, now 2 are used, but if something happens, you can quickly new main nodes without shamanism with IP-shki and correspondence with the provider).
The server that received the call (one of the main servers) looks at which servers are now available and where there is some load on them at the moment, and either processes the call itself, or throws the SIP-redirect provider to our other server, which should handle this call. Total servers now 2 + N:
2 are two fully interchangeable main servers that know how to balance the load, as well as holding on them some additional services, such as a distributed file system (glusterfs) for files that should be identical on all nodes, memcache for locks, and any other small change. These two nodes are running constantly. N - the rest of the nodes, they are started as needed (after reaching certain threshold values for the number of simultaneous calls), at the moment there are also 2 of them.
Each server, receiving a call, completely independently of the others, as required, conducts it through the IVR, depending on various factors, drives it through different queues, casts a call to voicemail (answering machine), or to a specific person (operator) in one of the offices then keeps the call and writes logs and statistics, and the conversation itself, if allowed, also writes. In general, it conducts it through the entire business logic, which is implemented partly in the MySQL-config, partly in scripts through the agi interface (which again look in MySQL), partly in curl queries.
The list of calls on each server is different, but IVR and queues (and operators waiting for a call in queues) are duplicated on all servers. Accordingly, for some actions, such as transferring a call from a queue to a free operator, the server first hangs the lock on the corresponding objects (on this operator) through a curl request to a certain internal URL, which is answered by a simple memcache script, and only if the request returned OK, this action is performed. Thus, for example, an operator cannot receive several new calls from a queue simultaneously from different servers, but there is no need to synchronize all their state between the machines.
The operator, in turn, has a VoIP-phone on his desk, some have a Soft-Phone, but this is not welcome. When Soft-Phone suffers quality, there is no normal call, and if the agent took off the headphones and turned away from the screen (drinking tea), he can miss the call. In addition, then you need more expensive hardware for the agent's company (now these are low-end diskless stations based on ubuntu, ~ $ 300 per set), and support becomes noticeably more difficult (and therefore more expensive). Soft-phone support is more expensive because iron phones, unlike Soft-Phone, receive IP addresses and a link to their configuration via DHCP. The configuration is given to them by all the same servers on Amazon, after which the phones happily and completely independently register on the servers via a VoIP proxy, which is located in LAN. That is, the work on manual configuration is reduced to almost zero (thanks to provisioning, which is supported by all the phones that we use). Almost all support is just a phone replacement. Software phones, as practice has shown, on a company scale, eat up quite a lot of time for user consultations, installation and configuration, problem solving with sound or something else, in general, 600 people can create an endless stream of problems if you give them a tool to create them ... :)
All communication between the phone and the outside world takes place only through a VoIP proxy (+ transparent HTTP proxy, for receiving a config). But the VoIP proxy already communicates with servers on Amazon, which in turn communicate only with the list of proxy pre-assigned to them, with the provider, and with no one else.
VoIP proxy is the same asterisk, only in the most simplified configuration: everything that is possible is maximally simplified and thrown away; its task is only to pass traffic between phones and servers through itself, pushing it through jitter-buffer (it noticeably improves quality when traffic walks through half of the globe), remove some of the load from the servers (and traffic) communicating with phones locally, respond to all sorts of tests to catch problems, well, every little thing. This is the entry point for operators working from home (as a rule, home users’s links to Amazon are noticeably less stable and faster than our office, but the link to the nearest office is usually within the same country and is usually very good) to improve quality and simplify schemes (all phones only through a proxy). In addition, it is also the "first line of defense." Although in the near future we will most likely switch to VPN connections for such users, since it’s not so expensive in terms of hardware as it was 5 years ago.
The phones themselves are fully interchangeable and practically do not require manual configuration: you only need to assign an IP and type to it in DHCP, after which everything happens by itself: the phone will receive an IP and a link to the config, download it, then, knowing what and where, it will register via a proxy to servers. At the same time, new phones automatically receive a certain new internal number (extention). Calls from this number cannot be made, calls to him will not be received either, he can only do some very basic things, including the possibility for an operator who has sat down for him to login to this device with his personal telephone number, after which calls for this operator’s number will start to be sent to this device will no longer go where it was received before (if the operator is not logged in anywhere - calls are sent to his voice mail). If, by analogy with network technologies, telephone extention is something like a MAC address, to which, after the operator's login, something like an IP address is hung - the operator's personal extention. In this way, decoupling the logic of the call center from its physical component is achieved: all business logic, reports, priorities, and so on are made with the operator's extension (which in essence is not something physical, it is rather a logical object), the extension of the device itself - this is just the point where this operator is currently logged in.
A few words about fault tolerance.
Communication with the telephony provider, as already mentioned, has a failover mechanism on their part. Unfortunately, there is no filer in terms of the operator itself. Firstly, there are not too many operators themselves who are able to provide everything we need, with high quality, with support, and even at a reasonable price. Secondly, in telephony, in contrast to IP networks, it’s so simple, with one movement of the router you cannot switch to another provider. Transfer your numbers to another provider - this is time and money, not much, but with about 1500 numbers, this is already a couple of days and a significant amount of money for each switch is cheaper to wait for a solution. Fortunately (to the credit of telephonists) they fail very rarely and very briefly. So there are only two providers who give incoming calls, one in the USA, one in Russia.
Servers (asterisks) all that is possible (and a little else) configuration is put and read as "realtime" to / from MySQL. In order to notice the changes made by other servers and through the web interface. At first it was a bit buggy, and the asterisk dropped every few hours, but after several patches we managed to make it more or less stable. Thus, whatever node and in what way it makes changes in the config, the next action, depending on this config location, all the nodes do already knowing about the change.
Every few seconds, all nodes write their status (number of calls, load average, active services, etc.) to MySQL. Accordingly, the nodes that distribute calls, on the basis of these data, determine which of the servers online and to whom it is better to give the call (and the load changes quite smoothly). Thus, while mysql is alive and at least one of the main nodes, calls will go, everything will work and the load will be distributed almost equally among the available machines (± small peaks, but as a rule there is always some stock). If, for some reason, the load on the node begins to exceed some reasonable limits, the node (through simple scripts) itself starts to stop or block some less important services on itself in order to prevent loss of quality and stability of the actual calls. So, for example, all sorts of heavy reports become unavailable first.
As MySQL, we have Amazon RDS with the Multi-Availability Zone enabled. And of course, own off-site backups. In theory, if RDS Instance dies, everything should switch itself and without our participation. I don’t know if this happened in practice or not, they didn’t receive notifications, but so far everything works like a watch. But even if RDS dies completely, within half an hour, you can again run everything from the nearest backup. There will be no statistics and logs (which is terrabayty) and therefore part of the reports will be incorrect, but the entire configuration will be no older than one and a half hours (for it is just very compact).
We have VoIP proxies in our offices on routers for Linux. Routers 2 in each office, with a heartbeat running between them. If one dies, all services (including the VoIP proxy) immediately start working on the second router with the same IP.
We also have two providers in each office. If one is dying / buggy - go to the second. This is where the problems with phone registrations begin - the IP is changing (the server needs to know on which IP to send calls). To do this, every proxy once a minute goes to the server on Amazon on some special URL in the web admin and says that "my current IP is such and such." On the same side, the script compares this value with the fact that it is in the database and, if it has suddenly changed, updates everything connected with it in the database (for example, current phone registrations). Since most of the realtime configuration - the next action on many objects will already operate on the correct IP - calls to and from this office will go again.
This whole construction (server with all software, voip-proxy, etc.) is designed as projects in svn with its installation scripts, and is deployed on a fresh clean Linux just by svn checkout ... && ./install.sh. Of course It requires a certain amount of configuration, but it is quite small. For servers, on Amazon there is also up-to-date snapshots, from which you can quickly deploy a +1 primary or secondary server.
Each node has apache + php and a full set of php scripts and in terms of the web all the nodes are completely identical (all go to one mysql, all use memcached on the main nodes). You can control and watch in realtime what is happening with all this design through the web interface on any of the machines. The web interface works with the same MySQL. In addition, some commands are sent asterisk on the desired node directly. For example, “I want to hear what this operator and client are talking about right now” in the web panel of the team leader or the quality control department (which is indispensable when training new operators and catching dishonest ones - we work with money).
On a separate small instance, nginx is spinning, which resolves all external requests to the web (auto configuration of phones, updating IP from proxies, access to admin panel / statistics) on a real server. This player has a snapshot and a script that can raise a new machine in a few seconds and hang an old IP on it, if there is such a need. This machine is so simple and primitive that there is simply nothing to fail and die there, except for iron. The latter is decided by the above-mentioned script (for the time being, except for the test, it has never been used).
Well, of course, monitoring everything and everything with notifications to e-mail and SMS (about critical situations). We monitor using NetXMS + heaps of self-made scripts to collect information about the components of the whole structure.
About the load.
Oddly enough, the main burden does not create conversations. Actually conversations with customers - this is 15-25% of the load. Very resource-intensive actions from the point of view of an asterisk, this is primarily music on hold and IVR. When a client communicates with an operator, an asterisk only pushes traffic away. When a client is in a queue and listens to music and assurances of how important and valuable he is, all this time we are creating an audio stream for him on the fly. If we have 50 people in a queue, we have to create 50 audio streams for them on the fly, and send these streams to clients already (this is simple, in practice they are often different queues, different IVRs, etc., that is, one stream you can't give it all at once, as you did at some telephone stations).
It is quite expensive to convert call records (or voice mail) to mp3. But if there is a desire to listen to it in the browser / on a working computer, and not just from the phone, then this will not go away. And the desire is there. Yes, and space on the disk again saved.
The web interface is even more expensive. All sorts of reports and realtime statistics is a black hole in resources. Everywhere, wherever possible, a sea of agi-shek is stumbled, who write logs and collect statistics for its further use in all sorts of reports. About 5MB of different data per call, including a full SIP-Trace call in case something was wrong.
When all this is processed, you can get a lot of useful information. “From which states did this agent call in the evening over the past 3 months?”, “What% of the missed calls did this department have?”, “Who does this customer call us this month?”, “What is the average percentage of SIP packet loss when calling Pakistan? ”and so on.
Each internal system of the company (CRM, advertising management, fronted) periodically requests all kinds of realtime statistics. For example, the frontend of the project yaturist.ru shows the phones by which you can talk to the operator only if the queue of calls for this project is currently serviced by at least 1 agent. In other cases, the form is shown to submit the application in electronic form.
The admin of each project can also do a lot of non-trivial things through XMLRPC calls. For example, agents who better serve customers receive a higher priority when servicing the queue, but after processing a certain daily sales limit, they receive a lower priority and receive calls only if there is no one left. Thus, they have to work more thoroughly with each client, and not “take it at the expense of turnover”. Calls of VIP-clients come only to operators having the right to work with them, and if they are not there, then the best operators available online. And all this, on the basis of constantly requested statistics, is constantly “wound up” from the depths of these very systems by means of a heap of XLMRPC requests, constantly (“on the fly”) “twisting” the configuration of an asterisk (in MySQL).
If you disable reports and statistics, turn off the recording of conversations / voice mail and music on hold, temporarily block XMLRPC, in theory, even at peak times, we could run it all on one node, and there would be resources left. But ... if we would have done this, it would have lost its meaning, because, in my opinion, the asterisk is just perfect for creating such deep integrations with business needs that can be constantly “docked out” simultaneously with the development of the company. As practice has shown, it is a platform on the basis of which you can build anything from mini-ATS for 3 people to huge installations of almost any level of complexity.
Conclusion
This is rather an overview article, many technical details were left behind the scenes. We are all too different, I do not know what exactly you will be interested. If you are interested in this topic, ask questions. I am pleased to answer or even describe the technical details of interest in a separate article.
Source: https://habr.com/ru/post/145400/
All Articles