WebSphere Application Server application server topologies for high availability
Hello, Habr!
In this article, I want to tell you what approaches there are to ensure the resiliency and scalability of IBM's WebSphere Application Server 7 application server infrastructure.
First, some terminology to be used:
High availability is a system design method that allows you to achieve a high level of system availability over a period of time.
')
For business systems, high availability implies creating redundancy in critical business systems. Then the failure of one component, whether it is a failure of the router or a network card or a rollgram component, will not cause the application to fail.
Accessibility is generally expressed as a percentage or “nines.”
A = MTBF / (MTBF + MTTR).
90% (“one nine”) - 16.8 hours of downtime per week
99% ("two nines") - 1.7 hours of inactivity per week
99.9% ("three nines") - 8.8 hours of downtime per year
99.99% ("four nines") - 53 minutes of downtime per year
MTBF (English Mean time between failures) - The average duration of work between stops, that is, it shows what the average time between failures per failure.
MTTR (English Mean Time to Restoration) - the average time required to restore normal operation after a failure occurs.
SPOF (English single point of failure) - part of the system, which in case of failure makes the system inaccessible.
WAS - J2EE IBM application server. There are several delivery options:
0. Community Edition is an open source Apache Geronimo project;
1. Express - 1 node / 1 application server;
2. Base - 1 node / n application servers;
3. Network Deployment (ND) - includes a set of components for building a scalable and fault-tolerant infrastructure from a large number of application servers;
4. and several other specific options (for z / OS, Hypervisor Edition, Extended Deployment).
Further we will consider everything that is connected with exactly the version of Network Deployment 7 (WAS ND). At the moment there are already versions 8.0 and 8.5, but the approaches described in the article are applicable to them.
Key terms related to Network Deployment topologies:
Cell - An organizational unit that includes a deployment manager (Deployment Manager) and several nodes (Node). The deployment manager manages the nodes through node agents.
A node consists of a node agent, which, as we already understand, is used for management, and one or several application servers (Application Server).
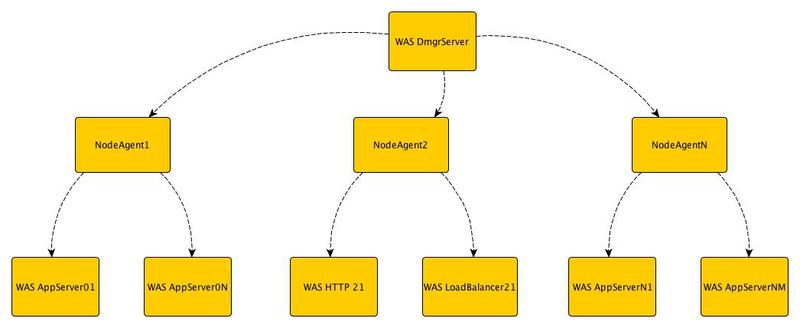
This hierarchy (Cell / Node / Server) helps to organize all the many servers and group them according to the functionality and availability requirements.
Application Server - JVM 5th Java EE specification (WAS 8 and 8.5 versions comply with Java EE 6 specifications)
Profile - a set of application server settings that are applied when it is launched. When you start an instance of a JVM, its environment settings are read from a profile and the type that the application server will perform depends on its type. The deployment manager, node agent, application server are private examples of profiles. Later in the article we will look at why and when to use different profiles and how they interact together, and what they can achieve.
The stand-alone profile differs from the federated one in that the management of several stand-alone profiles is performed from various administrative consoles, and the federated profiles are managed from a single point, which is much more convenient and faster.
So, based on the objectives of ensuring high availability of some business system running on the infrastructure of application servers, we need to build an infrastructure that will ensure that these requirements are met.
Level i
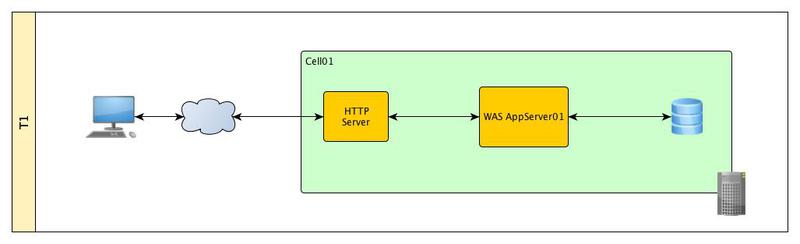
Standard three-tier architecture. We have one physical / virtual server on which the stand-alone WAS profile with its administrative console, DBMS and HTTP server is located.
We list which points of failure are present in this configuration and from level to level we will try to eliminate them:
1. HTTP server;
2. Application server;
3. Database;
4. All software components that ensure the interaction of our server with other components of the software infrastructure (Firewall, LDAP, etc.)
5. Hardware.
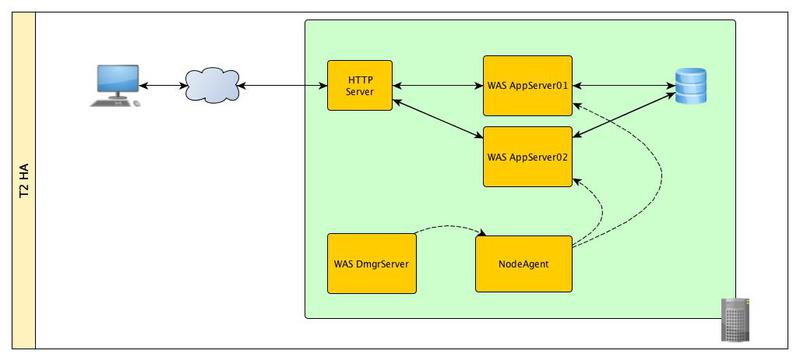
At this level, we eliminate a single point of failure - the application server. To do this, we need to create a cluster of other application servers and to manage them we will need two more components:
a) deployment manager;
b) management agent.
The deployment manager actually performs the function of unifying the administrative consoles of all application servers that are under its control. When changing the configurations of one or several servers, the settings are “descended” from the deployment manager to the servers by means of management agents.
In the event of a failure of one of the application servers, HAManager will automatically recover all data on the second server.

At this level, we can close several points of failure at once - the HTTP server and the physical server on which the application servers are spinning. To do this, we will move our database outside of our physical servers. Already on 2 servers we will deploy 2 nodes and in each of them we will create a couple of application servers. And integrate all the servers into a single cluster. In the event of a failure of one of the physical servers, the data and application states will be restored on the second system. In addition, using a load balancer (another type of profile), we can distribute incoming requests between systems and thus distribute the load and improve the performance of our applications. Applying this topology we get a new possible point of failure - load balancer.
We will supplement level III with a backup load balancer and, in addition, ensure the reliability of our database. We will not consider the mezanisms of database clustering in detail, since they themselves deserve a separate article.
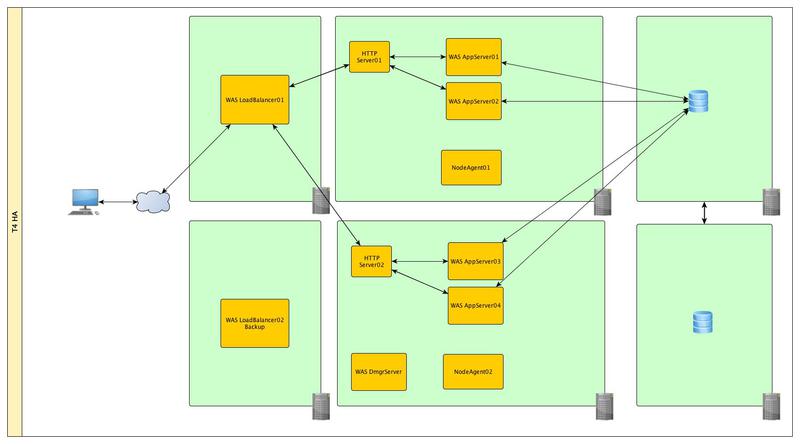
And we will duplicate the entire infrastructure with the final chord and move it far away in case our data center is flooded
In addition to this, it may not be superfluous to bring our Front-end servers to the DMZ zone.
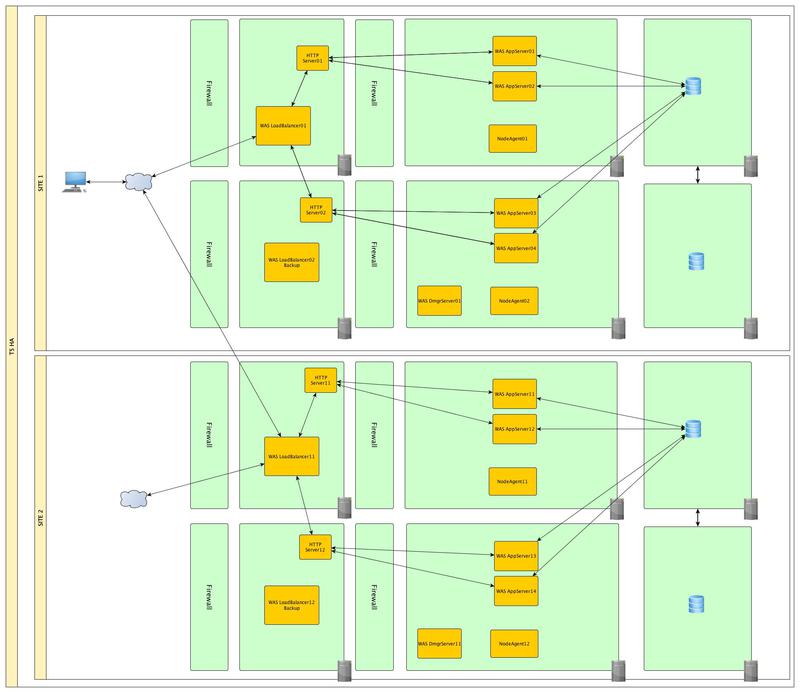
As we see, ensuring the continuous operation of critical business systems can be VERY expensive and before starting the construction of such solutions it is necessary to evaluate all the risks and readiness for implementation.
Thanks for attention.
In this article, I want to tell you what approaches there are to ensure the resiliency and scalability of IBM's WebSphere Application Server 7 application server infrastructure.
First, some terminology to be used:
High availability is a system design method that allows you to achieve a high level of system availability over a period of time.
')
For business systems, high availability implies creating redundancy in critical business systems. Then the failure of one component, whether it is a failure of the router or a network card or a rollgram component, will not cause the application to fail.
Accessibility is generally expressed as a percentage or “nines.”
A = MTBF / (MTBF + MTTR).
90% (“one nine”) - 16.8 hours of downtime per week
99% ("two nines") - 1.7 hours of inactivity per week
99.9% ("three nines") - 8.8 hours of downtime per year
99.99% ("four nines") - 53 minutes of downtime per year
MTBF (English Mean time between failures) - The average duration of work between stops, that is, it shows what the average time between failures per failure.
MTTR (English Mean Time to Restoration) - the average time required to restore normal operation after a failure occurs.
SPOF (English single point of failure) - part of the system, which in case of failure makes the system inaccessible.
WAS - J2EE IBM application server. There are several delivery options:
0. Community Edition is an open source Apache Geronimo project;
1. Express - 1 node / 1 application server;
2. Base - 1 node / n application servers;
3. Network Deployment (ND) - includes a set of components for building a scalable and fault-tolerant infrastructure from a large number of application servers;
4. and several other specific options (for z / OS, Hypervisor Edition, Extended Deployment).
Further we will consider everything that is connected with exactly the version of Network Deployment 7 (WAS ND). At the moment there are already versions 8.0 and 8.5, but the approaches described in the article are applicable to them.
Key terms related to Network Deployment topologies:
Cell - An organizational unit that includes a deployment manager (Deployment Manager) and several nodes (Node). The deployment manager manages the nodes through node agents.
A node consists of a node agent, which, as we already understand, is used for management, and one or several application servers (Application Server).
This hierarchy (Cell / Node / Server) helps to organize all the many servers and group them according to the functionality and availability requirements.
Application Server - JVM 5th Java EE specification (WAS 8 and 8.5 versions comply with Java EE 6 specifications)
Profile - a set of application server settings that are applied when it is launched. When you start an instance of a JVM, its environment settings are read from a profile and the type that the application server will perform depends on its type. The deployment manager, node agent, application server are private examples of profiles. Later in the article we will look at why and when to use different profiles and how they interact together, and what they can achieve.
The stand-alone profile differs from the federated one in that the management of several stand-alone profiles is performed from various administrative consoles, and the federated profiles are managed from a single point, which is much more convenient and faster.
Formulation of the problem
So, based on the objectives of ensuring high availability of some business system running on the infrastructure of application servers, we need to build an infrastructure that will ensure that these requirements are met.
Level i
Standard three-tier architecture. We have one physical / virtual server on which the stand-alone WAS profile with its administrative console, DBMS and HTTP server is located.
We list which points of failure are present in this configuration and from level to level we will try to eliminate them:
1. HTTP server;
2. Application server;
3. Database;
4. All software components that ensure the interaction of our server with other components of the software infrastructure (Firewall, LDAP, etc.)
5. Hardware.
Level II
At this level, we eliminate a single point of failure - the application server. To do this, we need to create a cluster of other application servers and to manage them we will need two more components:
a) deployment manager;
b) management agent.
The deployment manager actually performs the function of unifying the administrative consoles of all application servers that are under its control. When changing the configurations of one or several servers, the settings are “descended” from the deployment manager to the servers by means of management agents.
In the event of a failure of one of the application servers, HAManager will automatically recover all data on the second server.
Level III
At this level, we can close several points of failure at once - the HTTP server and the physical server on which the application servers are spinning. To do this, we will move our database outside of our physical servers. Already on 2 servers we will deploy 2 nodes and in each of them we will create a couple of application servers. And integrate all the servers into a single cluster. In the event of a failure of one of the physical servers, the data and application states will be restored on the second system. In addition, using a load balancer (another type of profile), we can distribute incoming requests between systems and thus distribute the load and improve the performance of our applications. Applying this topology we get a new possible point of failure - load balancer.
Level VI
We will supplement level III with a backup load balancer and, in addition, ensure the reliability of our database. We will not consider the mezanisms of database clustering in detail, since they themselves deserve a separate article.
Level V
And we will duplicate the entire infrastructure with the final chord and move it far away in case our data center is flooded
In addition to this, it may not be superfluous to bring our Front-end servers to the DMZ zone.
Total
As we see, ensuring the continuous operation of critical business systems can be VERY expensive and before starting the construction of such solutions it is necessary to evaluate all the risks and readiness for implementation.
Thanks for attention.
Source: https://habr.com/ru/post/145308/
All Articles