Data Modeling in MongoDB
 One of MongoDB’s most-advertised features is flexibility. I myself have repeatedly emphasized this in countless conversations about MongoDB. However, flexibility is a double-edged sword: more flexibility means a wider choice of data modeling solutions. However, I like the flexibility that MongoDB provides; I just need to keep some recommendations in mind before I start developing a data model.
One of MongoDB’s most-advertised features is flexibility. I myself have repeatedly emphasized this in countless conversations about MongoDB. However, flexibility is a double-edged sword: more flexibility means a wider choice of data modeling solutions. However, I like the flexibility that MongoDB provides; I just need to keep some recommendations in mind before I start developing a data model.In this article, we will look at how to model a structure containing mailing lists and data about the people who are included in these lists.
The following are the requirements:
')
- A person may have one or more e-mail addresses;
- A person can be on any number of mailing lists;
- A person can choose any name for any mailing list in which he is.
Strategy "without embedding"
Let's see what our data model will look like if no data is embedded anywhere.
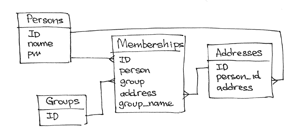
We have People subscribers with names and passwords:
{ _id: PERSON_ID, name: " ", pw: " " } We have a collection of Addresses addresses in which each document contains an e-mail address and a link to a specific subscriber:
{ _id: ADDRESS_ID, person: PERSON_ID, address: "vpupkin@gmail.com" } We have Groups , each of which contains only a group identifier (it, of course, may contain other data, but we specifically omit this point in order to concentrate on subscriptions)
{ _id: GROUP_ID } Finally, we have a collection of Membership subscriptions. Each Subscription brings people to the Groups, in addition, contains the name that the person has chosen for this Group, and a link to the e-mail address that he wants to use to receive the newsletter in this Group:
{ _id: MEMBERSHIP_ID, person: PERSON_ID, group: GROUP_ID, address: ADDRESS_ID, group_name: "" } This data model is understandable, easy to develop, and easy to maintain. We have created a model that is convenient to use in a relational database. However, we did not take into account the MongoDB document-oriented approach at all. Let's take a look at what we will do to get, for example, the e-mail addresses of all members of one Group, having one known e-mail address and the name of this Group:
- In the Addresses collection by the well-known e-mail, we find
PERSON_ID; - In the Memberships collection, using the received
PERSON_IDand the well-known name of the Group, we findGROUP_ID; - Again in the Memberships collection, by the received
GROUP_IDwe find the list of Subscriptions of this Group; - And finally, from the Addresses collection on
ADDRESS_ID, after passing through each Subscription from the received list, we get a list of e-mail addresses.
Slightly complicated, isn't it?
All-built strategy
Now consider the case when all the data is embedded in one document. To do this, we will take all the Group Subscriptions and embed them in the Group model. With a plus in each Subscription we will integrate information about the Subscriber and his e-mail addresses:
{ _id: GROUP_ID, memberships: [{ address: "vpupkin@gmail.com", name: " ", pw: " ", person_addresses: ["vpupkin@gmail.com", "vpupkin@mail.ru", ...], group_name: "" }, ...] } The point of embedding all linked data in one document is that now some data queries are much easier to do. The request from the previous part of the article becomes quite simple (remember, we need, having one known e-mail address and the name of the Group, find out the e-mail addresses of the other members of this Group):
- In the Groups collection, we find the Group containing the Subscription, in which
group_namematches the known name of the Group and theperson_addressesarray contains the e-mail known to us; - Let us analyze the resulting document to retrieve the remaining e-mail addresses.
Much easier. But what if Subscriber wants to change his name or password? We will have to change his name or password in each built-in Subscription of each Group in which this Subscriber consists. This also applies to adding a new e-mail address or deleting an existing e-mail address from the
person_addresses array. Such moments tell us about a certain character of this model: it is well suited for specific requests (because all the necessary data is already inside, such as pre-join), but it can become nightmares in the long run in terms of maintenance.Strategy of "partial embedding"
The approach that I most often recommend is to start thinking about the data model without embedding. Once you have a draft model, you can begin to distinguish cases where embedding makes sense. As a rule, these are one-to-many relationships.
For example, a few email addresses from the Addresses collection belong to the same Subscriber (they also participate in the Subscription model) and usually change less frequently. Therefore, we will combine them into an array and add a Subscriber to our model, making it a bit similar to the mental model.
Each Subscription is associated with a specific Subscriber and a specific Group, so you can embed Subscriptions in both the Subscriber model and the Group model. In such cases, it is important to think about both the data access model and the size of the embedded data. We expect that people are unlikely to subscribe to mailings from more than 1000 different groups, and a single group, in turn, is also unlikely to reach more than 1000 subscribers. In this case, the numbers do not tell us anything useful. However, our data access model, on the contrary, tells us that when displaying on a screen, it is necessary to see all the subscriptions of a specific person. To simplify the query, we embed Subscriptions in the Subscriber model. The advantage is that the list of e-mail addresses of the Subscriber is in the Subscriber model, and in the Subscription one of the addresses of this list is used, and if we need to change or delete the e-mail address, it can be done in one place.
Now our data model looks like this:
{ _id: PERSON_ID, name: " ", pw: " ", addresses: ["vpupkin@gmail.com", "vpupkin@mail.ru", ...], memberships: [{ address: "vpupkin@gmail.com", group_name: "", group: GROUP_ID }, ...] } This is a Subscriber model, besides it there is also a Group model, which is identical to the one that is considered in the description of the “without embedding” strategy.
The query that we discussed above will now look like this:
- In the People collection, we find a Subscriber with the desired e-mail address, among whose Subscriptions there is a Subscription with the desired name;
- Using the
GROUP_IDfound Subscription, find in the People collection the other Subscribers of this Group and take their e-mail addresses directly from the Subscription.
This is still almost as simple as when everything is built in, but now our data model is much cleaner and easier to maintain. Hope this article was helpful to you.
From the translator: in general, this is a rather free translation and was made purely for personal purposes, so all the blows, please, in a personal. I will also make a reservation that some concepts have been replaced for subjective reasons, some points have been omitted, since they did not play a significant role for the transmission of the essence. In any case, please refer to the original.
Source: https://habr.com/ru/post/144798/
All Articles