ZooKeeper or write distributed locking service
disclaimer It so happened that last month I understood ZooKeeper, and I had a desire to systematize what I learned, the actual post about it, and not about the service of locks, as one might think from the name. Go!
When moving from multithreaded programming to programming of distributed systems, many standard techniques stop working. One of these techniques are locks (synchronized), since their scope is limited to one process, therefore, they not only do not work on different nodes of the distributed system, but also not between different instances of the application on the same machine; it turns out that you need a separate mechanism for locking.
It is reasonable to demand from the distributed service of locks:
ZooKeeper will help us to create such a service.
')
 Wikipedia says that ZooKeeper is a distributed configuration and synchronization service , I don’t know about you, but this definition reveals little to me. Looking back at my experience, I can give an alternative definition of ZooKeeper, this is a distributed key / value store with the following properties :
Wikipedia says that ZooKeeper is a distributed configuration and synchronization service , I don’t know about you, but this definition reveals little to me. Looking back at my experience, I can give an alternative definition of ZooKeeper, this is a distributed key / value store with the following properties :
Acquaintance with an unfamiliar system must begin first with the API that it offers, so
These operations can be divided into the following groups.
Callback - read-only operations, to which you can specify callbacks, callback will work when the requested entity changes. Callback will work no more than once; in the case when you need to constantly monitor the value, you must constantly re-sign in the event handler .
CAS - write requests. The problem of competitive access in ZooKeeper has been resolved via compare-and-swap : with each znode its version is stored, if it is changed, it must be indicated, if the znode has already been changed, then the version does not match and the client will receive a corresponding exception. Operations from this group require specifying the version of the object being changed.
create - creates a new znode (key / value pair) and returns a key. It seems odd that a key is returned if it is specified as an argument, but the fact is that you can specify a prefix as a key and say that znode is consistent, then you will add a aligned number to the prefix and the result will be used as a key. It is guaranteed that by creating successive znode with the same prefix, the keys will form an increasing (in a lexico-graphic sense) sequence .
In addition to consecutive znode, you can create ephemeral znode, which will be deleted as soon as the client created them to disconnect (recall that the connection between the cluster and the client in ZooKeeper is kept open for a long time). Ephemeral znode can not have children.
Znode can be both ephemeral and consistent.
sync - synchronizes the cluster node to which the client is connected, with the master. On good should not be caused, as synchronization happens quickly and automatically. About when to call it, will be written below.
Based on sequential ephemeral znode and subscriptions for their removal, you caneasily create a system of distributed locks.
In fact, everything is invented before us - go to the ZooKeeper website in the recipe section and look for the blocking algorithm there:
Since, in the event that any operation fails while ZooKeeper is running, we cannot find out if the operation has passed or not , we need to make this check at the application level. Guid is needed just for this: knowing it and requesting children, we can easily determine whether we have created a new node or not, and the operation should be repeated.
By the way, I did not say, but I think you already guessed that to calculate the suffix for a consecutive znode, not a unique sequence for the prefix is used, but a unique sequence for the parent in which the znode will be created.
In theory, it would be possible to finish it, but as practice has shown, the most interesting begins - wtf 'ki. By wtf, I mean the divergence of my intuitive ideas about the system with its real behavior, attention, wtf does not carry a value judgment, and I also understand perfectly why the creators of ZooKeeper went to such architectural solutions.
Any API method can throw a checked exception and oblige you to handle it. This is not usual, but correct, since the first rule of distributed systems is that the network is not reliable. One of the exceptions that can fly is the loss of the connection (network blinking). You should not confuse the loss of a connection with a cluster node (CONNECTIONLOSS), during which the client will restore it with the saved session and callbacks (connect to another or wait), and forcefully close the connection from the cluster and the loss of all callbacks (SESSIONEXPIRED), in this case the task of restoring the context falls on the programmer’s shoulders. But we have moved away from the topic ...
How to handle winks? In fact, when opening a connection with a cluster, we indicate a callback, which is called repeatedly, not just once, like the others, and which delivers events about the loss of the connection and its restoration . It turns out when the connection is lost, you need to pause the calculations and continue them when the desired event arrives.
Doesn't this remind you of anything? On the one hand - events, on the other - the need to "play" with the flow of the program, in my opinion somewhere near continuation and monads.
In general, I designed the steps of the program in the form:
where is executor
By adding the necessary combinators you can build the following programs, somewhere using the idempotency of the steps, somewhere clearly clearing up the garbage:
When implementing the Executor, I added wrapper functions to the ZooKeeper class so that it is the handler for all events and decides for itself which Watcher (event handler to call). Inside the implementation, I put three BlockingQueues and three threads that read them, and it eventually turned out that when an event arrives, it is added to the eventQueue, thus the stream almost instantly returns to the inside of ZooKeeper, by the way, inside ZooKeeper, all Watchers work in one thread , therefore, it is possible that the processing of one event blocks all the others and ZooKeeper itself . Secondly, taskQueues are added to Task'i along with arguments. The processing of these queues (eventQueue and taskQueue) is allocated downstream, eventThread and taskThread, respectively, these threads read their own queues and wrap each incoming object into Job'u and put it in the jobQueue with which its thread is connected, the actual trigger code of the task or handler messages. In the case of a connection failure, the taskThread thread is suspended, and in the case of a network raise, it is resumed. Execution of the task code and handlers in one thread allows you not to worry about locks and facilitates business logic.
We can say that in ZooKeeper the server (cluster) is the main one, and the customers have almost no rights. Sometimes it comes to the absolute, for example ... In the ZooKeeper configuration there is such a parameter as session timeout, it determines how much the connection between the cluster and the client can disappear, if the maximum is exceeded, the session of this client will be closed and all ephemeral znode of this client will be deleted; if the connection is still restored, the client will receive a SESSIONEXPIRED event. So, the client at connection loss (CONNECTIONLOSS) and exceeding session timeout stupidly waits and does nothing, although, according to the idea, he could guess that the session was dead and SESSIONEXPIRED to throw its handlers.
Because of this behavior, the developer at some time to tear his hair out, say, you raised the ZooKeeper server and try to connect to it, but you made a mistake in the config and knocked at the wrong address, or not on that port, then, according to the behavior described above , you will just wait for the client to go to the CONNECTED state and not get any error message, as would be the case with MySQL or something similar.
Interestingly, such a script allows you to safely update ZooKeeper on production:
By the way, it is because of this behavior that I pass to the Executor Timer, which cancels the execution of the Task if we are unable to connect for too long.
Suppose you implemented locks according to the algorithm described above and started this case in highload production, where, let's say you take 10MM locks per day. Somewhere in a year you will find that you are in hell - locks will stop working. The fact is that after a year, the znode _locknode_ counter cversion overflows and violates the principle of a monotonously increasing sequence of names of consecutive znode , and our implementation of locks is based on this principle.
What to do? It is necessary to periodically delete / re-create _locknode_ - while the counter associated with it is reset and the principle of monotonous sequence is broken again, but the fact is that znode can be deleted only when it has no children , and now guess why the cversion reset from _locknode_, when there are no children in it does not affect the blocking algorithm.
When ZooKeeper returned OK to the write request, this means that the data was enrolled to quorum (most machines in the cluster, in the case of 3 machines, the quorum consists of 2x), but when reading the user receives data from the machine to which he connected. That is, it is possible that the user receives old data.
In the case when clients do not communicate except through ZooKeeper, this is not a problem, since all operations in ZooKeeper are strictly ordered and then there is no way to know that the event occurred except how to wait for it. Guess yourself why it means that everything is good. In fact, the client may know that the data was updated, even if no one told him - in the case when he made the changes himself, but ZooKeeper supports read your write consistency , so this is not a problem either.
But still, if one ZooKeeper learned about a change in a part of the data through the communication channel, a forced sync can help him - for this the sync command is needed.
Most distributed key / value stores use distribution to store large amounts of data. As I already wrote, the data that ZooKeeper keeps in itself should not exceed the size of the RAM, it is asked why it is distributed - it is used to ensure reliability. Remembering the need to gain a record quorum, it is not surprising that there is a 15% drop in performance when using a cluster of three machines, compared with one machine.
Another feature of ZooKeeper is that it provides persistence - for it, too, is necessary because during the processing of a request, the recording time on the disc is included.
And the final impact on performance is due to the strict ordering of requests - in order to ensure that all write requests go through the same cluster machine.
I tested on a local laptop, yes, yes it strongly resembles:
but it is obvious that ZooKeeper shows itself best in a configuration from one node, with a fast disk and a small amount of data, so my X220 with SSD and i7 was perfect for this. I tested mostly write requests.
The performance ceiling was somewhere around 10K operations per second with intensive recording, recording takes from 1ms, therefore, from the point of view of a single client, the server can run no faster than 1K operations per second.
What does it mean? In conditions when we do not run into the disk (ssd utilization at the level of 10%, for fidelity, I also tried to place the data in memory via ramfs - I received a slight increase in performance), we run into cpu. So, it turned out that ZooKeeper is only 2 times slower than the numbers that its creators indicated on the site, which is not bad, considering that they know how to squeeze everything out of it.
Despite everything I've written here, ZooKeeper is not as bad as it may seem. I like its conciseness (only 7 teams), I like the way it pushes and directs its programmer API to the correct approach in the development of distributed systems, namely, at any moment everything can fall, so every operation should leave the system in a consistent state . But these are my impressions, they are not as important as the fact that ZooKeeeper well solves the tasks for which it was created, including: storing cluster configs, monitoring the status of a cluster (number of connected nodes, status of nodes), synchronizing nodes (blocking , barriers) and communication of nodes of a distributed system (a-la jabber).
I will list again what you should keep in mind when developing with ZooKeeper:
Returning to the blocking algorithm described above, I can say that it does not work, it works more precisely exactly as long as the actions inside the critical section occur on the same and only the same ZooKeeper cluster that is used for blocking. Why is that? - Try to guess yourself. And in the next article I will write how to make distributed locks more honest and expand the class of operations inside the critical section to any key / value storage with CAS support.
zookeeper.apache.org
outerthought.org/blog/435-ot.html
highscalability.com/zookeeper-reliable-scalable-distributed-coordination-system
research.yahoo.com/node/3280
When moving from multithreaded programming to programming of distributed systems, many standard techniques stop working. One of these techniques are locks (synchronized), since their scope is limited to one process, therefore, they not only do not work on different nodes of the distributed system, but also not between different instances of the application on the same machine; it turns out that you need a separate mechanism for locking.
It is reasonable to demand from the distributed service of locks:
- operability in the conditions of network blinking (the first rule of distributed systems -
not to speak about distributed systems to anyone thenetwork is unreliable) - no single point of failure
ZooKeeper will help us to create such a service.
')
Wikipedia says that ZooKeeper is a distributed configuration and synchronization service , I don’t know about you, but this definition reveals little to me. Looking back at my experience, I can give an alternative definition of ZooKeeper, this is a distributed key / value store with the following properties :- key space forms a tree (a hierarchy similar to the file system)
- values can be contained in any node of the hierarchy, and not only in the leaves (as if the files would also be directories), the hierarchy node is called znode
- there is a bidirectional connection between the client and the server, therefore, the client can be signed as a change in a specific value or part of the hierarchy
- it is possible to create a temporary key / value pair that exists while the client who created it is connected to the cluster
- all data should be stored in memory
- resistance to death of non-critical number of cluster nodes
Acquaintance with an unfamiliar system must begin first with the API that it offers, so
Supported operations
| exists | checks for the existence of znode and returns its metadata |
| create | creates znode |
| delete | removes znode |
| getData | gets data associated with znode |
| setData | associates new data with znode |
| getChildren | gets children of the specified znode |
| sync | waiting for the synchronization of the cluster node to which we are connected, and the master. |
These operations can be divided into the following groups.
| callback | CAS | |
| exists | delete | |
| getData | setData | |
| getChildren | create | |
| sync |
Callback - read-only operations, to which you can specify callbacks, callback will work when the requested entity changes. Callback will work no more than once; in the case when you need to constantly monitor the value, you must constantly re-sign in the event handler .
CAS - write requests. The problem of competitive access in ZooKeeper has been resolved via compare-and-swap : with each znode its version is stored, if it is changed, it must be indicated, if the znode has already been changed, then the version does not match and the client will receive a corresponding exception. Operations from this group require specifying the version of the object being changed.
create - creates a new znode (key / value pair) and returns a key. It seems odd that a key is returned if it is specified as an argument, but the fact is that you can specify a prefix as a key and say that znode is consistent, then you will add a aligned number to the prefix and the result will be used as a key. It is guaranteed that by creating successive znode with the same prefix, the keys will form an increasing (in a lexico-graphic sense) sequence .
In addition to consecutive znode, you can create ephemeral znode, which will be deleted as soon as the client created them to disconnect (recall that the connection between the cluster and the client in ZooKeeper is kept open for a long time). Ephemeral znode can not have children.
Znode can be both ephemeral and consistent.
sync - synchronizes the cluster node to which the client is connected, with the master. On good should not be caused, as synchronization happens quickly and automatically. About when to call it, will be written below.
Based on sequential ephemeral znode and subscriptions for their removal, you can
Distributed locking system
In fact, everything is invented before us - go to the ZooKeeper website in the recipe section and look for the blocking algorithm there:
- Create ephemeral serial znode using "_locknode_ / guid-lock-" as a prefix, where _locknode_ is the name of the resource that is being blocked, and guid is the newly generated guid
- Get the list of _locknode_ children without a subscription to the event
- If the znode created in the first step in the key has a minimum numeric suffix: exit the algorithm - we have captured the resource
- Otherwise, sort the list of children by the suffix and call the exists with a callback on the znode, which is in the resulting list before what we created in step 1
- If you get false, go to step 2, otherwise wait for the event and go to step 2
To verify the assimilation of the material, try to understand yourself, in descending or ascending order, you need to sort the list in step 4.
Since, in the event that any operation fails while ZooKeeper is running, we cannot find out if the operation has passed or not , we need to make this check at the application level. Guid is needed just for this: knowing it and requesting children, we can easily determine whether we have created a new node or not, and the operation should be repeated.
By the way, I did not say, but I think you already guessed that to calculate the suffix for a consecutive znode, not a unique sequence for the prefix is used, but a unique sequence for the parent in which the znode will be created.
WTF
In theory, it would be possible to finish it, but as practice has shown, the most interesting begins - wtf 'ki. By wtf, I mean the divergence of my intuitive ideas about the system with its real behavior, attention, wtf does not carry a value judgment, and I also understand perfectly why the creators of ZooKeeper went to such architectural solutions.
WTF # 1 - turn the code inside out
Any API method can throw a checked exception and oblige you to handle it. This is not usual, but correct, since the first rule of distributed systems is that the network is not reliable. One of the exceptions that can fly is the loss of the connection (network blinking). You should not confuse the loss of a connection with a cluster node (CONNECTIONLOSS), during which the client will restore it with the saved session and callbacks (connect to another or wait), and forcefully close the connection from the cluster and the loss of all callbacks (SESSIONEXPIRED), in this case the task of restoring the context falls on the programmer’s shoulders. But we have moved away from the topic ...
How to handle winks? In fact, when opening a connection with a cluster, we indicate a callback, which is called repeatedly, not just once, like the others, and which delivers events about the loss of the connection and its restoration . It turns out when the connection is lost, you need to pause the calculations and continue them when the desired event arrives.
Doesn't this remind you of anything? On the one hand - events, on the other - the need to "play" with the flow of the program, in my opinion somewhere near continuation and monads.
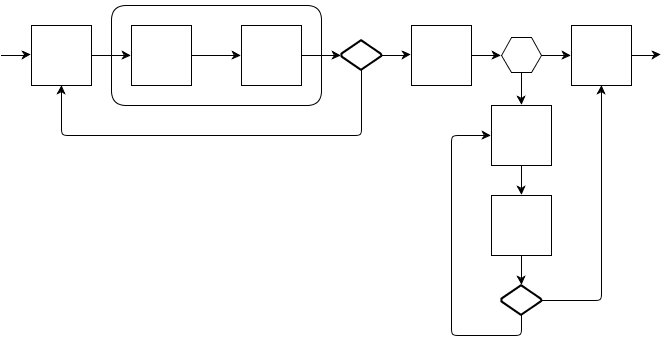
In general, I designed the steps of the program in the form:
public interface Task { Task continueWith(Task continuation); // void run(Executor context, Object arg); // void error(Executor context, Exception error); // , - } where is executor
public interface Executor { void execute(Task task, Object arg, Timer timeout); // timeout / TimeoutException error , real-time } By adding the necessary combinators you can build the following programs, somewhere using the idempotency of the steps, somewhere clearly clearing up the garbage:
- the square is a useful operation, and the arrow is the execution flow and / or error flow
- diamond - combinator, which ignores the specified errors and repeats the last useful operation
- honeycomb - a combinator that performs operation A in the case of a normal flow of execution, and operation B in the case of the specified error
- a rounded parallelepiped is a combinator that allows a successful execution flow to itself, and an erroneous one immediately throws it away
When implementing the Executor, I added wrapper functions to the ZooKeeper class so that it is the handler for all events and decides for itself which Watcher (event handler to call). Inside the implementation, I put three BlockingQueues and three threads that read them, and it eventually turned out that when an event arrives, it is added to the eventQueue, thus the stream almost instantly returns to the inside of ZooKeeper, by the way, inside ZooKeeper, all Watchers work in one thread , therefore, it is possible that the processing of one event blocks all the others and ZooKeeper itself . Secondly, taskQueues are added to Task'i along with arguments. The processing of these queues (eventQueue and taskQueue) is allocated downstream, eventThread and taskThread, respectively, these threads read their own queues and wrap each incoming object into Job'u and put it in the jobQueue with which its thread is connected, the actual trigger code of the task or handler messages. In the case of a connection failure, the taskThread thread is suspended, and in the case of a network raise, it is resumed. Execution of the task code and handlers in one thread allows you not to worry about locks and facilitates business logic.
WTF # 2 - main server
We can say that in ZooKeeper the server (cluster) is the main one, and the customers have almost no rights. Sometimes it comes to the absolute, for example ... In the ZooKeeper configuration there is such a parameter as session timeout, it determines how much the connection between the cluster and the client can disappear, if the maximum is exceeded, the session of this client will be closed and all ephemeral znode of this client will be deleted; if the connection is still restored, the client will receive a SESSIONEXPIRED event. So, the client at connection loss (CONNECTIONLOSS) and exceeding session timeout stupidly waits and does nothing, although, according to the idea, he could guess that the session was dead and SESSIONEXPIRED to throw its handlers.
Because of this behavior, the developer at some time to tear his hair out, say, you raised the ZooKeeper server and try to connect to it, but you made a mistake in the config and knocked at the wrong address, or not on that port, then, according to the behavior described above , you will just wait for the client to go to the CONNECTED state and not get any error message, as would be the case with MySQL or something similar.
Interestingly, such a script allows you to safely update ZooKeeper on production:
- turn off ZooKeeper - all clients go to the CONNECTIONLOSS state
- update ZooKeeper
- we turn on ZooKeeper, the connection with the server has been restored, but the server does not send SESSIONEXPIRED, since the time for the shutdown was relative to the server
By the way, it is because of this behavior that I pass to the Executor Timer, which cancels the execution of the Task if we are unable to connect for too long.
WTF # 3 - int overflow
Suppose you implemented locks according to the algorithm described above and started this case in highload production, where, let's say you take 10MM locks per day. Somewhere in a year you will find that you are in hell - locks will stop working. The fact is that after a year, the znode _locknode_ counter cversion overflows and violates the principle of a monotonously increasing sequence of names of consecutive znode , and our implementation of locks is based on this principle.
What to do? It is necessary to periodically delete / re-create _locknode_ - while the counter associated with it is reset and the principle of monotonous sequence is broken again, but the fact is that znode can be deleted only when it has no children , and now guess why the cversion reset from _locknode_, when there are no children in it does not affect the blocking algorithm.
WTF # 4 - quorum write, but not read
When ZooKeeper returned OK to the write request, this means that the data was enrolled to quorum (most machines in the cluster, in the case of 3 machines, the quorum consists of 2x), but when reading the user receives data from the machine to which he connected. That is, it is possible that the user receives old data.
In the case when clients do not communicate except through ZooKeeper, this is not a problem, since all operations in ZooKeeper are strictly ordered and then there is no way to know that the event occurred except how to wait for it. Guess yourself why it means that everything is good. In fact, the client may know that the data was updated, even if no one told him - in the case when he made the changes himself, but ZooKeeper supports read your write consistency , so this is not a problem either.
But still, if one ZooKeeper learned about a change in a part of the data through the communication channel, a forced sync can help him - for this the sync command is needed.
Performance
Most distributed key / value stores use distribution to store large amounts of data. As I already wrote, the data that ZooKeeper keeps in itself should not exceed the size of the RAM, it is asked why it is distributed - it is used to ensure reliability. Remembering the need to gain a record quorum, it is not surprising that there is a 15% drop in performance when using a cluster of three machines, compared with one machine.
Another feature of ZooKeeper is that it provides persistence - for it, too, is necessary because during the processing of a request, the recording time on the disc is included.
And the final impact on performance is due to the strict ordering of requests - in order to ensure that all write requests go through the same cluster machine.
I tested on a local laptop, yes, yes it strongly resembles:
 DevOps borat | 90% of devops which can be used in the same sentence. |
The performance ceiling was somewhere around 10K operations per second with intensive recording, recording takes from 1ms, therefore, from the point of view of a single client, the server can run no faster than 1K operations per second.
What does it mean? In conditions when we do not run into the disk (ssd utilization at the level of 10%, for fidelity, I also tried to place the data in memory via ramfs - I received a slight increase in performance), we run into cpu. So, it turned out that ZooKeeper is only 2 times slower than the numbers that its creators indicated on the site, which is not bad, considering that they know how to squeeze everything out of it.
Summary
Despite everything I've written here, ZooKeeper is not as bad as it may seem. I like its conciseness (only 7 teams), I like the way it pushes and directs its programmer API to the correct approach in the development of distributed systems, namely, at any moment everything can fall, so every operation should leave the system in a consistent state . But these are my impressions, they are not as important as the fact that ZooKeeeper well solves the tasks for which it was created, including: storing cluster configs, monitoring the status of a cluster (number of connected nodes, status of nodes), synchronizing nodes (blocking , barriers) and communication of nodes of a distributed system (a-la jabber).
I will list again what you should keep in mind when developing with ZooKeeper:
- master server
- the client is notified of the record only when data has hit the disk
- quorum write + read your writes consistency
- strict order
- at any moment everything can fall, therefore after each change the system should be in a consistent state
- in case of loss of communication, we are in a state in which the state of the last write operation is unknown
- explicit error handling (for me the best strategy is to use CPS)
About distributed locks
Returning to the blocking algorithm described above, I can say that it does not work, it works more precisely exactly as long as the actions inside the critical section occur on the same and only the same ZooKeeper cluster that is used for blocking. Why is that? - Try to guess yourself. And in the next article I will write how to make distributed locks more honest and expand the class of operations inside the critical section to any key / value storage with CAS support.
Several links to information on ZooKeeper
zookeeper.apache.org
outerthought.org/blog/435-ot.html
highscalability.com/zookeeper-reliable-scalable-distributed-coordination-system
research.yahoo.com/node/3280
Source: https://habr.com/ru/post/144708/
All Articles