Why are many agents better than one?
I would like to start my first pseudoscientific article with the words of the great inventor and the practice of Alan Turing: “In the absence of laws of behavior, which together would define our life, you cannot be as sure as in the absence of a complete list of action rules ...” he clearly knew that even the smallest could do great things. In many scientific publications, the work of multi-agent systems is compared with the work of people in an enterprise.
I don’t invent a bicycle, I just put the life of the workers in the figure. In any enterprise there is a director - who determines where it moves. Let's leave the director in the form of a user of our system. Human resources department - their task is to monitor employees, dismiss, hire, maintain personnel records. We select special agents for this, let them hire and dismiss workers. Coordinator agents are intermediaries between the top manager director and employees, who in turn will also be our agents.
It remains only to come up with, and what we will produce. The problem that needs to be solved is to help the director make the right decisions, and perhaps carry out some of them on his own. And the director of our department manages the archive, distributes documents to the repositories, based only on him one slave rules. The task of the workers is to preserve, understand, adapt and apply these rules. Thus, when initially filling out a certain amount of documents, employees must independently distribute new documents to the archives. And here multi-agent systems? In principle, there is nothing, if not for one fact. Documents must first be collected around the world from all desks, boxes, phones ... Then sort by type, then carry out, perhaps, the main thing - analysis and adaptation, and only then send it to the repository. It’s not known yet how to correctly analyze and adapt a decision, so we take a decision-making theory based on precedents. And we’ll extract some parameters - who, when, to whom, what passed, created. The “what” parameter is also not so obvious, so again we take an assumption - we express from the text only nouns, taking into account the frequency of their use in the text.
Next, it remains to determine the similarity of the new document with the already existing documents in the repository.
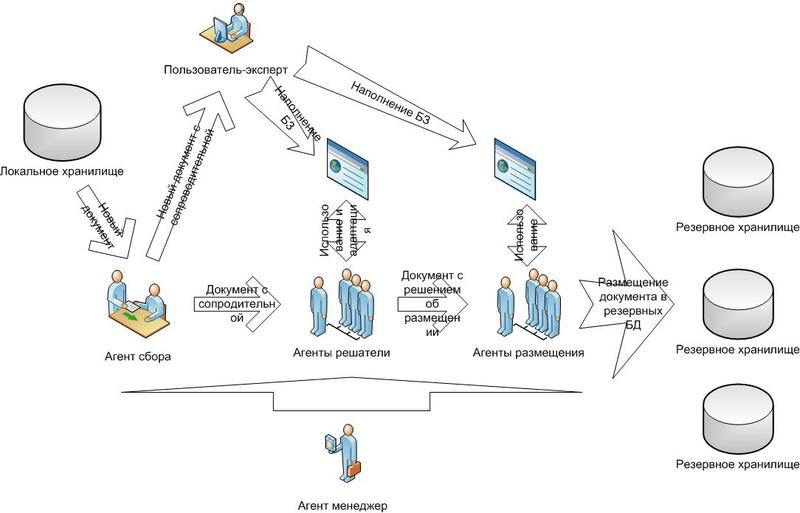
Total I selected the following participants of the process.
1) collection agents;
2) solvers analyzers agents;
3) the superuser - the expert and his agent;
4) agents responsible for storage;
5) coordinating agent
')
1) Simple software design tools are emerging that can move from the object-oriented programming paradigm to the agent-oriented programming paradigm (.NET, JADE, and others);
2) There is no need to write cross-platform applications, it is enough to write for each platform its agent;
3) Due to the large informatization of all processes at large enterprises, the implementation of content management systems, workflow systems and other information processing systems, difficulties arise in compiling information. Agent systems operate independently of each other. The activity of one agent does not directly depend on the activity of the entire system. The execution of the same task can be delivered to several agents simultaneously. This redundancy gives a greater guarantee for getting results.
4) Distribution of the solution of the problem to several agents allows you to parallelize the processing of information from different sources.
Task Description
I don’t invent a bicycle, I just put the life of the workers in the figure. In any enterprise there is a director - who determines where it moves. Let's leave the director in the form of a user of our system. Human resources department - their task is to monitor employees, dismiss, hire, maintain personnel records. We select special agents for this, let them hire and dismiss workers. Coordinator agents are intermediaries between the top manager director and employees, who in turn will also be our agents.
It remains only to come up with, and what we will produce. The problem that needs to be solved is to help the director make the right decisions, and perhaps carry out some of them on his own. And the director of our department manages the archive, distributes documents to the repositories, based only on him one slave rules. The task of the workers is to preserve, understand, adapt and apply these rules. Thus, when initially filling out a certain amount of documents, employees must independently distribute new documents to the archives. And here multi-agent systems? In principle, there is nothing, if not for one fact. Documents must first be collected around the world from all desks, boxes, phones ... Then sort by type, then carry out, perhaps, the main thing - analysis and adaptation, and only then send it to the repository. It’s not known yet how to correctly analyze and adapt a decision, so we take a decision-making theory based on precedents. And we’ll extract some parameters - who, when, to whom, what passed, created. The “what” parameter is also not so obvious, so again we take an assumption - we express from the text only nouns, taking into account the frequency of their use in the text.
Next, it remains to determine the similarity of the new document with the already existing documents in the repository.
Total I selected the following participants of the process.
1) collection agents;
2) solvers analyzers agents;
3) the superuser - the expert and his agent;
4) agents responsible for storage;
5) coordinating agent
')
Why precisely multiagent architecture for solving this problem?
1) Simple software design tools are emerging that can move from the object-oriented programming paradigm to the agent-oriented programming paradigm (.NET, JADE, and others);
2) There is no need to write cross-platform applications, it is enough to write for each platform its agent;
3) Due to the large informatization of all processes at large enterprises, the implementation of content management systems, workflow systems and other information processing systems, difficulties arise in compiling information. Agent systems operate independently of each other. The activity of one agent does not directly depend on the activity of the entire system. The execution of the same task can be delivered to several agents simultaneously. This redundancy gives a greater guarantee for getting results.
4) Distribution of the solution of the problem to several agents allows you to parallelize the processing of information from different sources.
Source: https://habr.com/ru/post/144415/
All Articles