Loading and storing data in an application with a complex database structure
When developing business applications, there is always the problem of storing data in the repository with the project. Especially this topic is relevant for corporate ERP, CRM, mnogabukav and so on systems.
What is it for:
Also, the problem of reliable data update on a working project, along with updating the model , is no less acute.
In our system, we used an approach that allows you to monitor data integrity, download and update, stores data in the repository and at the same time works quickly and reliably.
First , the data should be stored with versioned.
Secondly , the stored data must be human-readable, for example, to compare versions.
Third , the saved data should be easily loaded into a working system.
So, consider a typical ERP system with hundreds of interrelated entities, inheritance, hierarchical directories, and so on.
What solution does an inexperienced developer apply? Correctly, makes a database dump and stores it. I did it myself :)
')
What are the disadvantages of such a decision:
1. Binary backups are difficult / inefficiently stored in VCS
2. If the backup is large and textual - it's hard to figure out what's changed.
3. It is difficult for a person to read and search for something.
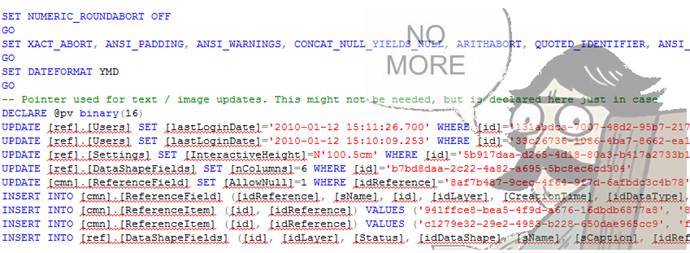
In general, it is inconvenient to store dumps / backups / Sql-scripts, it is even more inconvenient to understand them.
It is much more correct and convenient to store data in text structured, for example, in XML. As such, they are easy to read, diff, and stored in the VCS. Data is stored consistently both for creating new records and for updating existing ones.
In addition, MS SQL / Postgresql / Oracle can parse XML in native way, and MS SQL can also load it directly into tables. By and large, this was one of the main advantages of XML when choosing a storage format.
By the way, this is how Araxis Merge diff can show for XML files
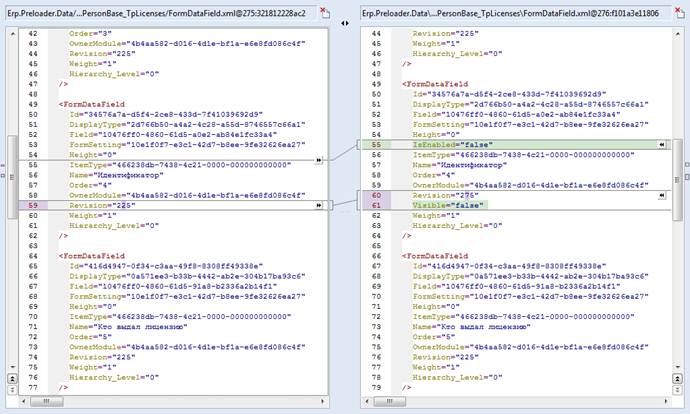
The only question that arises is how to load this happiness with regard to dependencies, foreign keys and interconnections?
Well ... you can do the simplest thing: delete all foreign keys, load the data, then return all the keys to the site . Again, this stage in my life has passed too :)
Solution Minuses:
1. Complex logic for deleting / creating keys
2. If the database structure is complex or the data volume is large - the process of creating / deleting keys can be long
3. And most importantly: when restoring keys, an error will appear only after ALL data is loaded , so there is no way to accurately determine the location of the error.
Reflecting on this topic, I came to the conclusion that it is not necessary to delete foreign keys and restrictions on loading. You just need to load the entity data in the correct order .
Thus it is necessary to consider:
1. Foreign keys (they are entity references)
2. Inheritance of entities
3. Hierarchical entities
4. Possible cycles
To solve these problems, I presented a set of entities in the form of a graph and applied Topological sorting . With its help, I sorted all loaded entities so that all the necessary data is already present at the time of loading any item.
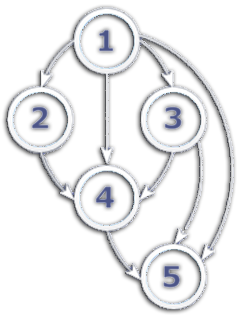
There are many implementations of this algorithm in the network, but I took the one that came with the ORM used. At the input it accepts an enumeration of objects and a method that connects them, at the output it receives a sorted list + out parameter with cycles, if any.
It looks like this:
For this algorithm to work, the main thing is to correctly represent the entity graph and its relationships.
In my case, the link connector looks like this:
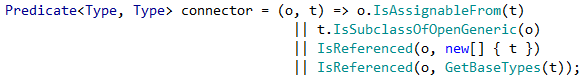
What is translated from ancient Moldavian means that type T depends on (has a directional relationship) type O if:
1. T heir O
2. T is a heir or closed generic type of open generic type O
3. T has O reference fields
4. The base classes T have fields referring to O
If the first two conditions are pretty obvious, then with links it’s not so easy, because cyclic links must be taken into account. In real systems, cycles between entities are not uncommon, the most obvious example: Employees - Departments. The Employee belongs to the Department, but the Department also has a Head, who is also an Employee.
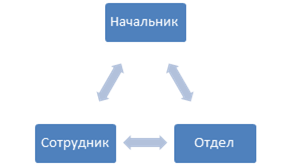
Such connections have to be forced to break, so that the sorting can work. In this example, an attribute is placed in the "Department" field of the Employee, which indicates that this field is not taken into account when constructing entity relationships. After such a gap, however, you have to write some code in order to correctly fill in the fields that cannot be filled in during automatic loading.
Thus, I managed to store data in a convenient format, it is easy to see and control changes, and also correctly and quickly load data into the database, if necessary. What you want.
What is it for:
- For testing purposes
- For collaborative development
- For some software algorithms that operate on this data
Also, the problem of reliable data update on a working project, along with updating the model , is no less acute.
In our system, we used an approach that allows you to monitor data integrity, download and update, stores data in the repository and at the same time works quickly and reliably.
What requirements should such a storage system meet?
First , the data should be stored with versioned.
Secondly , the stored data must be human-readable, for example, to compare versions.
Third , the saved data should be easily loaded into a working system.
So, consider a typical ERP system with hundreds of interrelated entities, inheritance, hierarchical directories, and so on.
What solution does an inexperienced developer apply? Correctly, makes a database dump and stores it. I did it myself :)
')
What are the disadvantages of such a decision:
1. Binary backups are difficult / inefficiently stored in VCS
2. If the backup is large and textual - it's hard to figure out what's changed.
3. It is difficult for a person to read and search for something.
In general, it is inconvenient to store dumps / backups / Sql-scripts, it is even more inconvenient to understand them.
It is much more correct and convenient to store data in text structured, for example, in XML. As such, they are easy to read, diff, and stored in the VCS. Data is stored consistently both for creating new records and for updating existing ones.
In addition, MS SQL / Postgresql / Oracle can parse XML in native way, and MS SQL can also load it directly into tables. By and large, this was one of the main advantages of XML when choosing a storage format.
By the way, this is how Araxis Merge diff can show for XML files
The only question that arises is how to load this happiness with regard to dependencies, foreign keys and interconnections?
Well ... you can do the simplest thing: delete all foreign keys, load the data, then return all the keys to the site . Again, this stage in my life has passed too :)
Solution Minuses:
1. Complex logic for deleting / creating keys
2. If the database structure is complex or the data volume is large - the process of creating / deleting keys can be long
3. And most importantly: when restoring keys, an error will appear only after ALL data is loaded , so there is no way to accurately determine the location of the error.
How can you get rid of the deletion / creation of keys, as well as possibly get an error at the very early stage of loading?
Reflecting on this topic, I came to the conclusion that it is not necessary to delete foreign keys and restrictions on loading. You just need to load the entity data in the correct order .
Thus it is necessary to consider:
1. Foreign keys (they are entity references)
2. Inheritance of entities
3. Hierarchical entities
4. Possible cycles
To solve these problems, I presented a set of entities in the form of a graph and applied Topological sorting . With its help, I sorted all loaded entities so that all the necessary data is already present at the time of loading any item.
There are many implementations of this algorithm in the network, but I took the one that came with the ORM used. At the input it accepts an enumeration of objects and a method that connects them, at the output it receives a sorted list + out parameter with cycles, if any.
It looks like this:
public static List<TNodeItem> Sort<TNodeItem>(IEnumerable<TNodeItem> items, Predicate<TNodeItem, TNodeItem> connector, out List<NodeConnection<TNodeItem, object>> removedEdges) {} For this algorithm to work, the main thing is to correctly represent the entity graph and its relationships.
In my case, the link connector looks like this:
What is translated from ancient Moldavian means that type T depends on (has a directional relationship) type O if:
1. T heir O
2. T is a heir or closed generic type of open generic type O
3. T has O reference fields
4. The base classes T have fields referring to O
If the first two conditions are pretty obvious, then with links it’s not so easy, because cyclic links must be taken into account. In real systems, cycles between entities are not uncommon, the most obvious example: Employees - Departments. The Employee belongs to the Department, but the Department also has a Head, who is also an Employee.
Such connections have to be forced to break, so that the sorting can work. In this example, an attribute is placed in the "Department" field of the Employee, which indicates that this field is not taken into account when constructing entity relationships. After such a gap, however, you have to write some code in order to correctly fill in the fields that cannot be filled in during automatic loading.
Thus, I managed to store data in a convenient format, it is easy to see and control changes, and also correctly and quickly load data into the database, if necessary. What you want.
Source: https://habr.com/ru/post/144301/
All Articles