CAT - Processor Cache Size Management
Architectures of x86 architecture have historically been against allowing programmers to directly manage the cache. One once told me in 2009 - “we will never do this, the cache should always be transparent to the programmer”. Some RISC processors provide architectural data / code management capability that will be cached. And finally, something similar appeared in the x86 architecture (starting with Broadwell *).
Two years ago I wrote a post stating that the first and second level caches do not entirely belong to each core, and that the policy of replacing cache lines in the L3 cache about the principle of the most long-standing use (pseudo-LRU) is a direct way to priority inversion (priority inversion). Readers asked if there is any hardware feature that would allow to overcome priority inversion, not allowing low-priority processes to displace data from foreign caches of the first and second levels, and not letting most of the third-level cache get lost.
This feature is now there, and is called CAT - Cache Allocation Technology. Then I had no right to describe this feature on Habré, since officially it has not yet been released. Its description appeared in the Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 3, Chapter 17 Part 15, it was shown at IDF'15 in San Francisco, and discussions have been going on for a long time in lkml about which interface to CAT will fit into the Linux kernel. Most likely the interface will be implemented through cgroups. Thus, the task scheduler will ensure that user tasks with a certain priority receive a certain part of the cache.
While CAT support is not yet included in the kernel, you can use it directly. Everything is simple in Linux - you need to install msr-tools or an equivalent, and then read and write to the MSR (Model Specific Register), using # rdmsr, # wrmsr - yes, you need to be root. There is a more convenient interface . In Windows it is somewhat more difficult, you can use windbg, or find / write a driver for rdmsr / wrmsr.
')
Next, I will explain using the example of a Xeon server of sixteen cores, a 20-way L3 cache, 2.5 megabytes per core. The interface is very simple. There are 2 types of MSR:
IA32_L3_MASKn: Class of Service. This is a bitmask, where each bit corresponds to a way (not set!) Cache in the third level. These MSRs are numbered 0xc90, 0xc91, etc. They can be written and read from any core, they are common to all cores of each processor.
And IA32_PQR_ASSOC (0xc8f): defines the current active class for each core. This MSR is different for each kernel.
By default, all bit masks are set to 1 (that is, 0xfffff in my example) on each processor, and IA32_PQR_ASSOC is 0 for each yard, so the feature is inactive.
As you can see, if you use a CAT without operating system support, you will also have to manually monitor the correspondence between IA32_PQR_ASSOC for each kernel, and which processes / threads it is running on.
An interesting “hack” is also possible: it is possible to “lock” the data (and / or code) in the cache, if you first turn on several ways, put the data there, and then exclude this part of the cache from all active bit masks. Then this data will remain in the cache (you can, of course, change it), and no one can displace it.
There is an interesting LLC side channel attack class. Since these attacks use the measurement in which way the data is located, by dividing the cache between virtuals without intersections using CAT, we are fully protected from these classes of attacks.
The cache is known to be made associative for a reason. Using CAT, we reduce associativity. If you give a 1/10 cache to some kernel, it turns out that it has “its own” L3 cache in 4 megabytes, 2-way. 4 megabytes is not bad, but 2-way is very small. Obviously, there will be a lot of cache miss due to lack of associativity. This effect can be measured. A few years ago I wrote a post in which I described in detail how to divide the non-intersecting parts of the L3 cache using cache coloring. This technique has a number of flaws, so for this purpose it is not used in common OS and hypervisors (there are several specialized hypervisors where it is used, but I cannot name them in the article.)
So, a small microbenchmark. One core chases STREAM , the second one measures the access time to the cache lines. With CAT and Cache Coloring, we divide the cache between them into different sizes of non-intersecting areas, and in the second test, the size of the data area is changed proportionally.
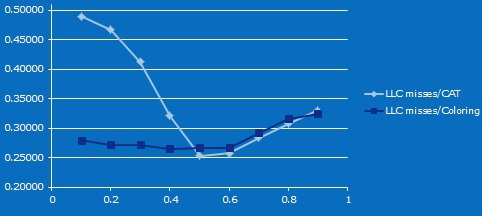
Here is the result. (For X - the share of L3 of the second core, for Y - the percentage of misses on the cache on the second core). I admit that I don’t know exactly why when decreasing the cache, the number of misses drops first (I can assume that this is the effect described in this article ). But starting from 20 megabytes of cache 10-way, and up to 4 megabytes 2-way, it is obvious that the difference in the proportion of cache misses results from a decrease in associativity in the case of using CAT.
To check if CAT is available on a specific processor model, there is a separate cpuid flag. In some models, it is turned off, even if CAT is supported in this family. But I guess there may be a hacker who finds out how to turn it on on any processor, starting with Haswell.
That's it, in short, you need to know to use CAT. In addition, CAT is part of the new technology platform quality of service family, which can be described in a separate post if interested. In addition to CAT, these include CMT (Cache Monitoring Technology), which allows you to measure the efficiency of shared cache separation, MBM (Memory Bandwidth Monitoring), which does the same with memory, and CDP (Code and Data Prioritization).
Two years ago I wrote a post stating that the first and second level caches do not entirely belong to each core, and that the policy of replacing cache lines in the L3 cache about the principle of the most long-standing use (pseudo-LRU) is a direct way to priority inversion (priority inversion). Readers asked if there is any hardware feature that would allow to overcome priority inversion, not allowing low-priority processes to displace data from foreign caches of the first and second levels, and not letting most of the third-level cache get lost.
This feature is now there, and is called CAT - Cache Allocation Technology. Then I had no right to describe this feature on Habré, since officially it has not yet been released. Its description appeared in the Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 3, Chapter 17 Part 15, it was shown at IDF'15 in San Francisco, and discussions have been going on for a long time in lkml about which interface to CAT will fit into the Linux kernel. Most likely the interface will be implemented through cgroups. Thus, the task scheduler will ensure that user tasks with a certain priority receive a certain part of the cache.
While CAT support is not yet included in the kernel, you can use it directly. Everything is simple in Linux - you need to install msr-tools or an equivalent, and then read and write to the MSR (Model Specific Register), using # rdmsr, # wrmsr - yes, you need to be root. There is a more convenient interface . In Windows it is somewhat more difficult, you can use windbg, or find / write a driver for rdmsr / wrmsr.
')
Next, I will explain using the example of a Xeon server of sixteen cores, a 20-way L3 cache, 2.5 megabytes per core. The interface is very simple. There are 2 types of MSR:
IA32_L3_MASKn: Class of Service. This is a bitmask, where each bit corresponds to a way (not set!) Cache in the third level. These MSRs are numbered 0xc90, 0xc91, etc. They can be written and read from any core, they are common to all cores of each processor.
And IA32_PQR_ASSOC (0xc8f): defines the current active class for each core. This MSR is different for each kernel.
By default, all bit masks are set to 1 (that is, 0xfffff in my example) on each processor, and IA32_PQR_ASSOC is 0 for each yard, so the feature is inactive.
As you can see, if you use a CAT without operating system support, you will also have to manually monitor the correspondence between IA32_PQR_ASSOC for each kernel, and which processes / threads it is running on.
An interesting “hack” is also possible: it is possible to “lock” the data (and / or code) in the cache, if you first turn on several ways, put the data there, and then exclude this part of the cache from all active bit masks. Then this data will remain in the cache (you can, of course, change it), and no one can displace it.
There is an interesting LLC side channel attack class. Since these attacks use the measurement in which way the data is located, by dividing the cache between virtuals without intersections using CAT, we are fully protected from these classes of attacks.
The cache is known to be made associative for a reason. Using CAT, we reduce associativity. If you give a 1/10 cache to some kernel, it turns out that it has “its own” L3 cache in 4 megabytes, 2-way. 4 megabytes is not bad, but 2-way is very small. Obviously, there will be a lot of cache miss due to lack of associativity. This effect can be measured. A few years ago I wrote a post in which I described in detail how to divide the non-intersecting parts of the L3 cache using cache coloring. This technique has a number of flaws, so for this purpose it is not used in common OS and hypervisors (there are several specialized hypervisors where it is used, but I cannot name them in the article.)
So, a small microbenchmark. One core chases STREAM , the second one measures the access time to the cache lines. With CAT and Cache Coloring, we divide the cache between them into different sizes of non-intersecting areas, and in the second test, the size of the data area is changed proportionally.
Here is the result. (For X - the share of L3 of the second core, for Y - the percentage of misses on the cache on the second core). I admit that I don’t know exactly why when decreasing the cache, the number of misses drops first (I can assume that this is the effect described in this article ). But starting from 20 megabytes of cache 10-way, and up to 4 megabytes 2-way, it is obvious that the difference in the proportion of cache misses results from a decrease in associativity in the case of using CAT.
To check if CAT is available on a specific processor model, there is a separate cpuid flag. In some models, it is turned off, even if CAT is supported in this family. But I guess there may be a hacker who finds out how to turn it on on any processor, starting with Haswell.
That's it, in short, you need to know to use CAT. In addition, CAT is part of the new technology platform quality of service family, which can be described in a separate post if interested. In addition to CAT, these include CMT (Cache Monitoring Technology), which allows you to measure the efficiency of shared cache separation, MBM (Memory Bandwidth Monitoring), which does the same with memory, and CDP (Code and Data Prioritization).
Source: https://habr.com/ru/post/144196/
All Articles