Disaster-resistant IT-systems: how to implement in your company
Imagine that your data center (or combat server) fell today . Just took and fell. As practice shows, not everyone is ready for this:
In previous posts ( once and twice ) I wrote about organizational measures that will speed up and facilitate the restoration of IT systems and related company processes in an emergency.
')
Now let's talk about technical solutions that will help in this. Their cost varies from a few thousand to hundreds of thousands of dollars.
Very often, solutions for high availability (HA - High Availability) and disaster recovery (DR - Disaster Recovery) are confused. First of all, when we talk about business continuity, we mean a backup site. For IT, a backup data center. Business continuity is not about backing up to the library in the next rack (which is also very important). This is about the fact that the main building of the company will burn down, and in a few hours or days we will be able to resume work, turning around at a new place:
So you need a backup data center. What are the options? Usually there are three: hot, warm and cold reserves.
Cold reserve means that there is some kind of server room in which you can bring equipment and deploy it there. When restoring, it may be planned to purchase “iron” or to store it in a warehouse. It should be borne in mind that most systems are supplied on request, and quickly find dozens of server units, storage systems, switches, and so on. will be a non-trivial task. As an alternative to storing equipment in your own home, you can consider storing the most important or most rare equipment in your suppliers' warehouse. At the same time, telecommunications channels in the room should be present, but the conclusion of a contract with the provider usually occurs after the decision to launch a "cold" data center. Restoration of work in such a data center with a catastrophic failure of the main site may well take several weeks. Make sure that your company can survive these few weeks without IT and not lose business (due to license revocation, or irreplaceable cash gap, for example) - I wrote about this earlier. Honestly, I would not recommend this reservation option to anyone. Perhaps I exaggerate the role of IT in the business of some companies.
This means that we have an alternative platform in which there is an active Internet and WAN channels, basic telecommunications and computing infrastructure. It is always “weaker” than the main computational power, some equipment may be missing there. The most important thing is that the site always has an up-to-date data backup. Acting "in the old fashioned way" you can organize regular transfer backups there on tapes. Modern method - replication of backups on the network from the main data center. Using backup with deduplication will allow you to quickly transfer backups, even on a “thin” channel between data centers.
Here it is, the choice of tough guys who support IT systems, which, idle time, even brings the company huge losses for a few hours. It has all the necessary equipment for the full operation of IT systems. Typically, the foundation of such a platform is a data storage system to which data from the main data center is synchronized synchronously or asynchronously. In order for the hot reserve per hour X to work out the money invested in it, regular test translations of the systems must be conducted, the settings and the OS version of the servers on the main and backup sites must be constantly synchronized - manually or automatically.
Minus hot and warm reserve - expensive equipment idle in anticipation of a disaster. The way out of this situation is the distributed data center strategy . With this option, two (or more) platforms are equal - most applications can work on one or the other. This allows you to use the power of all equipment and to provide load balancing. On the other hand, the requirements for automating the transfer of IT services between data centers are seriously increasing. If both data centers are “combat”, the business has the right to expect that with the expected peak load on one of the applications, it can be quickly transferred to a freer data center. Most often, in such data centers there is synchronous replication between the storage systems, but small asynchrony is possible (within a few minutes).
Before going directly to the IT services disaster resilience technologies, let me recall three “magic” words that determine the cost of any DR solution: RTO, RPO, RCO.
The first division we can make between the whole variety of IT solutions to ensure disaster resilience is whether they provide zero RPO or not. No data loss in case of failure is provided by synchronous replication. Most often, this is done at the storage level, but it is possible to implement it at the DBMS or server level (using advanced LVM). In the first case, the server does not receive confirmation from the storage system with which it is working that the record was successful until the data storage system transferred this transaction to the second system and received confirmation from it that the record was successful.
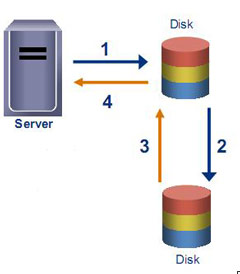
Synchronous replication can make 100% storage systems belonging to the average price segment and some entry-level systems from well-known vendors. The cost of licenses for synchronous replication on “simple” storage systems starts from a few thousand dollars. Approximately the same is the software for replication at the server level for 2-3 servers. If you do not have a valid backup data center, do not forget to add the cost of purchasing backup equipment.
RPO in a few minutes can provide asynron replication at the storage level, server volume management software (LVM - Logical volume manager), or DBMS. Until now, a standby copy of the database remains one of the most popular solutions for DR. Most often, the “log shipping” functionality, as the DBMS administrators call it, is not separately licensed by the manufacturer. If you have a database licensed - replicate to health. The cost of asynchronous replication for servers and storage is not different from synchronous, see the previous paragraph.
If we talk about RPO in a few hours, more often it is the replication of backups from one site to another. Most disk libraries can do this, some backup software too. As I said, with this option deduplication helps a lot. You will not only download the channel less by transferring backups, but also make it much faster - each transferred backup will take tens or hundreds of times less time than in reality. On the other hand, it must be remembered that the first backup during deduplication should still transfer a lot of unique data to the system. You will see "real" deduplication after the weekly backup cycle. When synchronizing disk libraries - the same thing. If the estimated transfer time for your channel width between data centers is several days or even weeks (which may cost a lot), it makes sense to first put the second library side by side, synchronize and take it to the backup data center.
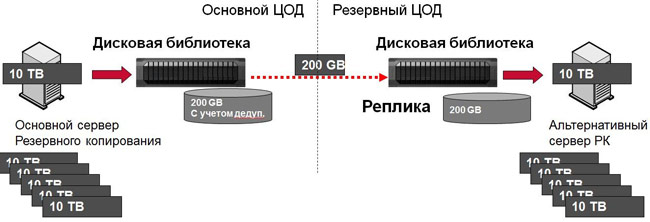
Synchronize backups between data centers
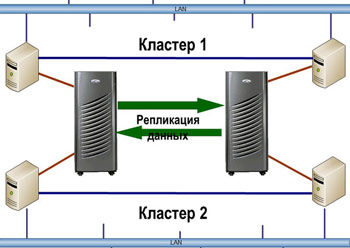
When faced with the task of minimizing recovery time ( RTO ), the process should be as documented and automated as possible. One of the best and most universal solutions is HA-clusters with geographically dispersed nodes. Most often, such solutions are built on the basis of storage replication, but other options are possible. Leading products in this area, for example, Symantec Veritas Cluster, have modules for working with storage systems that switch the direction of replication when you need to restart the service on the backup node. For less advanced clusters (for example, Microsoft Cluster Services built into Windows), the main storage vendors (IBM, EMC, HP) offer add-ons, making disaster-resistant from a regular HA-cluster.
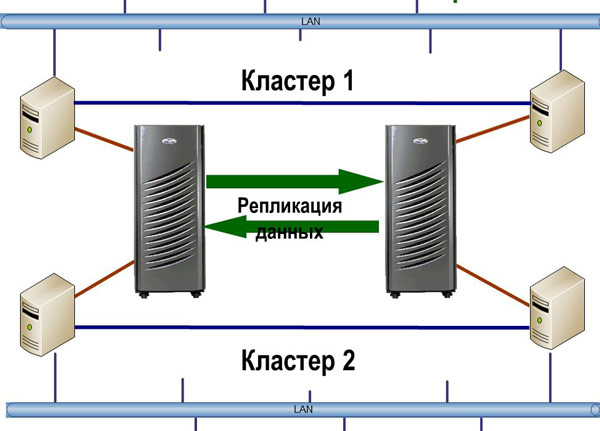
Geographically Distributed Cluster
Few people think about the interesting feature of the overwhelming majority of data replication solutions - their “singly charged”. You can get only one data state at a backup site. If the system with these data for some reason did not start - go to plan "B". Most often this is a restore from a backup with a large loss of data. Of the technologies I listed, the only exception will be replication of the same backups. The answer here is to use the Continuous Data Protection solution class. Their essence is that all entries coming from the server are marked and stored in a specific journal volume on the backup site. When restoring the system, you can select any point from this log and get the status not only at the time of the accident in which the data was corrupted, but also in a few seconds. Such solutions protect against internal threats - deletion of data by users. In the case of storage replication - it doesn’t care what to transfer - an empty volume or your most critical database. When using CDP, you can select a moment right before deleting information and recover from it. The cost of CDP systems is usually tens of thousands of dollars. One of the most successful examples, in my opinion, is EMC RecoverPoint.
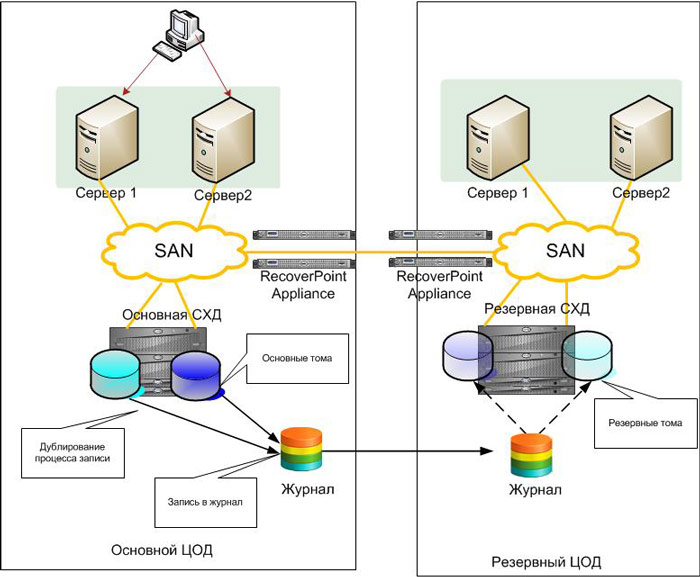
RecoverPoint Based Solution Chart
Recently, virtualization storage systems are gaining popularity. In addition to its main function - combining arrays of different vendors into a single pool of resources - they can greatly help in organizing a distributed data center. The essence of storage virtualization is that between servers and storage systems there appears an intermediate layer of controllers that allow all traffic through. Storage volumes are not presented directly to servers, but to these virtualizers. They, in turn, distribute them to their hosts. In the virtualization layer, data can be replicated between different storage systems, and often there are more advanced features — snapshots, multi-level storage, etc. The most basic function of virtualizers is the most necessary for DR purposes. If we have two storage systems in different data centers connected by an optical backbone, we take volumes from each of them and collect a “mirror” at the virtualizer level. As a result, we get one virtual volume for two data centers, which servers see. If these servers are virtual, Live Migration of virtual machines starts working and you can transfer tasks between data centers “on the go” - users will not notice anything.
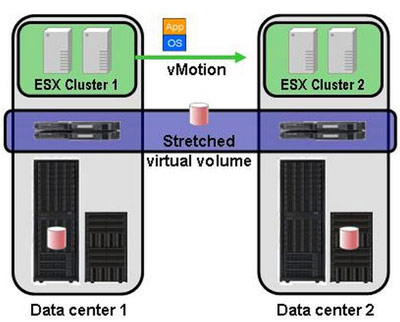
The complete loss of the data center will be handled by a regular HA cluster in automatic mode in a few minutes. Perhaps, virtualization of separated storage systems allows to provide the minimum recovery time for most applications. For the DBMS there is an unsurpassed Oracle RAC and its analogs, but the cost makes you wonder. SAN virtualization is also not cheap yet, for small storage volumes the cost of the solution may be less than $ 100K, but in most cases the price is higher. In my opinion, the most proven solution is IBM SAN Volume Controller (SVC), the most technically advanced is EMC VPLEX.
By the way, if not all of your applications still live in a virtual environment, you should design a backup data center for them in virtual machines. Firstly, it will be much cheaper, and secondly, by doing this for a reserve, close to the migration of the main systems under the control of some hypervisor ...
Competition in the data center outsourcing market makes it more profitable to rent a stand in the provider’s data center, compared to the construction and operation of its backup center. If you place a virtual infrastructure with him, there will be a significant savings on rental payments. But outsourced data centers are no longer at the top of progress. It is better to build a backup infrastructure immediately in the "cloud". Data synchronization with the main systems can be provided with server-level replication (there is an excellent DoubleTake family of solutions from Vision Solutions).
The last but very important point that should not be forgotten when designing a disaster-resistant IT infrastructure is the workplaces of users. The fact that the database has risen does not mean the resumption of the business process. The user should be able to do his job. Even a full-fledged backup office with computers turned off for key employees is not an ideal solution. A person in a lost workplace may have reference materials, macros, and so on, full-fledged work without which is impossible. For the most important users of the company, it seems reasonable to switch to virtual workplaces (VDI). Then, no data is stored in the workplace (whether it is a regular PC or a fashionable “thin” client), it is used only as a terminal to reach Windows XP or Windows 7 running on a virtual machine in the data center. Access to such a workplace is easy to organize from home or from any computer in the branch network. For example, if you have several buildings and one of them is unavailable, key users can come to the next office and sit at “less key” jobs. Then they calmly log in to the system, get into their virtual machine and the company comes to life!
In conclusion, these are the main questions to ask when evaluating a DR solution:
Disaster-resistant solutions are countless - both boxed and those that can be made with your own hands. Please share in the comments what you have and the stories about how these decisions helped you out. If something of the systems described above or their equivalents work for you, leave feedback on how calmly you sleep when IT systems are under their protection.
- 93% of companies that lost their data center for 10 or more days due to a disaster became bankrupt during the year (National Archives & Records Administration in Washington)
- 140,000 hard drives fail in the US every week (Mozy Online Backup)
- 75% of companies do not have disaster recovery solutions (Forrester Research, Inc.)
- 34% of companies do not test backups.
- 77% of those who tested found unreadable drives in their libraries.
In previous posts ( once and twice ) I wrote about organizational measures that will speed up and facilitate the restoration of IT systems and related company processes in an emergency.
')
Now let's talk about technical solutions that will help in this. Their cost varies from a few thousand to hundreds of thousands of dollars.
High availability and disaster recovery
Very often, solutions for high availability (HA - High Availability) and disaster recovery (DR - Disaster Recovery) are confused. First of all, when we talk about business continuity, we mean a backup site. For IT, a backup data center. Business continuity is not about backing up to the library in the next rack (which is also very important). This is about the fact that the main building of the company will burn down, and in a few hours or days we will be able to resume work, turning around at a new place:
| High availability | Disaster recovery |
| Solution within a single data center | Includes multiple remote data centers |
| Recovery time <30 minutes | Recovery can take hours and even days. |
| Zero or close to zero data loss | Data loss can reach many hours. |
| Requires quarterly testing | Requires annual testing |
Cold reserve
Cold reserve means that there is some kind of server room in which you can bring equipment and deploy it there. When restoring, it may be planned to purchase “iron” or to store it in a warehouse. It should be borne in mind that most systems are supplied on request, and quickly find dozens of server units, storage systems, switches, and so on. will be a non-trivial task. As an alternative to storing equipment in your own home, you can consider storing the most important or most rare equipment in your suppliers' warehouse. At the same time, telecommunications channels in the room should be present, but the conclusion of a contract with the provider usually occurs after the decision to launch a "cold" data center. Restoration of work in such a data center with a catastrophic failure of the main site may well take several weeks. Make sure that your company can survive these few weeks without IT and not lose business (due to license revocation, or irreplaceable cash gap, for example) - I wrote about this earlier. Honestly, I would not recommend this reservation option to anyone. Perhaps I exaggerate the role of IT in the business of some companies.
Warm reserve
This means that we have an alternative platform in which there is an active Internet and WAN channels, basic telecommunications and computing infrastructure. It is always “weaker” than the main computational power, some equipment may be missing there. The most important thing is that the site always has an up-to-date data backup. Acting "in the old fashioned way" you can organize regular transfer backups there on tapes. Modern method - replication of backups on the network from the main data center. Using backup with deduplication will allow you to quickly transfer backups, even on a “thin” channel between data centers.
Hot standby
Here it is, the choice of tough guys who support IT systems, which, idle time, even brings the company huge losses for a few hours. It has all the necessary equipment for the full operation of IT systems. Typically, the foundation of such a platform is a data storage system to which data from the main data center is synchronized synchronously or asynchronously. In order for the hot reserve per hour X to work out the money invested in it, regular test translations of the systems must be conducted, the settings and the OS version of the servers on the main and backup sites must be constantly synchronized - manually or automatically.
Minus hot and warm reserve - expensive equipment idle in anticipation of a disaster. The way out of this situation is the distributed data center strategy . With this option, two (or more) platforms are equal - most applications can work on one or the other. This allows you to use the power of all equipment and to provide load balancing. On the other hand, the requirements for automating the transfer of IT services between data centers are seriously increasing. If both data centers are “combat”, the business has the right to expect that with the expected peak load on one of the applications, it can be quickly transferred to a freer data center. Most often, in such data centers there is synchronous replication between the storage systems, but small asynchrony is possible (within a few minutes).
Three magic words
Before going directly to the IT services disaster resilience technologies, let me recall three “magic” words that determine the cost of any DR solution: RTO, RPO, RCO.
- RTO (Recovery time objective) - time for which it is possible to restore the IT system
- RPO (Recovery point objective) - how much data will be lost during disaster recovery
- RCO (Recovery capacity objective) - how much of the load the backup system should provide. This indicator can be measured as a percentage, transactions of IT systems and other values.
RPO
The first division we can make between the whole variety of IT solutions to ensure disaster resilience is whether they provide zero RPO or not. No data loss in case of failure is provided by synchronous replication. Most often, this is done at the storage level, but it is possible to implement it at the DBMS or server level (using advanced LVM). In the first case, the server does not receive confirmation from the storage system with which it is working that the record was successful until the data storage system transferred this transaction to the second system and received confirmation from it that the record was successful.
Synchronous replication can make 100% storage systems belonging to the average price segment and some entry-level systems from well-known vendors. The cost of licenses for synchronous replication on “simple” storage systems starts from a few thousand dollars. Approximately the same is the software for replication at the server level for 2-3 servers. If you do not have a valid backup data center, do not forget to add the cost of purchasing backup equipment.
RPO in a few minutes can provide asynron replication at the storage level, server volume management software (LVM - Logical volume manager), or DBMS. Until now, a standby copy of the database remains one of the most popular solutions for DR. Most often, the “log shipping” functionality, as the DBMS administrators call it, is not separately licensed by the manufacturer. If you have a database licensed - replicate to health. The cost of asynchronous replication for servers and storage is not different from synchronous, see the previous paragraph.
If we talk about RPO in a few hours, more often it is the replication of backups from one site to another. Most disk libraries can do this, some backup software too. As I said, with this option deduplication helps a lot. You will not only download the channel less by transferring backups, but also make it much faster - each transferred backup will take tens or hundreds of times less time than in reality. On the other hand, it must be remembered that the first backup during deduplication should still transfer a lot of unique data to the system. You will see "real" deduplication after the weekly backup cycle. When synchronizing disk libraries - the same thing. If the estimated transfer time for your channel width between data centers is several days or even weeks (which may cost a lot), it makes sense to first put the second library side by side, synchronize and take it to the backup data center.
Synchronize backups between data centers
Rto
When faced with the task of minimizing recovery time ( RTO ), the process should be as documented and automated as possible. One of the best and most universal solutions is HA-clusters with geographically dispersed nodes. Most often, such solutions are built on the basis of storage replication, but other options are possible. Leading products in this area, for example, Symantec Veritas Cluster, have modules for working with storage systems that switch the direction of replication when you need to restart the service on the backup node. For less advanced clusters (for example, Microsoft Cluster Services built into Windows), the main storage vendors (IBM, EMC, HP) offer add-ons, making disaster-resistant from a regular HA-cluster.
Geographically Distributed Cluster
Few people think about the interesting feature of the overwhelming majority of data replication solutions - their “singly charged”. You can get only one data state at a backup site. If the system with these data for some reason did not start - go to plan "B". Most often this is a restore from a backup with a large loss of data. Of the technologies I listed, the only exception will be replication of the same backups. The answer here is to use the Continuous Data Protection solution class. Their essence is that all entries coming from the server are marked and stored in a specific journal volume on the backup site. When restoring the system, you can select any point from this log and get the status not only at the time of the accident in which the data was corrupted, but also in a few seconds. Such solutions protect against internal threats - deletion of data by users. In the case of storage replication - it doesn’t care what to transfer - an empty volume or your most critical database. When using CDP, you can select a moment right before deleting information and recover from it. The cost of CDP systems is usually tens of thousands of dollars. One of the most successful examples, in my opinion, is EMC RecoverPoint.
RecoverPoint Based Solution Chart
Recently, virtualization storage systems are gaining popularity. In addition to its main function - combining arrays of different vendors into a single pool of resources - they can greatly help in organizing a distributed data center. The essence of storage virtualization is that between servers and storage systems there appears an intermediate layer of controllers that allow all traffic through. Storage volumes are not presented directly to servers, but to these virtualizers. They, in turn, distribute them to their hosts. In the virtualization layer, data can be replicated between different storage systems, and often there are more advanced features — snapshots, multi-level storage, etc. The most basic function of virtualizers is the most necessary for DR purposes. If we have two storage systems in different data centers connected by an optical backbone, we take volumes from each of them and collect a “mirror” at the virtualizer level. As a result, we get one virtual volume for two data centers, which servers see. If these servers are virtual, Live Migration of virtual machines starts working and you can transfer tasks between data centers “on the go” - users will not notice anything.
The complete loss of the data center will be handled by a regular HA cluster in automatic mode in a few minutes. Perhaps, virtualization of separated storage systems allows to provide the minimum recovery time for most applications. For the DBMS there is an unsurpassed Oracle RAC and its analogs, but the cost makes you wonder. SAN virtualization is also not cheap yet, for small storage volumes the cost of the solution may be less than $ 100K, but in most cases the price is higher. In my opinion, the most proven solution is IBM SAN Volume Controller (SVC), the most technically advanced is EMC VPLEX.
By the way, if not all of your applications still live in a virtual environment, you should design a backup data center for them in virtual machines. Firstly, it will be much cheaper, and secondly, by doing this for a reserve, close to the migration of the main systems under the control of some hypervisor ...
Competition in the data center outsourcing market makes it more profitable to rent a stand in the provider’s data center, compared to the construction and operation of its backup center. If you place a virtual infrastructure with him, there will be a significant savings on rental payments. But outsourced data centers are no longer at the top of progress. It is better to build a backup infrastructure immediately in the "cloud". Data synchronization with the main systems can be provided with server-level replication (there is an excellent DoubleTake family of solutions from Vision Solutions).
The last but very important point that should not be forgotten when designing a disaster-resistant IT infrastructure is the workplaces of users. The fact that the database has risen does not mean the resumption of the business process. The user should be able to do his job. Even a full-fledged backup office with computers turned off for key employees is not an ideal solution. A person in a lost workplace may have reference materials, macros, and so on, full-fledged work without which is impossible. For the most important users of the company, it seems reasonable to switch to virtual workplaces (VDI). Then, no data is stored in the workplace (whether it is a regular PC or a fashionable “thin” client), it is used only as a terminal to reach Windows XP or Windows 7 running on a virtual machine in the data center. Access to such a workplace is easy to organize from home or from any computer in the branch network. For example, if you have several buildings and one of them is unavailable, key users can come to the next office and sit at “less key” jobs. Then they calmly log in to the system, get into their virtual machine and the company comes to life!
In conclusion, these are the main questions to ask when evaluating a DR solution:
- From what failures protects?
- What RPO / RTO / RCO provides?
- How much is?
- How difficult is the operation?
Disaster-resistant solutions are countless - both boxed and those that can be made with your own hands. Please share in the comments what you have and the stories about how these decisions helped you out. If something of the systems described above or their equivalents work for you, leave feedback on how calmly you sleep when IT systems are under their protection.
Source: https://habr.com/ru/post/143877/
All Articles