Sharing is not always useful: we optimize work with cache memory.
 To share with our neighbors for us, the beasts of God, this is very characteristic, considered a virtue, and in general, as the original source asserts, has a positive effect on karma. However, in the world created by microprocessor architects, this behavior does not always lead to good results, especially when it comes to sharing memory between threads.
To share with our neighbors for us, the beasts of God, this is very characteristic, considered a virtue, and in general, as the original source asserts, has a positive effect on karma. However, in the world created by microprocessor architects, this behavior does not always lead to good results, especially when it comes to sharing memory between threads.We all read a little about memory optimization, and it was postponed for us, which is useful when the cache remains hot, that is, the data that the threads often access should be compact and located in the cache closest to the processor core. That's right, but when it comes to sharing access, streams become the worst enemies [of performance], and the cache is not just hot, it already “ burns with hellfire ” - this is how the struggle unfolds around it.
Below we will consider a simple but illustrative case of multi-threaded program performance problems, and then I will give some general recommendations on how to avoid the problem of loss of computational efficiency due to the separation of the cache between threads.
')
Consider a case that is well described in the Intel64 and IA-32 Architectures Optimization Manual ; however, programmers often forget about it when working with arrays of structures in a continuous flow mode. They allow accessing (with modification) of streams to data of structures located very close to each other, namely, in a block equal to the length of one cache line (64 bytes). We call this Cache line sharing . There are two types of split lines: true sharing and false sharing .
True sharing is when threads have access to the same memory object, for example, a common variable or a synchronization primitive. False sharing (
Why performance suffers, we will explain with an example. Suppose we process a sequence of queued data structures in multi-threaded mode. Active threads one by one take out the following structure from the queue and in some way process it, modifying the data. What can happen at the hardware level, if, for example, the size of this structure is small and does not exceed several tens of bytes?
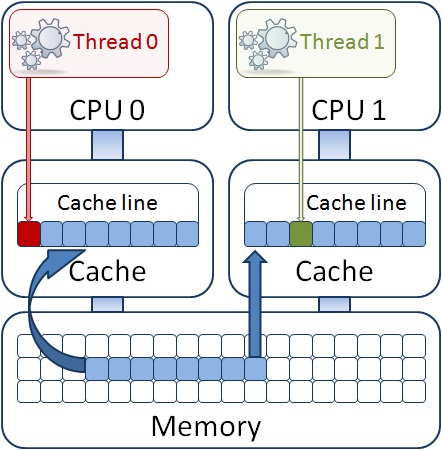
Conditions for the problem:
Two or more streams write to the same cache line;
One thread writes, the rest read from the cache line;
One thread writes, in the rest of the kernels HW prefetcher has been working.
It may turn out that the variables in the fields of different structures are so located in the memory that, being read in the processor's L1 cache, are in the same cache line as in the figure. In this case, if one of the threads modifies the field of its structure, then the entire cache line is declared invalid for the remaining processor cores in accordance with the cache coherency protocol. Another thread can no longer use its structure, despite the fact that it already lies in the L1 cache of its core. In old P4 processors in such a situation, a long synchronization with the main memory would be required, that is, the modified data would be sent to the main memory and then read into the L1 cache of another core. In the current generation of processors (codenamed Sandy Bridge), the synchronization mechanism uses a shared third-level cache (or LLC - Last Level Cache), which is inclusive for the cache memory subsystem and contains all the data in both L2 and L1 all processor cores. Thus, synchronization does not occur with the main memory, but with the LLC, which is part of the implementation of the cache coherence mechanism protocol, which is much faster. But it still happens, and it takes time, although measured in just a few dozen processor cycles. And if the data in the cache lines are divided between threads that run in different physical processors? Then it will be necessary to sync between LLCs of different chips, and this is much longer - already hundreds of cycles. Now imagine that the program is only concerned with the fact that in a cycle it processes the stream of data received from any source. Losing hundreds of cycles on each iteration of the cycle, we run the risk of "dropping" our performance at times.
Let's look at the following example, specially simplified in order to make it easier to understand the causes of the problem. Do not hesitate, in real applications the same cases occur very often, and unlike the refined example, even to detect the existence of a problem is not so simple. Below we show how to quickly find such situations using the performance profiler.
In a loop, the stream function runs through two arrays float a [i] and b [i], multiplies their values by the array index and adds localSum [tid] to the local thread variables. To enhance the effect, this operation is done several times (ITERATIONS).
int work(void *pArg) { int j = 0, i = 0; int tid = (int) pArg; for (j = 0; j < ITERATIONS; j++){ for (i = tid; i < MAXSIZE; i+= NUM_PROCS){ a[i] = i + a[i] * b[i]; localSum[tid] += a[i];}} } The trouble is that the method of interleaving cycle indexes is selected for data sharing between threads. That is, if we have two streams, the first will refer to the elements of the arrays a [0] and b [0], the second to the elements a [1] and b [1], the first to a [2] and b [2 ], the second is a [3] and b [3], and so on. In this case, the elements of the array a [i] are modified by threads. It is not difficult to see that 16 elements of the array will fall into one cache line, and the threads will simultaneously access neighboring elements, “driving the processor caches synchronization mechanism” to mind.

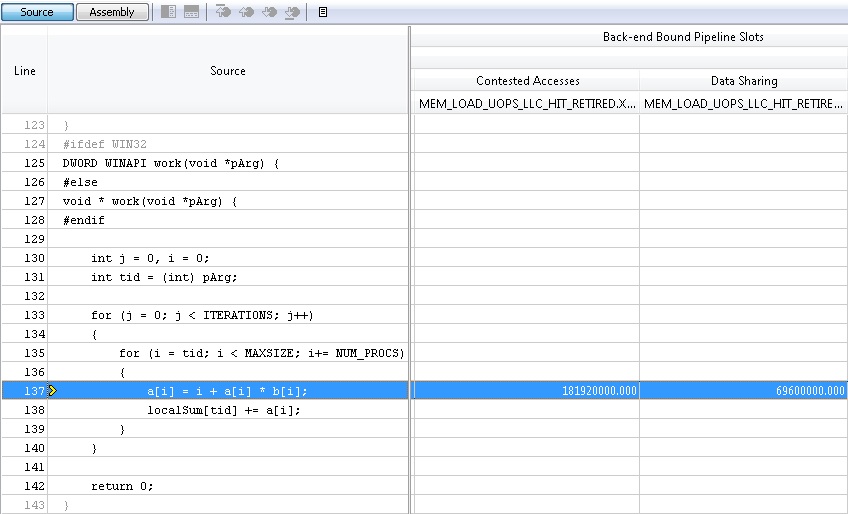
The most annoying thing is that we will not even notice the existence of this problem by the work of the program. It will just work slower than it can, that's all. How to evaluate the effectiveness of the program using the profiler VTune Amplifier XE, I have already described in one of the posts on Habré. Using the General Exploration profile that I mentioned there, you can see the problem being described, which will be highlighted by the tool in the profiling results in the Contested Access column. This metric just measures the ratio of the cycles spent on synchronization of processor caches when they are modified by threads.

If someone is interested in what is behind this metric, then during complex profiling, the tool collects meter data among other hardware counters:
MEM_LOAD_UOPS_LLC_HIT_RETIRED.XSNP_HITM_PS - Exact counter (PS) of the performed (RETIRED) operation (OUPS) load (LOAD) data (MEM), which turned out (HIT) in LLC and modified (M). An “accurate” counter means that the data collected by such a counter in sampling refers to an instruction pointer (IP) following the instruction that was the same load that led to the synchronization of the caches. Having collected statistics on this metric, we can specify with some accuracy the address of the instruction, and, accordingly, the source code line where the reading was performed. VTune Amplifier XE can show which threads read this data, and then we have to find out for ourselves how multithreaded data access is implemented and how to correct the situation.
Regarding our simple example, it's very easy to fix the situation. You just need to divide the data into blocks, while the number of blocks will be equal to the number of threads. Someone may argue: if the arrays are large enough, the blocks may simply not fit into the cache, and the data loaded from memory for each stream will displace each other from the cache. This will be true if all block data is used continuously, and not once. For example, when multiplying matrices, we walk through the elements of a two-dimensional array, first in rows, then in columns. And if both matrices do not fit in the cache (of any level), then they will be pushed out, and repeated access to the elements will require reloading from the next level, which negatively affects performance. In the general case with matrices, modified matrix multiplication is applied block by block, and the matrices are divided into blocks, which are deliberately placed in a given cache memory, which significantly increases the performance of the algorithm.
int work(void *pArg) { int j = 0, i = 0; int tid = (int) pArg; for (j = 0; j < ITERATIONS; j++){ chunks = MAXSIZE / NUM_PROCS; for (i = tid * chunks; i < (tid + 1) * chunks; i++){ a[i] = i + a[i] * b[i]; localSum[tid] += a[i];}} } False sharing

No False sharing
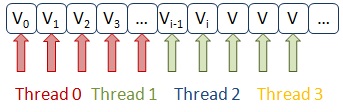
Comparing access of streams to array elements in the case of False sharing and in the corrected code
In our simple case, the data is used only once, and even if they are pushed out of the cache memory, we will no longer need it. And the data of both arrays a [i] and b [i], located far from each other in the address space, are in the cache in time taken care of by the hardware prefetcher - a mechanism for pumping data from the main memory implemented in the processor. It works fine if access to the elements of an array is sequential.
In conclusion, we can give some general recommendations on how to avoid the problem of loss of computational efficiency due to the separation of the cache between threads. From the very name of the problem, it can be understood that coding should be avoided where streams access common data very often. If this is true sharing of a mutex by threads, then there may be a problem of excessive synchronization, and the approach to sharing the resource protected by this mutex should be reconsidered. In general, try to avoid global and static variables that need access from streams. Use local thread variables.
If you work with data structures in multi-threaded mode, pay attention to their size. Use padding to increase the size of the structure to 64 bytes:
struct data_packet { int address[4]; int data[8]; int attribute; int padding[3]; } Allocate memory for structures at the aligned address:
__declspec(align(64)) struct data_packet sendpack Use arrays of structures instead of array structures:
data_packet sendpack[NUM]; instead
struct data_packet { int address[4][NUM]; int data[8][NUM]; int attribute[NUM]; } As you can see, in the latter case, streams modifying one of the fields will trigger the cache synchronization mechanism.
For objects allocated in dynamic memory using malloc or new, create local memory pools for threads, or use parallel libraries that can do this themselves. For example, the TBB library contains scalable and leveling allocators that are useful for scalable multithreaded programs.
Well, the final advice: you should not rush to solve the problem, if it does not greatly affect the overall performance of the application. Always evaluate the potential gain that you receive as a result of the cost of optimizing your code. Use the profiling tools to evaluate this gain.
PS Try my primerchik, and tell me how many percent increased test performance on your platform.
Source: https://habr.com/ru/post/143446/
All Articles