About code reuse
Today there are different opinions about the success of object technology. On the one hand, most modern mainstream programming languages are object-oriented, on the other hand, it is often possible to hear criticism of OOP, object-oriented programming “failed” and did not justify the hopes that were placed on it by the software development industry. Everyone supposedly expected the onset of universal happiness in the form of increased reuse, simplified maintenance, and indeed they promised that they would have to think of someone else, and I would receive money for it.
There are several reasons for such disappointments. First, such an attitude to the PLO may be the result of high expectations, but Fred Brooks wrote twenty years ago that one should not wait for “silver bullets” capable of increasing the productivity of a programmer’s work by an order of magnitude. Secondly, none of the serious supporters of the PLO (such as Grady Butch or Bertrand Meyer) promised that everything would be simple. OOP is not a magic wand that will make a candy out of any HS, even a wrapper that can be reused.
So the question is: how is it possible to achieve that cherished dream when the systems can be built from ready-made components without writing a single line of code? I'm not sure that in this form, this dream is generally feasible because of the inherent complexity of the software, and also because often the decision itself affects the task to be solved. However, if you direct the energy spent on reuse in the right direction, then with a reasonable amount of effort you can raise the "reuse" of the code to a decent level.
')
It seems to me that there are two reasons for such a deplorable state of reuse: (1) developers give too little attention to reuse and (2) developers give too much attention to reuse. Yes, it sounds, at least, stupid, but let me paraphrase a little: the problem with reuse is that efforts are being put at the wrong time and not always where it should be .
To begin with, let's look at the typical life cycle of a single iteration of software development:
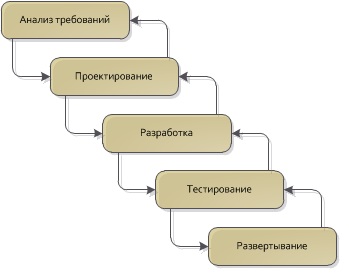
The classic software development life cycle is iterative, with each iteration consisting of (more or less) the same steps. In some cases, the design and implementation stages can be combined into one, and before the analysis phase, there can sometimes be a feasibility analysis, but the essence does not change. Now let's try to answer the question: at which of these stages is it decided that certain classes (or modules entirely) are worthy of reuse? Usually this decision is made on the fly somewhere between analysis and design, sometimes it is made at the design stage, sometimes during implementation.
In general, there is nothing bad about it, until the process of generalization does not begin to influence the design of the system, delay the deadlines and lead to an increase in complexity, instead of struggling with it.
Every self-respecting developer knows Knut 's quote about evil premature optimization, which can lead to incredibly fast code (though not usually in the right places), which the author himself will not be able to read and understand over time. But since now the most costly part of many systems is not productivity, but development efficiency, instead of premature optimization, it is increasingly possible to face the problem of “premature generalization” (premature generalization).
In fact, a premature generalization boils down to creating a more complex solution in the hope of reuse or “flexibility” that will cope with future changes. But, as is usually the case, “flexibility” is not so flexible, the requirements begin to change in the wrong direction, as a result, labor costs are not justified and the team gets a more complex solution, although it could get along with more simple. Sometimes there are more pathological cases: for example, from the very beginning an “architect” can take up the work with the uncompromising desire to build his own “framework” with blackjack and girls when there is still no clear vision of what the team, project and customer need. As a result, each project is cluttered with curved libraries and frameworks, which are inconvenient to use, and expensive to maintain.
The problem is that the costs of design, implementation and maintenance of publicly available code are several orders of magnitude higher than the cost of maintaining a simple custom solution. It all starts with the fact that the reusable code requires more complete and detailed documentation, better quality and test coverage, examples of use and user documentation. Even if the code is intended for reuse within the team, its quality and ease of use should be such that it is economically beneficial for the programmer to sort out your decision and not to fence your own favorite garden. And I'm not talking about the need for a culture of reuse, without which the whole idea of a “reuse” will be covered with a copper basin thanks to the well-loved NIH symptom (Not Invented Here).
When it comes not to libraries, but to the “flexibility” of specific solutions, we are faced with a similar problem. Many believe that a “generic” solution (with a lot of room for expansion) is the best way to handle future changes. Perhaps this is true, but practice shows that it is very easy to slide from this path to a cumbersome code that is difficult to understand (because it can do everything) and accompany. If you think that some aspect of behavior can change, then it is enough to hide it behind an abstract interface and make this aspect a detail of the implementation. As in the case of productivity, programmers (and architects) have little idea what exactly will change in the future and what new needs will arise. And if so, then there is nothing better than a simple solution that can be easily adapted to changing requirements by modifying it.
All these difficulties do not say that reuse is stupid. Not. Just as the performance optimization should be carried out after profiling, so the generalization should be done in Time: not during the development of the feature itself, but at later stages, when the team understands where possible changes will be directed and what needs to be generalized, and what - not.
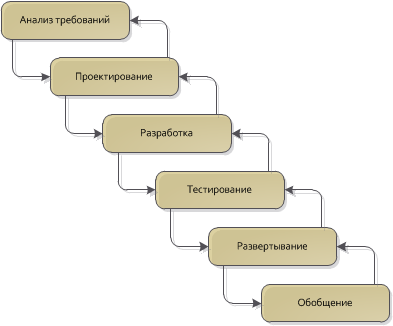
Here you need to understand a very important point: the step of generalization is not in itself a sufficient condition for creating a reusable code, just like the profiling process does not guarantee that you can improve the performance of the found bottle neck. This is only a stage during which a simple and adequate solution obtained at the design and implementation stage is “combed” additionally to bring it to the level of reuse: unnecessary dependencies are removed, documentation is improved, additional unit tests are added. If during the implementation everything is crumpled up and made such a tangle out of the system, that it is impossible to understand without a bottle, then there can be no talk of a future “reuse”. But if you start with a simple and understandable architecture that solves the task well, then combining several solutions of the same type into one will be much easier when it is already precisely clear what they have in common.
NOTE
In this case, I do not consider the development of libraries as a separate product. The library was originally sharpened for reuse and there a lot is being done differently; it is enough to look through the Framework Design Guidelines to understand that when developing a library, its quality, usability, absence of breaking changes, intuitive clarity, “hierarchy”, and much more come to the fore. Here we are not talking about libraries for the general public, but about problems with reuse in typical enterprise applications.
The generalization step does not have to be formal or take place at each iteration of development, but sooner or later the team will need to make additional efforts to bring the code (and design) to mind, which means that the project leaders should be aware of it.
Unfortunately, even the stage of generalization is not a guarantee of increasing the “reuse” of the code. The first problem is connected with knocking out extra time for the management of an incomprehensible generalization, instead of riveting the new functionality of the next iteration. Yes, everyone talks about the importance of reuse, but when it comes to additional costs, the short-sightedness of project managers may play a role and will be denied in the synthesis. There is a grain of truth in this; The second problem is that the availability of high-quality code that is available for reuse does not guarantee its use. For a normal "reyuz", culture is also needed, and the beloved NIH and the thirst for cycling can be so strong that any attempt to reuse will lead to nothing.
But, in any case, my advice is to ensure that when choosing simplicity versus “flexibility” for future changes , you would stop on simplicity. After all, if the solution is simple, then it is easy to modify it for future needs, or summarize it for reuse. Well, if nothing is needed, then you just save time and energy, and you will live with this simple solution for many years.
NOTE
The idea of the generalization stage was suggested by Bertrand Meyer in his book “Object-Oriented Design of Software Systems” , so some details can be found in the section “28.5 Generalization” (by the way, this is really an excellent book in which you can find many interesting ideas about OOP and software development).
There are several reasons for such disappointments. First, such an attitude to the PLO may be the result of high expectations, but Fred Brooks wrote twenty years ago that one should not wait for “silver bullets” capable of increasing the productivity of a programmer’s work by an order of magnitude. Secondly, none of the serious supporters of the PLO (such as Grady Butch or Bertrand Meyer) promised that everything would be simple. OOP is not a magic wand that will make a candy out of any HS, even a wrapper that can be reused.
So the question is: how is it possible to achieve that cherished dream when the systems can be built from ready-made components without writing a single line of code? I'm not sure that in this form, this dream is generally feasible because of the inherent complexity of the software, and also because often the decision itself affects the task to be solved. However, if you direct the energy spent on reuse in the right direction, then with a reasonable amount of effort you can raise the "reuse" of the code to a decent level.
')
It seems to me that there are two reasons for such a deplorable state of reuse: (1) developers give too little attention to reuse and (2) developers give too much attention to reuse. Yes, it sounds, at least, stupid, but let me paraphrase a little: the problem with reuse is that efforts are being put at the wrong time and not always where it should be .
Standard software life cycle
To begin with, let's look at the typical life cycle of a single iteration of software development:
The classic software development life cycle is iterative, with each iteration consisting of (more or less) the same steps. In some cases, the design and implementation stages can be combined into one, and before the analysis phase, there can sometimes be a feasibility analysis, but the essence does not change. Now let's try to answer the question: at which of these stages is it decided that certain classes (or modules entirely) are worthy of reuse? Usually this decision is made on the fly somewhere between analysis and design, sometimes it is made at the design stage, sometimes during implementation.
In general, there is nothing bad about it, until the process of generalization does not begin to influence the design of the system, delay the deadlines and lead to an increase in complexity, instead of struggling with it.
Premature synthesis
Every self-respecting developer knows Knut 's quote about evil premature optimization, which can lead to incredibly fast code (though not usually in the right places), which the author himself will not be able to read and understand over time. But since now the most costly part of many systems is not productivity, but development efficiency, instead of premature optimization, it is increasingly possible to face the problem of “premature generalization” (premature generalization).
In fact, a premature generalization boils down to creating a more complex solution in the hope of reuse or “flexibility” that will cope with future changes. But, as is usually the case, “flexibility” is not so flexible, the requirements begin to change in the wrong direction, as a result, labor costs are not justified and the team gets a more complex solution, although it could get along with more simple. Sometimes there are more pathological cases: for example, from the very beginning an “architect” can take up the work with the uncompromising desire to build his own “framework” with blackjack and girls when there is still no clear vision of what the team, project and customer need. As a result, each project is cluttered with curved libraries and frameworks, which are inconvenient to use, and expensive to maintain.
The problem is that the costs of design, implementation and maintenance of publicly available code are several orders of magnitude higher than the cost of maintaining a simple custom solution. It all starts with the fact that the reusable code requires more complete and detailed documentation, better quality and test coverage, examples of use and user documentation. Even if the code is intended for reuse within the team, its quality and ease of use should be such that it is economically beneficial for the programmer to sort out your decision and not to fence your own favorite garden. And I'm not talking about the need for a culture of reuse, without which the whole idea of a “reuse” will be covered with a copper basin thanks to the well-loved NIH symptom (Not Invented Here).
When it comes not to libraries, but to the “flexibility” of specific solutions, we are faced with a similar problem. Many believe that a “generic” solution (with a lot of room for expansion) is the best way to handle future changes. Perhaps this is true, but practice shows that it is very easy to slide from this path to a cumbersome code that is difficult to understand (because it can do everything) and accompany. If you think that some aspect of behavior can change, then it is enough to hide it behind an abstract interface and make this aspect a detail of the implementation. As in the case of productivity, programmers (and architects) have little idea what exactly will change in the future and what new needs will arise. And if so, then there is nothing better than a simple solution that can be easily adapted to changing requirements by modifying it.
All these difficulties do not say that reuse is stupid. Not. Just as the performance optimization should be carried out after profiling, so the generalization should be done in Time: not during the development of the feature itself, but at later stages, when the team understands where possible changes will be directed and what needs to be generalized, and what - not.
Modified iteration life cycle
Here you need to understand a very important point: the step of generalization is not in itself a sufficient condition for creating a reusable code, just like the profiling process does not guarantee that you can improve the performance of the found bottle neck. This is only a stage during which a simple and adequate solution obtained at the design and implementation stage is “combed” additionally to bring it to the level of reuse: unnecessary dependencies are removed, documentation is improved, additional unit tests are added. If during the implementation everything is crumpled up and made such a tangle out of the system, that it is impossible to understand without a bottle, then there can be no talk of a future “reuse”. But if you start with a simple and understandable architecture that solves the task well, then combining several solutions of the same type into one will be much easier when it is already precisely clear what they have in common.
NOTE
In this case, I do not consider the development of libraries as a separate product. The library was originally sharpened for reuse and there a lot is being done differently; it is enough to look through the Framework Design Guidelines to understand that when developing a library, its quality, usability, absence of breaking changes, intuitive clarity, “hierarchy”, and much more come to the fore. Here we are not talking about libraries for the general public, but about problems with reuse in typical enterprise applications.
The generalization step does not have to be formal or take place at each iteration of development, but sooner or later the team will need to make additional efforts to bring the code (and design) to mind, which means that the project leaders should be aware of it.
Conclusion
Unfortunately, even the stage of generalization is not a guarantee of increasing the “reuse” of the code. The first problem is connected with knocking out extra time for the management of an incomprehensible generalization, instead of riveting the new functionality of the next iteration. Yes, everyone talks about the importance of reuse, but when it comes to additional costs, the short-sightedness of project managers may play a role and will be denied in the synthesis. There is a grain of truth in this; The second problem is that the availability of high-quality code that is available for reuse does not guarantee its use. For a normal "reyuz", culture is also needed, and the beloved NIH and the thirst for cycling can be so strong that any attempt to reuse will lead to nothing.
But, in any case, my advice is to ensure that when choosing simplicity versus “flexibility” for future changes , you would stop on simplicity. After all, if the solution is simple, then it is easy to modify it for future needs, or summarize it for reuse. Well, if nothing is needed, then you just save time and energy, and you will live with this simple solution for many years.
NOTE
The idea of the generalization stage was suggested by Bertrand Meyer in his book “Object-Oriented Design of Software Systems” , so some details can be found in the section “28.5 Generalization” (by the way, this is really an excellent book in which you can find many interesting ideas about OOP and software development).
Source: https://habr.com/ru/post/143441/
All Articles