What the .git directory hides from us
So I was lucky to get acquainted with git. I repent, using Subversion, I knew how to do what I needed in IDEA or TortoiseSVN, but I didn’t even know what was going on behind the scenes. In this case, I decided to approach git more responsibly and carefully examine it before use. Now I know which commands I should use to carry out my plans, but I don’t know how to do this in IDEA or TortoiseSVN.
But I decided to go even further and find out what is happening in the .git directory itself. It turned out to be so interesting and simple that I decided to share this with you.
This is what git looks like after the git init command.
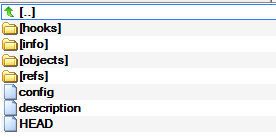
')
This is not all that you can see, as with further work other files and directories will appear. For example, it looks like .git on my working draft.
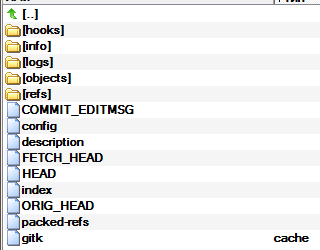
I will not describe the purpose of each file, but will highlight the main points.
The most important elements are objects, refs, HEAD, index. In order to understand what it is and what they eat, we will create several files, a directory, and add them to our repository.
Initially, the objects directory contains empty pack and info subdirectories and no files.
Create a file in the working directory test.txt with the contents of the "test file version 1".
Add this file to the index.
Now let's see what has changed in our repository.
A file has been added to the objects directory. It should be noted that all files in this directory are git objects of a certain type.
Let's look at the contents and type of this object using the cat-file command.
This object is of type blob. This is the initial presentation of data in Git - one file per storage unit with a name, which is calculated as the SHA1 hash of the content and the title of the object. The first two SHA characters define a subdirectory of the file, the remaining 38 - the name. This object simply stores a snapshot of the contents of the test.txt file.
Further we see that the index file has appeared. This is a binary file containing a list of indexed files and associated blob objects.
That is, the index contains all the necessary information for creating a tree object on a subsequent commit. A tree object is another type of object in git. A little later we will meet with him.
Now add the new directory and the file new / new.txt
Let's find out the type of the new object and its contents.
And look again at the index.
And now all this zakommitim.
Now our repository contains 5 objects.
Added three more files. Let's see what these files are.
This is another type of git object - a tree object. An object of this type contains one or more records pointing to another tree or to a blob object.
Finally, the last object type is the commit object.
We see the top-level tree I mentioned earlier, the name of the author and the committer and the commit message.
Let's make a new change (in test.txt we change the text to “test file version 2”) and commit it. In addition to the link to the tree, there was also a link to the previous commit.
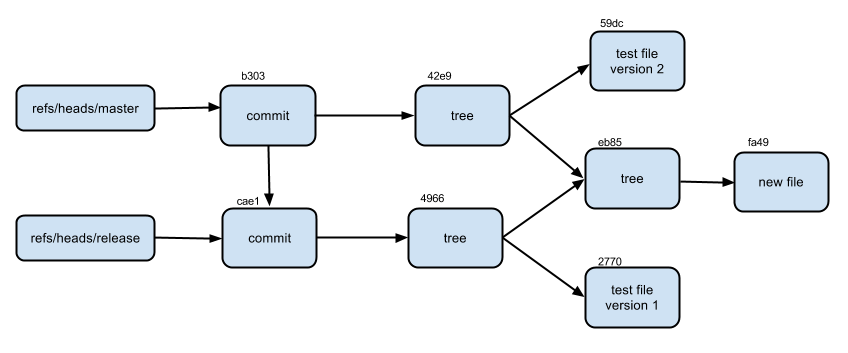
To make everything fall into place, draw a graph of objects

In git, a link is a pointer file with a simple name that contains the value of the SHA-1 hash. These files are located in the directory .git / refs /
Since we have only one master branch, the link is also only one, which indicates the last commit.
Let's make a brunch release pointing to the first commit.
That's basically what a branch in git is - a simple pointer to a particular commit.
Let's see more clearly
This file contains a link not to the hash, but to the current branch.
If you move to another branch, then the content of this file will change.
And there are more tags, deleted links, the info directory and many many tasty things.
But I decided to go even further and find out what is happening in the .git directory itself. It turned out to be so interesting and simple that I decided to share this with you.
This is what git looks like after the git init command.
')
This is not all that you can see, as with further work other files and directories will appear. For example, it looks like .git on my working draft.
I will not describe the purpose of each file, but will highlight the main points.
The most important elements are objects, refs, HEAD, index. In order to understand what it is and what they eat, we will create several files, a directory, and add them to our repository.
Objects
Initially, the objects directory contains empty pack and info subdirectories and no files.
Create a file in the working directory test.txt with the contents of the "test file version 1".
$ echo 'test file version 1' > test.txt Add this file to the index.
$ git add test.txt Now let's see what has changed in our repository.
$ find .git/objects .git/objects/27/703ec79a98c1d097d5b1cd320befffa376e826 A file has been added to the objects directory. It should be noted that all files in this directory are git objects of a certain type.
Let's look at the contents and type of this object using the cat-file command.
$ git cat-file -p 2770 test file version 1 $ git cat-file -t 2770 blob This object is of type blob. This is the initial presentation of data in Git - one file per storage unit with a name, which is calculated as the SHA1 hash of the content and the title of the object. The first two SHA characters define a subdirectory of the file, the remaining 38 - the name. This object simply stores a snapshot of the contents of the test.txt file.
Further we see that the index file has appeared. This is a binary file containing a list of indexed files and associated blob objects.
$ git ls-files --stage 100644 27703ec79a98c1d097d5b1cd320befffa376e826 0 test.txt That is, the index contains all the necessary information for creating a tree object on a subsequent commit. A tree object is another type of object in git. A little later we will meet with him.
Now add the new directory and the file new / new.txt
$ mkdir new $ echo "new file" > new/new.txt $ git add . $ find .git/objects -type f .git/objects/27/703ec79a98c1d097d5b1cd320befffa376e826 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 Let's find out the type of the new object and its contents.
$ git cat-file -p fa49 new file $ git cat-file -t fa49 blob And look again at the index.
$ git ls-files --stage 100644 fa49b077972391ad58037050f2a75f74e3671e92 0 new/new.txt 100644 27703ec79a98c1d097d5b1cd320befffa376e826 0 test.txt And now all this zakommitim.
$ git commit -m "first commit" [master (root-commit) cae1990] first commit 2 files changed, 2 insertions(+), 0 deletions(-) create mode 100644 new/new.txt create mode 100644 test.txt Now our repository contains 5 objects.
$ find .git/objects -type f .git/objects/27/703ec79a98c1d097d5b1cd320befffa376e826 .git/objects/49/66bf4e5c88c5f9d149b45bb2f3099644701d93 .git/objects/ca/e19909974ee9e64f5787fe4ee89b9b8fe94ccf .git/objects/eb/85079ce7fd354ffc630f4a8e2991196cb3807f .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 Added three more files. Let's see what these files are.
$ git cat-file -t 4966 tree $ git cat-file -p 4966 040000 tree eb85079ce7fd354ffc630f4a8e2991196cb3807f new 100644 blob 27703ec79a98c1d097d5b1cd320befffa376e826 test.txt $ git cat-file -t eb85 tree $ git cat-file -p eb85 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt This is another type of git object - a tree object. An object of this type contains one or more records pointing to another tree or to a blob object.
Finally, the last object type is the commit object.
$ git cat-file -p cae1 tree 4966bf4e5c88c5f9d149b45bb2f3099644701d93 author Ivan Ivanov <i_ivanov@adam.net> 1335783964 +0300 committer Ivan Ivanov <i_ivanov@adam.net> 1335783964 +0300 first commit We see the top-level tree I mentioned earlier, the name of the author and the committer and the commit message.
Let's make a new change (in test.txt we change the text to “test file version 2”) and commit it. In addition to the link to the tree, there was also a link to the previous commit.
$ git cat-file -p b303 tree 42e998096f18d4249dc00ec89eaaadc44a8bf3cb parent cae19909974ee9e64f5787fe4ee89b9b8fe94ccf author Ivan Ivanov <i_ivanov@adam.net> 1335786789 +0300 committer Ivan Ivanov <i_ivanov@adam.net> 1335786789 +0300 second commit To make everything fall into place, draw a graph of objects
Links
In git, a link is a pointer file with a simple name that contains the value of the SHA-1 hash. These files are located in the directory .git / refs /
$ find .git/refs .git/refs .git/refs/heads .git/refs/heads/master .git/refs/tags Since we have only one master branch, the link is also only one, which indicates the last commit.
Let's make a brunch release pointing to the first commit.
$ git branch release cae1990 $ find .git/refs .git/refs .git/refs/heads .git/refs/heads/master .git/refs/heads/release .git/refs/tags $ cat .git/refs/heads/release cae19909974ee9e64f5787fe4ee89b9b8fe94ccfa That's basically what a branch in git is - a simple pointer to a particular commit.
Let's see more clearly
HEAD
This file contains a link not to the hash, but to the current branch.
$ cat .git/HEAD ref: refs/heads/master If you move to another branch, then the content of this file will change.
$ git co release Switched to branch 'release' $ cat .git/HEAD ref: refs/heads/release Instead of the total
And there are more tags, deleted links, the info directory and many many tasty things.
Source: https://habr.com/ru/post/143079/
All Articles