Multithreaded QuickSort in C ++ 2011
Personally, with all my faith in C ++, I believe that even in the 2011 edition, this language is extremely unfriendly in terms of multitasking and multithreading. As another attempt to convince myself of this, I tried to make multi-threaded QuickSort.
In this algorithm, it turns out after the partitioning phase to start sorting sub-parts in parallel.
Here is my naive bike:
The implementation is extremely simple, but it is worth noting a few points. There is some kind of constant 4096 that defines the threshold when parallel execution is turned off. Why exactly such a value? I do not know. Taken out of thin air with a minimal sense of common sense. When parallelism is active, the sorting of the left array is started via async in another stream, and the right one is sorted as before in the current stream. When exiting the function context, it is guaranteed that the task launched via
')
Traditionally, puzomerka spherical horses in a vacuum. Three candidates:
An array of 50000000 int64 type elements (with a sign) is sorted. 10 experiments are being done, and it is considered average. Values are generated randomly:
Do not ask why there is distilled from big endian back and forth. This was made to compare with another program in Java. When measuring time, only “pure time” is taken into account.
Compiler VS 2011, 64-bit. Intel Core i5 2.53GHz processor, 4 cores.
The time is in milliseconds.
It turns out about three times faster. A strange slight lag
Are there practical benefits in this parallelism? I think no. It is very difficult to assess the stability of the algorithm on different data. For example, it is not at all clear how to choose the threshold for disabling multitasking? Should I use a pool of threads?
If anyone is interested, below is the full text of this bike, including the data generator.
Building and generating data:
Caution! The generator will create data for 8 gigs.
Build and experiment:
File sort_async.cpp:
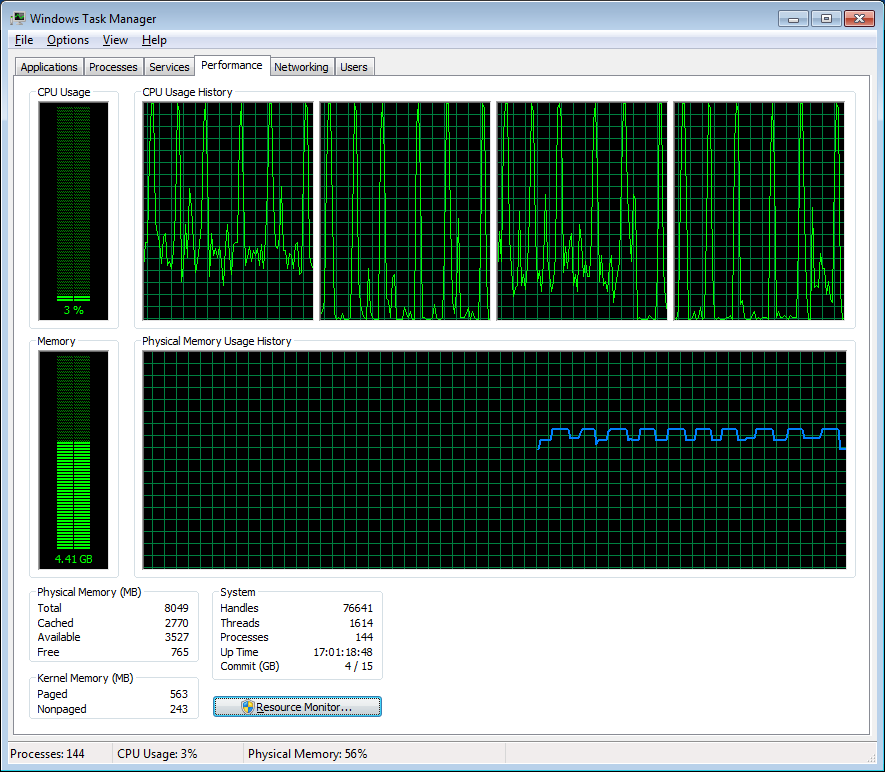
Under the curtain, the picture of loading processors. Bursts are clearly visible at each iteration when the system is used up.
Additive
An interesting article from Microsoft, Dynamic Task Parallelism , which also shows a variant of multi-threaded Quicksort.
In this algorithm, it turns out after the partitioning phase to start sorting sub-parts in parallel.
Here is my naive bike:
int naive_quick_sort(std::vector<Type>::iterator begin, std::vector<Type>::iterator end) { auto const sz = end - begin; if (sz <= 1) return 0; auto pivot = begin + sz/2; auto const pivot_v = *pivot; std::swap(*pivot, *(end - 1)); auto p = std::partition(begin, end, [&](const Type& a) { return a < pivot_v; } ); std::swap(*p, *(end - 1)); if (sz > 4096) { auto left = std::async(std::launch::async, [&]() { return naive_quick_sort(begin, p); }); naive_quick_sort(p + 1, end); } else { naive_quick_sort(begin, p); naive_quick_sort(p + 1, end); } return 0; } void quick_sort(std::vector<Type>& arr) { naive_quick_sort(arr.begin(), arr.end()); } The implementation is extremely simple, but it is worth noting a few points. There is some kind of constant 4096 that defines the threshold when parallel execution is turned off. Why exactly such a value? I do not know. Taken out of thin air with a minimal sense of common sense. When parallelism is active, the sorting of the left array is started via async in another stream, and the right one is sorted as before in the current stream. When exiting the function context, it is guaranteed that the task launched via
async will be completed (it will wait for completion).')
Traditionally, puzomerka spherical horses in a vacuum. Three candidates:
- the above implementation (via async)
- it is the same, but in one stream (
if (sz > 4096)replace withif (false)) std::sort()(naive_quick_sort(arr.begin(), arr.end())replacestd::sort(arr.begin(), arr.end()))
An array of 50000000 int64 type elements (with a sign) is sorted. 10 experiments are being done, and it is considered average. Values are generated randomly:
std::tr1::uniform_int<Type> uniform( std::numeric_limits<Type>::min(), std::numeric_limits<Type>::max()); std::mt19937_64 engine; void generate(std::vector<Type>& v) { std::for_each(v.begin(), v.end(), [](Type& i) { i = uniform(engine); }); } Do not ask why there is distilled from big endian back and forth. This was made to compare with another program in Java. When measuring time, only “pure time” is taken into account.
Compiler VS 2011, 64-bit. Intel Core i5 2.53GHz processor, 4 cores.
async() std::sort() --------- --------------- ------------ ------------ 1 2512 6555 7309 2 2337 6320 6977 3 2450 6516 7180 4 2372 6388 6933 5 2387 7074 7189 6 2339 7399 7040 7 2434 6875 7040 8 2562 7060 7187 9 2470 7050 7145 10 2422 6846 6898 --------- --------------- ------------ ------------ 2428.5 6808.3 7089.8 The time is in milliseconds.
It turns out about three times faster. A strange slight lag
std::sort() most likely due to the fact that the data is “good”, and my simple implementation is really lucky with them. It can be seen that the time std::sort() deviation is much smaller. Still, stl::sort() is stable in time, regardless of data.Are there practical benefits in this parallelism? I think no. It is very difficult to assess the stability of the algorithm on different data. For example, it is not at all clear how to choose the threshold for disabling multitasking? Should I use a pool of threads?
If anyone is interested, below is the full text of this bike, including the data generator.
Building and generating data:
call "%VS110COMNTOOLS%..\..\VC\vcvarsall.bat" amd64 && ^ cl /Ox /DWIN32 sort_async.cpp && ^ sort_async generate Caution! The generator will create data for 8 gigs.
Build and experiment:
call "%VS110COMNTOOLS%..\..\VC\vcvarsall.bat" amd64 && ^ cl /Ox /DWIN32 sort_async.cpp && ^ sort_async File sort_async.cpp:
#include <vector> #include <iostream> #include <fstream> #include <sstream> #include <algorithm> #include <iomanip> #include <future> #include <random> #include <chrono> #include <cstdlib> const int ITERATIONS_NUM = 10; const int DATA_SIZE = 50000000; typedef __int64 Type; inline void endian_swap(Type& x) { x = (0x00000000000000FF & (x >> 56)) | (0x000000000000FF00 & (x >> 40)) | (0x0000000000FF0000 & (x >> 24)) | (0x00000000FF000000 & (x >> 8)) | (0x000000FF00000000 & (x << 8)) | (0x0000FF0000000000 & (x << 24)) | (0x00FF000000000000 & (x << 40)) | (0xFF00000000000000 & (x << 56)); } std::tr1::uniform_int<Type> uniform( std::numeric_limits<Type>::min(), std::numeric_limits<Type>::max()); std::mt19937_64 engine; void generate(std::vector<Type>& v) { std::for_each(v.begin(), v.end(), [](Type& i) { i = uniform(engine); }); } void check_sorted(const std::vector<Type>& v, const std::string& msg) { for (auto i = 0; i < v.size() - 1; ++i) { if (v[i] > v[i + 1]) { std::cout << "\nUnsorted: " << msg << "\n"; std::cout << "\n" << i << "\n"; std::cout << v[i] << " " << v[i + 1] << "\n"; std::exit(1); } } } std::string data_file_name(const int i, const std::string& suffix) { std::ostringstream fmt; fmt << "trash_for_sort_" << i << suffix << ".bin"; return fmt.str(); } void save_file(std::vector<Type> array, const std::string& name) { std::for_each(array.begin(), array.end(), [](Type& i) { endian_swap(i); }); std::ofstream os(name.c_str(), std::ios::binary|std::ios::out); auto const bytes_to_write = array.size() * sizeof(array[0]); std::cout << "Saving " << array.size() << " bytes to " << name << "\n"; os.write((char *)&array[0], bytes_to_write); } int main_generate(int argc, char* argv[]) { std::cout << "Generation\n"; for (auto i = 0; i < ITERATIONS_NUM; ++i) { std::vector<Type> unsorted(DATA_SIZE); generate(unsorted); save_file(unsorted, data_file_name(i, "")); std::cout << "Sorting...\n"; std::sort(unsorted.begin(), unsorted.end()); check_sorted(unsorted, "check sorted array"); save_file(unsorted, data_file_name(i, "_sorted")); } return 0; } void load_file(std::vector<Type>& array, const std::string& name) { std::cout << "Loading " << name; array.resize(DATA_SIZE, 0); std::ifstream is(name.c_str(), std::ios::binary|std::ios::in); auto const to_load = array.size() * sizeof(array[0]); is.read((char *)&array[0], to_load); if (is.gcount() != to_load) { std::cerr << ", Bad file " << name << ", loaded " << is.gcount() << " words but should be " << to_load << "\n"; std::exit(1); } std::for_each(array.begin(), array.end(), [](Type& v){ endian_swap(v); }); } int naive_quick_sort(std::vector<Type>::iterator begin, std::vector<Type>::iterator end) { auto const sz = end - begin; if (sz <= 1) return 0; auto pivot = begin + sz/2; auto const pivot_v = *pivot; std::swap(*pivot, *(end - 1)); auto p = std::partition(begin, end, [&](const Type& a) { return a < pivot_v; } ); std::swap(*p, *(end - 1)); if (sz > 4096) { auto left = std::async(std::launch::async, [&]() { return naive_quick_sort(begin, p); }); naive_quick_sort(p + 1, end); } else { naive_quick_sort(begin, p); naive_quick_sort(p + 1, end); } return 0; } void quick_sort(std::vector<Type>& arr) { naive_quick_sort(arr.begin(), arr.end()); } int main(int argc, char* argv[]) { if (argc == 2 && !std::strcmp(argv[1], "generate")) return main_generate(argc, argv); std::vector<double> times; auto times_sum = 0.0; for (auto i = 0; i < ITERATIONS_NUM; ++i) { std::vector<Type> unsorted; load_file(unsorted, data_file_name(i, "")); std::vector<Type> verify; std::cout << ", "; load_file(verify, data_file_name(i, "_sorted")); check_sorted(verify, "verify array"); std::cout << ", Started"; auto start = std::chrono::high_resolution_clock::now(); quick_sort(unsorted); auto stop = std::chrono::high_resolution_clock::now(); std::cout << ", Stopped, "; auto duration = std::chrono::duration<double>(stop - start).count(); std::cout << duration; check_sorted(unsorted, "sorted array"); const auto match = unsorted == verify; std::cout << (match ? ", OK" : ", DON'T MATCH"); times.push_back(duration); times_sum += duration; std::cout << "\n"; } auto const average = times_sum / ITERATIONS_NUM; auto const max_element = *std::max_element(times.begin(), times.end()); auto const min_element = *std::min_element(times.begin(), times.end()); auto const average_fixed = (times_sum - max_element - min_element) / (ITERATIONS_NUM - 2); std::cout << "Average: " << average << "s, " << "Average without max/min: " << average_fixed << "s." << std::endl; } Under the curtain, the picture of loading processors. Bursts are clearly visible at each iteration when the system is used up.
Additive
An interesting article from Microsoft, Dynamic Task Parallelism , which also shows a variant of multi-threaded Quicksort.
Source: https://habr.com/ru/post/143055/
All Articles