Prototype data model
In the prototype data model, objects are created on the basis of other objects. In this case, the object has a prototype, it can still be called a benchmark or an inherited object. In such a data model, there are no types and classes. Objects can be distinguished by who they are prototyping, but this task is secondary. Prototyping is primarily used to reuse existing structures from objects.

An object is an elementary entity that has a name, a value, and some other attributes that are standard for all objects. You can call an object in different ways, but as you call it, it will mean it. The value is scalar; you can represent numbers, addresses, dates, paths to files, text, and more. The length of the value is not limited. Elementary objects provide the flexibility to build complex structures.
To represent complex data structures, such as catalogs, products with multiple properties, objects are structured into a hierarchy. Each object is capable of subordinating an unlimited number of objects, while being subordinate to only one other object, which is not in its subordination. The usual hierarchy of objects. With the help of a hierarchy, humanity has long since been structuring knowledge about the real world; it is a natural and convenient way of presenting information. Hierarchy in all.
')

But one hierarchy does not simulate objects of the real or imaginary world. For example, the goods are not placed simultaneously in several catalogs. It is necessary to link objects from different branches of the hierarchy.
At this stage, a prototype model is born. In addition to the name and value, each object with no exceptions can have a link to any other object, no matter where it is. It is the link that forms the connection with the prototype. The link is implemented by an additional object attribute representing the prototype identifier. An object can have only one link.
Now you can add an existing product from another catalog to the desired catalog by creating an item object, prototyping it from the second catalog item. In fact, a new product will appear, but without duplicating the properties (subordinate properties of the product). Turning to a new product, we will be able to operate with the properties of its prototype.
But a product in a store may have a different set of characteristics: size, color, while having the same item, name, manufacturer, and not a small list of other properties. With the prototype data model, you only need to add redefinable properties in a new prototyped product, in particular, add a color property with a specific value. Now the new product has its own color, and the remaining properties will be taken from the prototype.
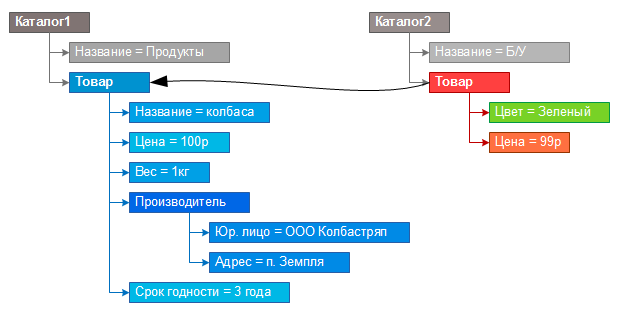
Prototyping allows you to reuse objects, create new ones based on existing ones, modify and supplement them without affecting the original ones, directly solve problems, rather than create metadata to solve them.
It is not enough to have only data structures. They need to be revived, endowing objects with logic. The logic is implemented by the methods (functions) of the object. There may be methods for checking an object before saving, methods for processing requests, forming a display, and any other. It all depends on the purpose of the object. When prototyping a new object along with the properties of the prototype inherits its logic, of course, with the ability to supplement and redefine it.
To identify objects, surrogate keys, such as integers, are commonly used. Due to the lack of boundaries of binding one object to any other, the key uniqueness must be ensured within the framework of the entire data structure. Therefore, it is ideal to have an unlimited range of values for a key. More precisely, the unattainable limit of values within the projected system. But the problem is not in this, but in the existence of objects that cannot permanently possess a surrogate key, since they themselves are created at the time of addressing them and for the time of their use. They are not in the database, which means that there is no possibility to contact them by key.
There are two ways to implement prototyping. In the first method, the prototype is completely copied, the new object receives copies of all subordinates of the prototype. In cases of prototype changes, it is necessary to update all prototyped objects and their subordinates that have not yet been redefined. The downside is the complexity of updating and duplicating data, but we can identify any object.
The second method involves only the installation of communication with the prototype. No need to copy and update anything. But when we operate with an object that has a prototype, and we appeal to the subordinates of the prototype, these subordinates should be perceived by the subordinates of the operated object. In cases of modification of such subordinates, the changes in no case should touch the prototype. Modified objects should be saved as new subordinates of the operated object. While objects are not saved, they are virtual, temporarily created, prototyped from the corresponding subordinates of the prototype. These objects can not be addressed directly, it is necessary to contact them from their parent, since their existence depends on the parent.
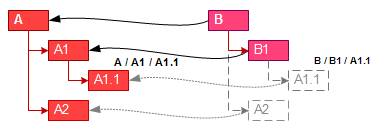
Whatever objects are, they still need to be identified. The ability to refer to an object (to predetermine a link) is necessary even if the object is missing. The use of object naming will help here if you make their names unique within one nesting level. Then objects can be accessed through the path on them as files.
The prototype data model is distinguished by its flexibility and natural structure. It is not necessary to fence auxiliary entities, for example, to implement many-to-many connections, to design data structures, trying to envisage all the options for project development, because in cases where you only need to transfer data to another branch, it’s the same as to permute into room without reworking its layout. But, due to the lack of ready-made solutions, the prototype model has to be modeled on other data models. For example, relational, from which manifest various problems and limitations. I leave this question open for discussion. If someone takes up the creation of a database with a prototype model, call me to the team.
Additional Information:
1. Application of the model in the CMS architecture: boolive.ru/createcms/data-and-logic-model
2. Implementation on MySQL with regard to horizontal scaling: boolive.ru/createcms/sectioning
Structure
An object is an elementary entity that has a name, a value, and some other attributes that are standard for all objects. You can call an object in different ways, but as you call it, it will mean it. The value is scalar; you can represent numbers, addresses, dates, paths to files, text, and more. The length of the value is not limited. Elementary objects provide the flexibility to build complex structures.
To represent complex data structures, such as catalogs, products with multiple properties, objects are structured into a hierarchy. Each object is capable of subordinating an unlimited number of objects, while being subordinate to only one other object, which is not in its subordination. The usual hierarchy of objects. With the help of a hierarchy, humanity has long since been structuring knowledge about the real world; it is a natural and convenient way of presenting information. Hierarchy in all.
')
But one hierarchy does not simulate objects of the real or imaginary world. For example, the goods are not placed simultaneously in several catalogs. It is necessary to link objects from different branches of the hierarchy.
Inheritance
At this stage, a prototype model is born. In addition to the name and value, each object with no exceptions can have a link to any other object, no matter where it is. It is the link that forms the connection with the prototype. The link is implemented by an additional object attribute representing the prototype identifier. An object can have only one link.
Now you can add an existing product from another catalog to the desired catalog by creating an item object, prototyping it from the second catalog item. In fact, a new product will appear, but without duplicating the properties (subordinate properties of the product). Turning to a new product, we will be able to operate with the properties of its prototype.
But a product in a store may have a different set of characteristics: size, color, while having the same item, name, manufacturer, and not a small list of other properties. With the prototype data model, you only need to add redefinable properties in a new prototyped product, in particular, add a color property with a specific value. Now the new product has its own color, and the remaining properties will be taken from the prototype.
Prototyping allows you to reuse objects, create new ones based on existing ones, modify and supplement them without affecting the original ones, directly solve problems, rather than create metadata to solve them.
Logics
It is not enough to have only data structures. They need to be revived, endowing objects with logic. The logic is implemented by the methods (functions) of the object. There may be methods for checking an object before saving, methods for processing requests, forming a display, and any other. It all depends on the purpose of the object. When prototyping a new object along with the properties of the prototype inherits its logic, of course, with the ability to supplement and redefine it.
Identification
To identify objects, surrogate keys, such as integers, are commonly used. Due to the lack of boundaries of binding one object to any other, the key uniqueness must be ensured within the framework of the entire data structure. Therefore, it is ideal to have an unlimited range of values for a key. More precisely, the unattainable limit of values within the projected system. But the problem is not in this, but in the existence of objects that cannot permanently possess a surrogate key, since they themselves are created at the time of addressing them and for the time of their use. They are not in the database, which means that there is no possibility to contact them by key.
There are two ways to implement prototyping. In the first method, the prototype is completely copied, the new object receives copies of all subordinates of the prototype. In cases of prototype changes, it is necessary to update all prototyped objects and their subordinates that have not yet been redefined. The downside is the complexity of updating and duplicating data, but we can identify any object.
The second method involves only the installation of communication with the prototype. No need to copy and update anything. But when we operate with an object that has a prototype, and we appeal to the subordinates of the prototype, these subordinates should be perceived by the subordinates of the operated object. In cases of modification of such subordinates, the changes in no case should touch the prototype. Modified objects should be saved as new subordinates of the operated object. While objects are not saved, they are virtual, temporarily created, prototyped from the corresponding subordinates of the prototype. These objects can not be addressed directly, it is necessary to contact them from their parent, since their existence depends on the parent.
Whatever objects are, they still need to be identified. The ability to refer to an object (to predetermine a link) is necessary even if the object is missing. The use of object naming will help here if you make their names unique within one nesting level. Then objects can be accessed through the path on them as files.
PS
The prototype data model is distinguished by its flexibility and natural structure. It is not necessary to fence auxiliary entities, for example, to implement many-to-many connections, to design data structures, trying to envisage all the options for project development, because in cases where you only need to transfer data to another branch, it’s the same as to permute into room without reworking its layout. But, due to the lack of ready-made solutions, the prototype model has to be modeled on other data models. For example, relational, from which manifest various problems and limitations. I leave this question open for discussion. If someone takes up the creation of a database with a prototype model, call me to the team.
Additional Information:
1. Application of the model in the CMS architecture: boolive.ru/createcms/data-and-logic-model
2. Implementation on MySQL with regard to horizontal scaling: boolive.ru/createcms/sectioning
Source: https://habr.com/ru/post/142890/
All Articles