Erlang. Recommendations for code design
Not so long ago, the team had to invite a new programmer and introduce him to Erlang. To speed up the learning process, I decided to translate Erlang Programming Rules and Conventions for a long time. What, in principle, I want to share with habrovchanami. I hope that it will be useful to those who are going to learn or already use this wonderful language. I must say that the translation is free, so do not criticize much.
This article lists some aspects that should be considered when developing software using Erlang.
All Erlang subsystems are divided into modules. modules in turn consist of functions and attributes.
Functions can be either internal or exported for use in third-party modules.
Attributes start with a '-' and are placed at the beginning of the module.
All work in the Erlang architecture is carried out by threads. A thread in turn is a set of instructions that can use the function calls of various modules. Streams can communicate with each other by sending messages. Also, upon receipt, they can determine which messages need to be processed first. The rest of the messages remain in the queue until
there will be no need.
')
Streams can follow each other's work through binding ( link command). When a thread finishes its execution or a signal is automatically dropped, a signal is sent to all associated threads.
The default response to this signal for a thread is to immediately stop the operation.
But this behavior can be changed by setting the trap_exit flag, in which the signals are converted to messages and can be processed by the program.
Pure functions are functions whose value depends only on the input data and does not depend on the context of the call. With this behavior, they are similar to ordinary mathematics. Those who are not clean are said to be functions with side effects.
A side effect usually occurs if the function:
Modules are the basic structural unit in Erlang. They may contain a huge number of functions, but only those included in the export list will be available to third-party modules.
The complexity of the module depends on the number of exported functions. Agree, because it is easier to deal with the module that exports a couple of functions than the one that exports a dozen.
After all, the user needs to understand only those that are exported.
In addition, the one who accompanies the module code can be without fear of changing the internal functions, because the interface to the module remains unchanged.
A module that appeals to many others is much more difficult to maintain, because if changes
interface, it is necessary to change the code wherever this module was used.
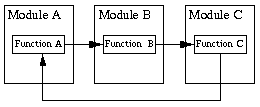
Remember, ideally, module calls should be a tree and not a graph with cycles. (from myself. For this, the Wrangler refactoring tool has a convenient mechanism based on GraphViz that can draw a function call graph)
As a result, the call code should be represented like this:

But not:
In the library (module) there should be a set of related functions only.
The task of the developer is to create libraries that contain functions of the same type.
Thus, for example, the lists library, which contains the code for working with lists, is an example of good architecture, and lists_and_method , which contains both the code for working with lists and mathematical algorithms, is bad.
Best of all, when all the functions in the library do not contain side effects. Then it can be easily reused.
Often the solution to a problem requires the sharing of clean and dirty code.
Separate such areas into different modules.
For example, "dirty code":
Try to write as much clean code as possible, and “dirty”, firstly use as little as possible, and secondly, document all possible side effects and usage problems.
Do not think about how the calling function will use the result of your execution.
For example, suppose you call the route function, passing arguments to it that may not be correct. The creator of the route function should not think about what we will do when the arguments are not correct.
No need to write code like this:
Better to do this:
In the first case, the error is always output to the console, in the second, the error description is simply returned. The application developer can decide for himself what to do with it - ignore or lead to the printed form using error_report / 1 . In any case, he has the right to choose what to do when an error occurs.
If some code in the code begins to repeat itself, try to separate it into a separate function or module. So it will be much easier to maintain it than multiple copies scattered around the program.
Do not use "Copy & Paste", use functions!
Develop a program from top to bottom. This will allow you to gradually detail the code until you reach the primitive functions. The code written in this way does not depend on the presentation of the data, since the representation is not yet known when you are developing at a higher level.
Do not optimize the code at the initial stage of development. First make it work properly, and only then, if the need arises, engage in optimization.
The result of the functions should not be a surprise to the user. Functions that perform similar actions should look the same, or at least be similar. The user must be able to predict what the function may return. If the result of the execution does not meet expectations, then either the name of the function does not match its purpose, or the function code itself does not work correctly.
Erlang has several primitives with side effects. Functions that use them are not easy to reuse, because they depend on the environment and the programmer needs to monitor the state of the stream before the call.
Write as much code as possible without side effects.
Clearly document all possible problems when using non-pure functions. This greatly facilitates the writing of tests and support.
The easiest way to demonstrate an example. Suppose there is a queue management function:
She describes the queue as a list. And used like this:
Several problems follow from this:
Much better to write like this:
Now use will look like this:
This code is devoid of the disadvantages described above.
Now suppose you need to know the length of the queue. If the user knows that the queue is a list he will write:
Again, problems, since the user again tightly links the implementation with the view, such code is hard to maintain and read. For this case, it is better to provide a separate function and add to the module:
Now the user will be able to call his queue: len (Queue) instead of his code.
In this code, we "abstracted" from the details of the implementation of the data type queue. Those. in other words, the queue is now “abstract data type”.
Why all this trouble? In practice, it turned out to be an easy mechanism for replacing the internal representation, and now you can change the implementation of your module without fear of breaking backward compatibility with the user code. For example, for better implementation, the code is rewritten as
Deterministic programs always behave in the same way regardless of how many times they are run. Non-deterministic can behave differently with each launch. The first option is much easier to debug and allows you to track down and avoid many mistakes, so try to stick with it.
For example, the program should launch 5 different threads, and then check that they started, and the launch order is not important.
You can start all 5 at once, and then check, but it is better to run them in turn, each time checking whether the stream started and only after that start the next one.
Often, programmers do not trust the input data for the part of the system they are developing. Most of the code should not care about the correctness of the data transmitted to it. Verification should occur only when data is transmitted from outside.
For example:
The function will terminate with an error if Option is not normall or all . So it should be! Whoever calls this function must control what is passed to it.
Equipment must be isolated from the system using a driver. The task of the driver is to present the hardware in the system as if it were just an Erlang stream, which, like a simple stream, receives and sends messages and responds to errors.
Suppose there is a code that opens a file, does something from it and then closes it.
Please note that opening and closing a file occurs in the same function. The code is easy to read and understand. But, for example, such code is harder to understand and it is not immediately clear when the file is closed:
Do not mix the normal code with the error handling code. You must program the normal behavior. If something goes wrong, the process should immediately terminate with an error. Do not try to correct the error and continue. Error handling must take another process.
One of the development stages is to determine which part of the system should always function without errors, and which part is allowed.
For example, in operating systems, the kernel should function without errors, while normal applications may fail with an error, but this will not affect the functioning of the system as a whole.
The part that should always work correctly we call the “core of errors”. This part, as a rule, constantly stores its intermediate state in the database or on disk.
Of course, it should be understood that the thread calls functions from other modules, but here we are talking about the fact that the main loop of the thread should be in one module, and not split into several. Otherwise, it will be hard to control the progress. It also does not mean that you should not use generic libraries. They are just meant to help organize the flow.
Also, do not forget that the code common to several threads must be implemented in a completely separate module.
Flows are the basic structural elements of a system. But do not use them and sending a message when it is possible to simply call a function.
Threads must be registered under the same name as the name of the module that contains their code. This will greatly facilitate support. Register only those streams that you plan to use for a long time.
Using threads or solving a problem consistently depends directly on the problem we are trying to solve. But it is desirable to be guided by one main rule:
"Use one thread for every parallel process in the real world."
If you follow this rule, the logic of the program will be easy to understand.
Threads can perform different roles in the system. For example, in a client-server architecture, a stream can be both a client and a server, but it is better to separate two roles into two streams.
Other roles:
In most cases, using gen_server to create servers is the best solution, since this will greatly facilitate the structure of the system. This is also true for processing data transfer protocols.
All messages must have tags. Tagged messages are easier to manage, since their order in the receive block is not important, and it is easier to add support for new messages.
You should not write such code:
If it becomes necessary to add processing of the message {get_status_info, From, Option} and place it under the first block, a conflict will arise and the new code will never be executed.
If the messages are synchronous, the result must also be tagged, but different from the query. For example: when requested with the get_status_info tag, the status_info response should come. Compliance with this rule makes debugging much easier.
Here is an example of the correct code:
Each server in order to avoid a queue overflow should handle all messages coming to it, for example:
All servers must be implemented using tail recursion in order to avoid memory overflow.
Do not write like this:
Better this way:
Use functions to access the server instead of sending direct messages whenever possible.
The messaging protocol is internal information and should not be available to other modules.
Example:
Be extremely careful when using after when receiving messages. Make sure that you have foreseen the situation when the message comes after a timeout. (see clause 5.8).
As few threads as possible should set the trap_exit flag. But to use it or not, it still depends on the purpose of the module.
The data type record is a tagged tuple in the internal representation of Erlang. He first appeared in Erlang 4.3. Record is very similar to struct in C or record in Pascal.
If a record is planned to be used in several modules, then its definition should be placed in the header file.
Record is best used to ensure compatibility of modules when transferring data between them.
Use selectors and constructors to control the record . Never use a record as a cortege.
Example:
You should not use a record like this:
Do not write like this:
With this solution, {Key, Value} cannot contain false as a value. Here is the correct code:
Do not use catch and throw in case you are not sure what you are doing.
Catch and throw can be useful when processing external input data, or data that require complex processing (for example, text processing by the compiler).
Do not use get and put in case you are not sure what you are doing.
Functions that use put and get can be simply rewritten by adding another argument.
Do not write like this:
Better to rewrite:
Using put and get makes the function non deterministic. In this case, debugging is significantly complicated, since the result of the function depends not only on the input data but also on the process dictionary. Moreover, Erlang in error (for example, bad_match ) displays in the description only the arguments of function calls, and not the state of the stream dictionary at that time.
The import code is harder to read. It is better that all the definitions of the module functions were in one file.
It is necessary to distinguish between why the functions are exported:
Group -export and comment on the reason for export.
A strongly nested code is a code in which many case / if / receive blocks are nested in other case / if / receive blocks. It is considered a bad form to have more than two levels of nesting. Such code is hard to read. It is better to break such code into small functions.
A module should not contain more than 400 lines of code. It is better to break such modules into several small ones.
The function should not be longer than 15-20 lines. Do not try to solve the problem by writing just one line.
The number of characters in a line must be no more than 80 (to fit on A4).
In Erlang, lines declared after the transfer are automatically glued together.
For example:
Choosing the right (meaningful) name for a variable is quite a difficult task.
If the variable name consists of several words, it is better to separate them either via '_' or use CamelCase
Do not use '_' to ignore a variable in a function; rather, write a variable name starting with '_' , for example _Name .
The name of the function should clearly reflect its purpose. The result of the execution should be predictable from the name. Standard names should be used for standard functions (such as start , stop , init , main_loop ...).
Functions from different modules, but with the same purpose should be called the same (for example, Module: module_info () ).
The wrong choice of the function name is the most common mistake.
Some conventions for function names make this choice much easier. For example, the prefix 'is_' says that the result of the execution will be true or false .
In Erlang, a flat model for naming modules, i.e. There are no packages, for example, in Java (but, to be precise, they are, but their use in practice brings more problems than benefits).
Usually, the same prefixes are used to indicate that the modules are somehow connected. For example, ISDN is implemented like this:
isdn_init
isdn_partb
isdn_ ...
Uniform style allows developers to more easily understand each other’s code.
All people are used to writing code in different ways.
For example, someone defines the elements of a tuple with a space
someone without
Once you have developed a uniform style for yourself - stick to it.
You must always correctly set the attributes of the module in the header. Describe where the idea of this module came from, if the code appeared as a result of working on another module, describe it.
Never steal code. Theft is copying the code without specifying the source.
Attribute examples:
If the code implements a standard, be sure to leave a link to the documentation (for example, RFC).
All errors should be clearly described in a separate document.
In the code in places where logical is possible, call error_logger :
And make sure that {Descriptor, Arg1, Arg2, ....} are described in the “Error Description” document.
Use tagged tuples as messages forwarded by streams.
Using record in messages ensures compatibility between different modules.
Document all these data types in the Message Description document.
Comments should not be wordy, but should be sufficient to understand your code. Always keep them up to date.
Comments regarding modules should be indented and begin with %%% .
Comments regarding functions must be without indents and begin with %% .
Comments to the code must be aligned as well as it, and begin with % . Such comments should be above the code or in line with it. On one line more preferably (if placed).
It is important to document:
Example:
Record must be defined along with the description. For example:
Each file must begin copyright information. For example:
Each file should have a version history, which shows who made what changes and for what purpose.
Each file should begin with a short description of the purpose of the module and a list of exported functions.
If you know of any problems with using the code or something is not complete, describe them here. This will help further support your code.
Delete the old code and leave the description in the version control system. CSV will help you.
All more or less complex projects should use version control (Git, SVN, etc.)
Writing functions on a few pages of
writing functions with a set of nested a case / the if / the receive
Writing untagged functions
Function names do not match and the functional purpose of
bad variable names,
the use of flow when it is not necessary
Wrong choice of data structures (bad idea)
Poor comment or not comment
code no indenting
use put / get
bad message queue control
This section describes the documentation that is necessary for the project for support and administration.
One chapter per module. It should contain a description of each module and a description of all the functions it exports:
Description of messages used in the system, except those used only inside modules
Description of all registered streams and interfaces to them.
Description of all dynamically created threads and interfaces to them.
Description of all possible system errors.
1. Goals
This article lists some aspects that should be considered when developing software using Erlang.
2. Structure and terminology of Erlang
All Erlang subsystems are divided into modules. modules in turn consist of functions and attributes.
Functions can be either internal or exported for use in third-party modules.
Attributes start with a '-' and are placed at the beginning of the module.
All work in the Erlang architecture is carried out by threads. A thread in turn is a set of instructions that can use the function calls of various modules. Streams can communicate with each other by sending messages. Also, upon receipt, they can determine which messages need to be processed first. The rest of the messages remain in the queue until
there will be no need.
')
Streams can follow each other's work through binding ( link command). When a thread finishes its execution or a signal is automatically dropped, a signal is sent to all associated threads.
The default response to this signal for a thread is to immediately stop the operation.
But this behavior can be changed by setting the trap_exit flag, in which the signals are converted to messages and can be processed by the program.
Pure functions are functions whose value depends only on the input data and does not depend on the context of the call. With this behavior, they are similar to ordinary mathematics. Those who are not clean are said to be functions with side effects.
A side effect usually occurs if the function:
- Sends messages
- Receives messages
- Causes exit
- calls a BIF that changes the flow environment (such as get / 1 , put / 2 , erase / 1 , process_flag / 2 )
3 Design Principles
3.1 Export as few functions as possible from the module.
Modules are the basic structural unit in Erlang. They may contain a huge number of functions, but only those included in the export list will be available to third-party modules.
The complexity of the module depends on the number of exported functions. Agree, because it is easier to deal with the module that exports a couple of functions than the one that exports a dozen.
After all, the user needs to understand only those that are exported.
In addition, the one who accompanies the module code can be without fear of changing the internal functions, because the interface to the module remains unchanged.
3.2 Try to reduce dependencies between modules.
A module that appeals to many others is much more difficult to maintain, because if changes
interface, it is necessary to change the code wherever this module was used.
Remember, ideally, module calls should be a tree and not a graph with cycles. (from myself. For this, the Wrangler refactoring tool has a convenient mechanism based on GraphViz that can draw a function call graph)
As a result, the call code should be represented like this:
But not:
3.3 Place only frequently used code in libraries.
In the library (module) there should be a set of related functions only.
The task of the developer is to create libraries that contain functions of the same type.
Thus, for example, the lists library, which contains the code for working with lists, is an example of good architecture, and lists_and_method , which contains both the code for working with lists and mathematical algorithms, is bad.
Best of all, when all the functions in the library do not contain side effects. Then it can be easily reused.
3.4 Isolate the "hacks" and "dirty code" in separate modules
Often the solution to a problem requires the sharing of clean and dirty code.
Separate such areas into different modules.
For example, "dirty code":
- uses process vocabulary
- uses erlang: process_info / 1 for not quite adequate goals :)
- doing something that you didn’t originally intended to do, but you had to
Try to write as much clean code as possible, and “dirty”, firstly use as little as possible, and secondly, document all possible side effects and usage problems.
3.5 Do not think about how the calling function will use the result.
Do not think about how the calling function will use the result of your execution.
For example, suppose you call the route function, passing arguments to it that may not be correct. The creator of the route function should not think about what we will do when the arguments are not correct.
No need to write code like this:
do_something(Args) -> case check_args(Args) of ok -> {ok, do_it(Args)}; {error, What} -> String = format_the_error(What), io:format("* error:~s\n", [String]), %% Don't do this error end. Better to do this:
do_something(Args) -> case check_args(Args) of ok -> {ok, do_it(Args)}; {error, What} -> {error, What} end. error_report({error, What}) -> format_the_error(What). In the first case, the error is always output to the console, in the second, the error description is simply returned. The application developer can decide for himself what to do with it - ignore or lead to the printed form using error_report / 1 . In any case, he has the right to choose what to do when an error occurs.
3.6 Select common patterns and behaviors from code logic
If some code in the code begins to repeat itself, try to separate it into a separate function or module. So it will be much easier to maintain it than multiple copies scattered around the program.
Do not use "Copy & Paste", use functions!
3.7 Design from the top down
Develop a program from top to bottom. This will allow you to gradually detail the code until you reach the primitive functions. The code written in this way does not depend on the presentation of the data, since the representation is not yet known when you are developing at a higher level.
3.8 No need to optimize code
Do not optimize the code at the initial stage of development. First make it work properly, and only then, if the need arises, engage in optimization.
3.9 Write predictable code
The result of the functions should not be a surprise to the user. Functions that perform similar actions should look the same, or at least be similar. The user must be able to predict what the function may return. If the result of the execution does not meet expectations, then either the name of the function does not match its purpose, or the function code itself does not work correctly.
3.10 Try to avoid side effects.
Erlang has several primitives with side effects. Functions that use them are not easy to reuse, because they depend on the environment and the programmer needs to monitor the state of the stream before the call.
Write as much code as possible without side effects.
Clearly document all possible problems when using non-pure functions. This greatly facilitates the writing of tests and support.
3.11 Do not allow internal data to leave the module
The easiest way to demonstrate an example. Suppose there is a queue management function:
-module(queue). -export([add/2, fetch/1]). add(Item, Q) -> lists:append(Q, [Item]). fetch([H|T]) -> {ok, H, T}; fetch([]) -> empty. She describes the queue as a list. And used like this:
NewQ = [], % Queue1 = queue:add(joe, NewQ), Queue2 = queue:add(mike, Queue1), .... Several problems follow from this:
- need to know that the queue is a list
- in the future we will not be able to change the presentation to another (when, for example, optimization is needed)
Much better to write like this:
-module(queue). -export([new/0, add/2, fetch/1]). new() -> []. add(Item, Q) -> lists:append(Q, [Item]). fetch([H|T]) -> {ok, H, T}; fetch([]) -> empty. Now use will look like this:
NewQ = queue:new(), Queue1 = queue:add(joe, NewQ), Queue2 = queue:add(mike, Queue1), … This code is devoid of the disadvantages described above.
Now suppose you need to know the length of the queue. If the user knows that the queue is a list he will write:
Len = length(Queue) % Again, problems, since the user again tightly links the implementation with the view, such code is hard to maintain and read. For this case, it is better to provide a separate function and add to the module:
-module(queue). -export([new/0, add/2, fetch/1, len/1]). new() -> []. add(Item, Q) -> lists:append(Q, [Item]). fetch([H|T]) -> {ok, H, T}; fetch([]) -> empty. len(Q) -> length(Q). Now the user will be able to call his queue: len (Queue) instead of his code.
In this code, we "abstracted" from the details of the implementation of the data type queue. Those. in other words, the queue is now “abstract data type”.
Why all this trouble? In practice, it turned out to be an easy mechanism for replacing the internal representation, and now you can change the implementation of your module without fear of breaking backward compatibility with the user code. For example, for better implementation, the code is rewritten as
-module(queue). -export([new/0, add/2, fetch/1, len/1]). new() -> {[],[]}. add(Item, {X,Y}) -> % {[Item|X], Y}. fetch({X, [H|T]}) -> {ok, H, {X,T}}; fetch({[], []) -> empty; fetch({X, []) -> % fetch({[],lists:reverse(X)}). len({X,Y}) -> length(X) + length(Y). 3.12 Make the code deterministic as much as possible.
Deterministic programs always behave in the same way regardless of how many times they are run. Non-deterministic can behave differently with each launch. The first option is much easier to debug and allows you to track down and avoid many mistakes, so try to stick with it.
For example, the program should launch 5 different threads, and then check that they started, and the launch order is not important.
You can start all 5 at once, and then check, but it is better to run them in turn, each time checking whether the stream started and only after that start the next one.
3.13 Do not constantly check the correctness of the input data
Often, programmers do not trust the input data for the part of the system they are developing. Most of the code should not care about the correctness of the data transmitted to it. Verification should occur only when data is transmitted from outside.
For example:
%% Args: Option is all|normal get_server_usage_info(Option, AsciiPid) -> Pid = list_to_pid(AsciiPid), case Option of all -> get_all_info(Pid); normal -> get_normal_info(Pid) end. The function will terminate with an error if Option is not normall or all . So it should be! Whoever calls this function must control what is passed to it.
3.14 Isolate the hardware logic in the driver
Equipment must be isolated from the system using a driver. The task of the driver is to present the hardware in the system as if it were just an Erlang stream, which, like a simple stream, receives and sends messages and responds to errors.
3.15 Cancel actions in the same function as you do.
Suppose there is a code that opens a file, does something from it and then closes it.
do_something_with(File) -> case file:open(File, read) of, {ok, Stream} -> doit(Stream), file:close(Stream) % Error -> Error end. Please note that opening and closing a file occurs in the same function. The code is easy to read and understand. But, for example, such code is harder to understand and it is not immediately clear when the file is closed:
do_something_with(File) -> case file:open(File, read) of, {ok, Stream} -> doit(Stream) Error -> Error end. doit(Stream) -> ...., func234(...,Stream,...). ... func234(..., Stream, ...) -> ..., file:close(Stream) %% 4 Error Handling
4.1 Separate processing from normal code
Do not mix the normal code with the error handling code. You must program the normal behavior. If something goes wrong, the process should immediately terminate with an error. Do not try to correct the error and continue. Error handling must take another process.
4.2 Highlight the “core of errors”
One of the development stages is to determine which part of the system should always function without errors, and which part is allowed.
For example, in operating systems, the kernel should function without errors, while normal applications may fail with an error, but this will not affect the functioning of the system as a whole.
The part that should always work correctly we call the “core of errors”. This part, as a rule, constantly stores its intermediate state in the database or on disk.
5 Threads, servers and messages
5.1 Implement all code flow in one module
Of course, it should be understood that the thread calls functions from other modules, but here we are talking about the fact that the main loop of the thread should be in one module, and not split into several. Otherwise, it will be hard to control the progress. It also does not mean that you should not use generic libraries. They are just meant to help organize the flow.
Also, do not forget that the code common to several threads must be implemented in a completely separate module.
5.2 Use streams to build a system
Flows are the basic structural elements of a system. But do not use them and sending a message when it is possible to simply call a function.
5.3 Logged streams
Threads must be registered under the same name as the name of the module that contains their code. This will greatly facilitate support. Register only those streams that you plan to use for a long time.
5.4 Create only one thread in the system for each physically parallel action.
Using threads or solving a problem consistently depends directly on the problem we are trying to solve. But it is desirable to be guided by one main rule:
"Use one thread for every parallel process in the real world."
If you follow this rule, the logic of the program will be easy to understand.
5.5 Each stream should have only one “role”
Threads can perform different roles in the system. For example, in a client-server architecture, a stream can be both a client and a server, but it is better to separate two roles into two streams.
Other roles:
- Supervisor ( supervisor ) - monitors the flow and restarts them after the fall;
- worker ( worker ) - the usual executive flow, in which errors may occur;
- A trusted stream (or system worker , trusted worker ) is a stream in which no errors should occur.
5.6 Use generic functions to build servers and work with protocols whenever possible.
In most cases, using gen_server to create servers is the best solution, since this will greatly facilitate the structure of the system. This is also true for processing data transfer protocols.
5.7 Add tags to messages
All messages must have tags. Tagged messages are easier to manage, since their order in the receive block is not important, and it is easier to add support for new messages.
You should not write such code:
loop(State) -> receive ... {Mod, Funcs, Args} -> % apply(Mod, Funcs, Args}, loop(State); ... end. If it becomes necessary to add processing of the message {get_status_info, From, Option} and place it under the first block, a conflict will arise and the new code will never be executed.
If the messages are synchronous, the result must also be tagged, but different from the query. For example: when requested with the get_status_info tag, the status_info response should come. Compliance with this rule makes debugging much easier.
Here is an example of the correct code:
loop(State) -> receive ... {execute, Mod, Funcs, Args} -> % apply(Mod, Funcs, Args}, loop(State); {get_status_info, From, Option} -> From ! {status_info, get_status_info(Option, State)}, % loop(State); ... end. 5.8 Clear the queue of messages unknown to your code.
Each server in order to avoid a queue overflow should handle all messages coming to it, for example:
main_loop() -> receive {msg1, Msg1} -> ..., main_loop(); {msg2, Msg2} -> ..., main_loop(); Other -> % error_logger:error_msg( "Error: Process ~w got unknown msg ~w~n.",[self(), Other]), main_loop() end. 5.9 Use tail recursion when writing servers
All servers must be implemented using tail recursion in order to avoid memory overflow.
Do not write like this:
loop() -> receive {msg1, Msg1} -> ..., loop(); stop -> true; Other -> error_logger:log({error, {process_got_other, self(), Other}}), loop() end, io:format("Server going down"). % % ! Better this way:
loop() -> receive {msg1, Msg1} -> ..., loop(); stop -> io:format("Server going down"); Other -> error_logger:log({error, {process_got_other, self(), Other}}), loop() end. % 5.10 Create an interface to access your server
Use functions to access the server instead of sending direct messages whenever possible.
The messaging protocol is internal information and should not be available to other modules.
Example:
-module(fileserver). -export([start/0, stop/0, open_file/1, ...]). open_file(FileName) -> fileserver ! {open_file_request, FileName}, receive {open_file_response, Result} -> Result end. ...<code>... 5.11 Timeouts
Be extremely careful when using after when receiving messages. Make sure that you have foreseen the situation when the message comes after a timeout. (see clause 5.8).
5.12 Interception of the output signal
As few threads as possible should set the trap_exit flag. But to use it or not, it still depends on the purpose of the module.
6 Recommendations for Erlang code
6.1 Use record to store structures
The data type record is a tagged tuple in the internal representation of Erlang. He first appeared in Erlang 4.3. Record is very similar to struct in C or record in Pascal.
If a record is planned to be used in several modules, then its definition should be placed in the header file.
Record is best used to ensure compatibility of modules when transferring data between them.
6.2 Use selectors and constructors
Use selectors and constructors to control the record . Never use a record as a cortege.
Example:
demo() -> P = #person{name = "Joe", age = 29}, #person{name = Name1} = P,% matching ... Name2 = P#person.name. % You should not use a record like this:
demo() -> P = #person{name = "Joe", age = 29}, {person, Name, _Age, _Phone, _Misc} = P. % 6.3 Return the tagged result of the function
Do not write like this:
keysearch(Key, [{Key, Value}|_Tail]) -> Value; %% ! keysearch(Key, [{_WrongKey, _WrongValue} | Tail]) -> keysearch(Key, Tail); keysearch(Key, []) -> false. With this solution, {Key, Value} cannot contain false as a value. Here is the correct code:
keysearch(Key, [{Key, Value}|_Tail]) -> {value, Value}; %% . keysearch(Key, [{_WrongKey, _WrongValue} | Tail]) -> keysearch(Key, Tail); keysearch(Key, []) -> false. 6.4 Use with care catch and throw
Do not use catch and throw in case you are not sure what you are doing.
Catch and throw can be useful when processing external input data, or data that require complex processing (for example, text processing by the compiler).
6.5 Use process vocabulary with utmost care
Do not use get and put in case you are not sure what you are doing.
Functions that use put and get can be simply rewritten by adding another argument.
Do not write like this:
tokenize([H|T]) -> ...; tokenize([]) -> case get_characters_from_device(get(device)) of % get/1! eof -> []; {value, Chars} -> tokenize(Chars) end. Better to rewrite:
tokenize(_Device, [H|T]) -> ...; tokenize(Device, []) -> case get_characters_from_device(Device) of % eof -> []; {value, Chars} -> tokenize(Device, Chars) end. Using put and get makes the function non deterministic. In this case, debugging is significantly complicated, since the result of the function depends not only on the input data but also on the process dictionary. Moreover, Erlang in error (for example, bad_match ) displays in the description only the arguments of function calls, and not the state of the stream dictionary at that time.
6.6 Do not use import
The import code is harder to read. It is better that all the definitions of the module functions were in one file.
6.7 Exporting Functions
It is necessary to distinguish between why the functions are exported:
- To allow external access to them
- To provide an interface to the user
- For calls via spawn or apply from within the module itself.
Group -export and comment on the reason for export.
%% -export([help/0, start/0, stop/0, info/1]). %% -export([make_pid/1, make_pid/3]). -export([process_abbrevs/0, print_info/5]). %% -export([init/1, info_log_impl/1]). 7. Recommendations for stylistic and lexical code design.
7.1 Do not write heavily embedded code
A strongly nested code is a code in which many case / if / receive blocks are nested in other case / if / receive blocks. It is considered a bad form to have more than two levels of nesting. Such code is hard to read. It is better to break such code into small functions.
7.2 Do not write too large modules
A module should not contain more than 400 lines of code. It is better to break such modules into several small ones.
7.3 Do not write functions that are too long
The function should not be longer than 15-20 lines. Do not try to solve the problem by writing just one line.
7.4 Do not write a lot of characters in one line
The number of characters in a line must be no more than 80 (to fit on A4).
In Erlang, lines declared after the transfer are automatically glued together.
For example:
io:format("Name: ~s, Age: ~w, Phone: ~w ~n" "Dictionary: ~w.~n", [Name, Age, Phone, Dict]) 7.5 Variable naming
Choosing the right (meaningful) name for a variable is quite a difficult task.
If the variable name consists of several words, it is better to separate them either via '_' or use CamelCase
Do not use '_' to ignore a variable in a function; rather, write a variable name starting with '_' , for example _Name .
7.6 Naming Functions
The name of the function should clearly reflect its purpose. The result of the execution should be predictable from the name. Standard names should be used for standard functions (such as start , stop , init , main_loop ...).
Functions from different modules, but with the same purpose should be called the same (for example, Module: module_info () ).
The wrong choice of the function name is the most common mistake.
Some conventions for function names make this choice much easier. For example, the prefix 'is_' says that the result of the execution will be true or false .
is_...() -> true | false check_...() -> {ok, ...} | {error, ...} 7.7 Naming Modules
In Erlang, a flat model for naming modules, i.e. There are no packages, for example, in Java (but, to be precise, they are, but their use in practice brings more problems than benefits).
Usually, the same prefixes are used to indicate that the modules are somehow connected. For example, ISDN is implemented like this:
isdn_init
isdn_partb
isdn_ ...
7.8 Format the code uniformly.
Uniform style allows developers to more easily understand each other’s code.
All people are used to writing code in different ways.
For example, someone defines the elements of a tuple with a space
{12, 23, 45} someone without
{12,23,45} Once you have developed a uniform style for yourself - stick to it.
8 Documenting the code
8.1 Code Attributes
You must always correctly set the attributes of the module in the header. Describe where the idea of this module came from, if the code appeared as a result of working on another module, describe it.
Never steal code. Theft is copying the code without specifying the source.
Attribute examples:
-revision ('Revision: 1.14').
-created ('Date: 1995/01/01 11:21:11').
-created_by ('eklas @ erlang').
-modified ('Date: 1995/01/05 13:04:07').
-modified_by ('mbj @ erlang').
8.2 Leave reference to specification
If the code implements a standard, be sure to leave a link to the documentation (for example, RFC).
8.3 Document all errors
All errors should be clearly described in a separate document.
In the code in places where logical is possible, call error_logger :
error_logger : error_msg ( Format , { Descriptor , Arg1 , Arg2 , ....})
And make sure that {Descriptor, Arg1, Arg2, ....} are described in the “Error Description” document.
8.4 Document all types of data that is transmitted in messages.
Use tagged tuples as messages forwarded by streams.
Using record in messages ensures compatibility between different modules.
Document all these data types in the Message Description document.
8.5 Comment code
Comments should not be wordy, but should be sufficient to understand your code. Always keep them up to date.
Comments regarding modules should be indented and begin with %%% .
Comments regarding functions must be without indents and begin with %% .
Comments to the code must be aligned as well as it, and begin with % . Such comments should be above the code or in line with it. On one line more preferably (if placed).
Comment about function %%
some_useful_functions ( UsefulArgugument ) ->
another_functions ( UsefulArgugument ), % Comment at end of line
% Comment complicated_stmnt at about the same level of indentation
complicated_stmnt,
...
8.6 Comment each function
It is important to document:
- the purpose of this function
- valid input area
- output area
- If the function implements an algorithm, describe it.
- Possible failures of this function, presence of calls exit / 1 and throw / 1 , possible errors.
- Side effects
Example:
%% ------------------------------------------------ ----------------------
%% Function: get_server_statistics / 2
%% Purpose: Get various information from a process.
%% Args: Option is normal | all.
%% Returns: A list of {Key, Value}
%% or {error, Reason} (if the process is dead)
%% --------------------- -------------------------------------------------
get_server_statistics ( Option , Pid ) when pid ( Pid ) ->
...
8.7 Data Structures
Record must be defined along with the description. For example:
%% File: my_data_structures.h
%% ----------------------------------------- ----------------------------
%% Data Type: person
%% where:
%% name: A string (default is undefined).
%% age: An integer (default is undefined).
%% phone: A list of integers (default is []).
%% dict: A dictionary containing information information about the person.
%% A {Key, Value} list (default is the empty list).
%% ------------------------------------------------ ----------------------
- record ( person , {name, age, phone = [], dict = []}).
8.8 File Header, Copyright
Each file must begin copyright information. For example:
%%% ----------------------------------------------- ----------------------
%%% Copyright Ericsson Telecom AB 1996
%%%
%%% All rights reserved. This is a computer
program that allows you to reproduce, computerized
, electronic, mechanical, photocopying,
%%% recording, or computer programs. otherwise written permission of
Ericsson Telecom AB.
%%% ----------------------------------------------- ----------------------
8.9 File Header Version History
Each file should have a version history, which shows who made what changes and for what purpose.
%%%---------------------------------------------------------------------
%%% Revision History
%%%---------------------------------------------------------------------
%%% Rev PA1 Date 960230 Author Fred Bloggs (ETXXXXX)
%%% Intitial pre release. Functions for adding and deleting foobars
%%% are incomplete
%%%---------------------------------------------------------------------
%%% Rev A Date 960230 Author Johanna Johansson (ETXYYY)
%%% Added functions for adding and deleting foobars and changed
%%% data structures of foobars to allow for the needs of the Baz
%%% signalling system
%%%---------------------------------------------------------------------
8.10 ,
Each file should begin with a short description of the purpose of the module and a list of exported functions.
%%%---------------------------------------------------------------------
%%% Description module foobar_data_manipulation
%%%---------------------------------------------------------------------
%%% Foobars are the basic elements in the Baz signalling system. The
%%% functions below are for manipulating that data of foobars and for
%%% etc etc etc
%%%---------------------------------------------------------------------
%%% Exports
%%%---------------------------------------------------------------------
%%% create_foobar(Parent, Type)
%%% returns a new foobar object
%%% etc etc etc
%%%---------------------------------------------------------------------
If you know of any problems with using the code or something is not complete, describe them here. This will help further support your code.
8.11 Do not comment on the old code - delete it
Delete the old code and leave the description in the version control system. CSV will help you.
8.12 Use version control systems.
All more or less complex projects should use version control (Git, SVN, etc.)
9 Frequent errors
Writing functions on a few pages of
writing functions with a set of nested a case / the if / the receive
Writing untagged functions
Function names do not match and the functional purpose of
bad variable names,
the use of flow when it is not necessary
Wrong choice of data structures (bad idea)
Poor comment or not comment
code no indenting
use put / get
bad message queue control
10 Documentation
This section describes the documentation that is necessary for the project for support and administration.
10.1 Module Description
One chapter per module. It should contain a description of each module and a description of all the functions it exports:
- purpose
- input description
- output description
- possible use problems and exit / 1 calls .
10.2 Message Description
Description of messages used in the system, except those used only inside modules
10.3 Description of flows
Description of all registered streams and interfaces to them.
Description of all dynamically created threads and interfaces to them.
10.4 Description of errors
Description of all possible system errors.
Source: https://habr.com/ru/post/142594/
All Articles