Cluster? Easy!
So, we have 4 HP servers, of which 3 servers will be merged into a cluster, and one will be the management console. Linux SLES 10 SP2 and openMPI will be deployed on all servers, and SSH password-free access between the console and servers will also be organized.
Let's start:
Installing Linux with minimal system settings, the necessary packages can be delivered later. Note that the architecture of the components of all the nodes in the cluster must be identical.
We load the openMPI package on the cluster nodes, build and install them.
./configure
make
make install
')
After installing openMPI, the next step in our work will be to compile the program for calculating the number Pi on each node of the cluster. To do this, we need the libopencdk package, which is present in YAST, and the source code of the program for calculating the number Pi ( flops.f ). After the package is installed, and the program is placed in the directory that will be the same on all nodes of the cluster and the management node (console), we proceed to compile the program:
mpif77 flops.f -o flops
Installing passwordless ssh access, everything is simple:
1) Go to the cluster console and generate the rsa-key with the command:
ssh-keygen -t rsa
2) Copy the public console key (root / .ssh / id_rsa.pub) to all nodes of the cluster, in my case:
scp /root/.ssh/id_rsa.pub server1: /root/.ssh
3) On each cluster node we create an access file:
cat id_rsa.pub >> authorized_keys
Passwordless access is ready.
The next step is to create a file with a list of nodes of all our clusters, let's call it openmpi.host and put it in the folder with our test program for calculating the number Pi. Nodes in the file can be specified, either by name or simply by address. For example:
192.168.0.1
192.168.0.2
192.168.0.3
Servv1
Servv2
Servv3
So, the configuration of the console and cluster nodes is complete, go to the testing stage:
Run the program on 1 server, for this, on the control node, run the command:
mpirun -hostfile /var/mpi/openmpi.host -np 1 var / mpi / flops
Where:
–Np number of cluster nodes used in calculations.
Calculation time (s) - time to calculate operations.
Cluster speed (MFLOPS) - the number of floating point operations per second.
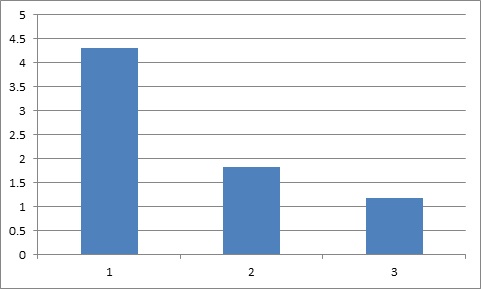
We get the following result:
Calculation time = 4.3
Cluster speed = 418 MFLOPS
Add another server to the cluster:
mpirun -hostfile /var/mpi/openmpi.host -np 2 var / mpi / flops
We get the following result:
Calculation time = 1.82
Cluster speed = 987 MFLOPS
Add the last 3 server to the cluster:
mpirun -hostfile /var/mpi/openmpi.host -np 3 var / mpi / flops
We get the following result:
Calculation time = 1.18
Cluster speed = 1530 MFLOPS
Calculation time of operations (seconds):
Number of floating point operations per second (MFLOPS):
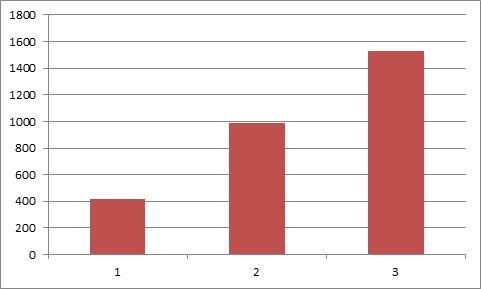
After analyzing the data, we can conclude that when a new node is added to the cluster, the performance of the entire system increases by (1 / N) * 100%.
I did not set myself the goal in this article to analyze the solutions to specific applied problems on cluster solutions. My goal was to show the efficiency of cluster systems. As well as an example to demonstrate the architecture of building a cluster element in the network structure.
UPD: Thanks for the constructive criticism of uMg and 80x86 , the corresponding changes were made to the article.
Source: https://habr.com/ru/post/142218/
All Articles