Another way to failover servers: ip sla and enhanced object tracking
 Sometimes, and most likely quite often, there is a need to ensure the fault tolerance of servers or even better than the applications running on these very servers.
Sometimes, and most likely quite often, there is a need to ensure the fault tolerance of servers or even better than the applications running on these very servers.There are many ways to do this:
- the service itself may initially be invented with the possibility of fault tolerance - it can be run on several servers and the client will find the worker from the list;
- you can bloat the cluster with the help of the operating system;
- you can come up with something with virtualization (the same cluster, only side view);
But unfortunately sometimes, and quite often in my personal practice, a situation arises that goes beyond these possibilities: there is no money, there is a network, a samopopnoe application is on my knee — you cannot assemble a cluster, the client part is able to go to only one server. And suddenly this application became critical, it is necessary to make 25x8x366. Under the cut one of the fairly innocuous ways.
')
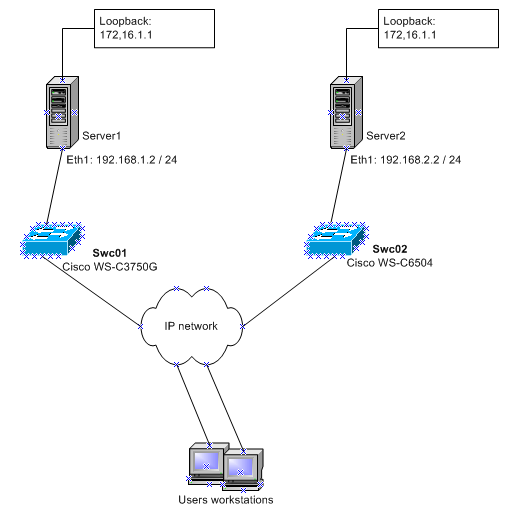
Suppose that we already have some kind of network with server switches, users, and all sorts of other delights. It would be nice if the server switches were two and in different buildings, and then a little light goes out? But this method can be reduced to one switch without much effort. So, see the picture above - two server switches-L3, some kind of ip-network between them, dynamic routing in the network (I will have eigrp, but this is not very important), somewhere in this network users live - almost all-encompassing happening. Critical service (let it be a web application available on port 80) runs on Server1 server included in switch swc01 (say, Cisco 3750G).
First of all, we extract the second Server2 server and enable it in the second switch of swc02 (let it be Cisco6504. Switches are different in order to show a slight difference in the syntax of the config, see below). Then we apply force to the developers, so that they install the application on the second server and think about synchronization, replication, and other tyrits. Here, in principle, and everything :) So users and let's say - if you climb on 192.68.1.2 (server1) and do not work, then try to climb on 192.168.2.2 (server2), and then we write a letter of resignation of PSG. So as not to suffer the search for a new job, try to do everything imperceptibly to users.
To begin, hang on the server through an additional loopback interface. And we will attach the same address 172.16.1.1/32 to both of these interfaces, which will henceforth be a single address to access the service. Then it would be possible to make the same dynamic routing server to report to the network that they are alive and there, but personally I do not like the dynamics on the servers. And let the network deal with network issues, otherwise programmers will set up routing - it’s a mess!
Further, swc01 tries to set the tcp session on port 80 to the address of the eth interface of server1 server and, if successful, sets up a static route to 172.16.1.1 via next-hop 192.168.1.2 (eth from server1 server) and reports this route to Sit down with dynamic routing protocol (eigrp).
And swc02 monitors availability (tries to establish a tcp-session) and server1 and server2 and if 1 fell, and 2 works, then it sets its static route to 172.16.1.1 through 192.168.2.2 (eth from server2) and also reports this to the network through the dynamics.
Like that. Now to the details:
swc01 config:
router eigrp 1 redisribute static ! rtr 1 type tcpConnect dest-ipaddr 192.168.1.2 dest-port 443 control disable timeout 500 ! rtr schedule 1 life forever start-time now ! track 1 rtr 1 ! ip route 172.16.1.1 255.255.255.255 192.168.1.2 track 1 !
swc02 config:
router eigrp 1 redisribute static ! ip sla monitor 1 type tcpConnect dest-ipaddr 192.168.1.2 dest-port 80 control disable timeout 500 ! ip sla monitor schedule 1 life forever start-time now ! ip sla monitor 2 type tcpConnect dest-ipaddr 192.168.2.2 dest-port 80 control disable timeout 500 ! ip sla monitor schedule 2 life forever start-time now ! track 1 boolean list and object 1 not object 2 ! ip route 172.16.1.1 255.255.255.255 192.168.2.2 track 1 !
// note the difference in ip-sample syntax. in the old ios-ahs (like before 12.2.20) it was necessary to write rtr, and in the new ip sla
The only trick is in track-2 on the second switch, which (! Obj1 && obj2).
Why exactly? Because in another way will not work.
You can go to the forehead and just hang two static routes on both switches. Then part of the network will go to one server, and part to another - sometimes this is good, as some balancing appears, but in most cases the developers want to know exactly and deterministically which server is currently working.
You can do just one ip-sla to the nearest server and the static with the tracking of this ip-sla-i, just on one of the switches the statics will be with greater distance:
ip route 172.16.1.1 255.255.255.255 192.168.2.2 200 track 1
Then, when the main server is turned off and on, two routes will appear in the network and we will arrive at a non-deterministic state.
You can try to track on the second switch not the availability of the server, but the presence in the routing table of the route to the loopback, and if it is, then do not set your route, and if not, then set:
track 1 ip route 172.16.1.1/32 reachability ip route 172.16.1.1 255.255.255.255 192.168.2.2 track 1
The problem is exactly the same. When the main server falls, the route will first disappear from the table, then its static will be established and everything will never disappear from there, even if the main server appears. And again there will be a non-deterministic state.
Source: https://habr.com/ru/post/141858/
All Articles