Cluster and “regular” MySQL indices (InnoDB)
We all remember the textbook explanation of “what are indexes in a database and how they facilitate the task of finding the necessary strings”. I'm sure most of you get something like this before your eyes:
And at once it becomes obvious how much less data you need to shovel to find two or three necessary lines. Brilliant. Simply. Clear.
')
And personally, I always thought that there was no place to improve this scheme ... Until I became acquainted with clustered indexes. It turned out that everything is not so rosy with the "usual" indices.
So, what is a cluster index, how is it better than a non-cluster index, and how does MySQL deal with it?
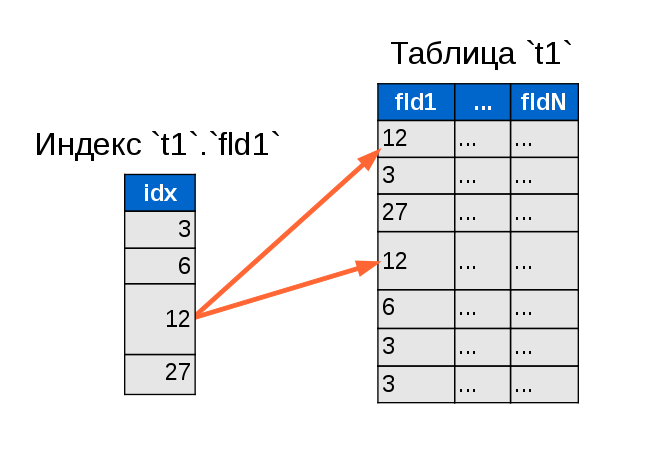
In order not to get confused, for the time being we will consider a simple index by one field. A simplified nonclustered index can be represented as a separate table, each row in which refers to one or more rows in the table with data. The rows in the index table are ordered and grouped by the values of the key fields. Imagine an elementary query:
Without any indexing, every line will be read and checked, and the unsatisfying lines will simply not fall into the result. But they will be read.
When using the “normal”, nonclustered index, the search task is greatly accelerated. First , the index table weighs a lot less than the table with data, which means it can easily be read faster. Secondly , DBMS most often try to cache indexes into RAM, which in itself is much quicker than a hard disk *. Third , there are no duplicate rows in the indexes. So, as soon as we find the first value, the search can be stopped - it is the last one. Fourth , the data in the index is sorted. And thirdly and fourthly, together they make it possible to use a binary search algorithm (also known as the method of dividing in half), the efficiency of which exceeds many times the simple search.
* If resources allow, the data table can also (and should) be cached into RAM. However, indices and the place for them in RAM, for obvious reasons, it is customary to pay more attention.
Indexing is a great power. But if we present all the indexes of the index table to the rows in the data table SIMULTANEOUSLY, we get a rather complicated “web”:

And this web, with a multitude of intersecting arrows, brings us to the problem (it just demonstrates it clearly) that the nonclustered index creates.
The MySQL optimizer may decide not to use indexes at all for searching small tables (up to a couple of dozen entries - depending on the specific data structure and index). Why? Because the search is brute-force reading data sequentially. A pointer in the index refers to disparate sections of data. And jumping on the links from the index may ultimately cost more than a complete search.
So, what we have at this stage in the evolution of indexing. Imagine a large, fragmented indexing table. As the data arrived in a chaotic and unsorted way, they were preserved. Now imagine an index table to it. And our good old request:
What's happening? The value is located in the index — this is quick and simple — and the lines referenced by this index are read from the data table. Naturally, with a large fragmentation of the table, the overhead of reading from different parts of it becomes tangible.
And here it will be useful to us ...
Cluster indexes differ from noncluster indexes in the same way as the book’s table of contents differs from the index. The alphabetical index (nonclustered index) for the exact word (value) gives the exact page numbers (rows in the database). A table of contents indicates the range of pages corresponding to a particular chapter, in which the search term is already found. Moreover, each chapter, if it is large enough, may contain its own table of contents.
A clustered index is a tree-like data structure, in which the index values are stored along with the data corresponding to them. Both indexes and data with such an organization are ordered. When a new row is added to the table, it is added not to the end of the file *, not to the end of the flat list, but to the desired branch of the tree structure corresponding to it by sorting.
* In different engines and with different settings it may not be the end at all, and not a file at all. The word file here means "a certain unit of measurement of data corresponding to one table", and "end of file" is used as a symbol of sequential, linear record.
One of the most powerful and productive engines for MySQL is InnoDB. There are many reasons for this, and one of them is cluster indices. The easiest way to understand is how clustered indexes are structured, if we present them in dynamics: how they grow as the data is added, and how the table begins to branch.
Data in InnoDB is stored in pages of 16 KB each. The size of one page is the limiting size of the node of our tree structure, on which depends at what point the branch will begin. If the entire table fits into one page, then it is stored as a flat list, sorted by key field, without a separate index table.
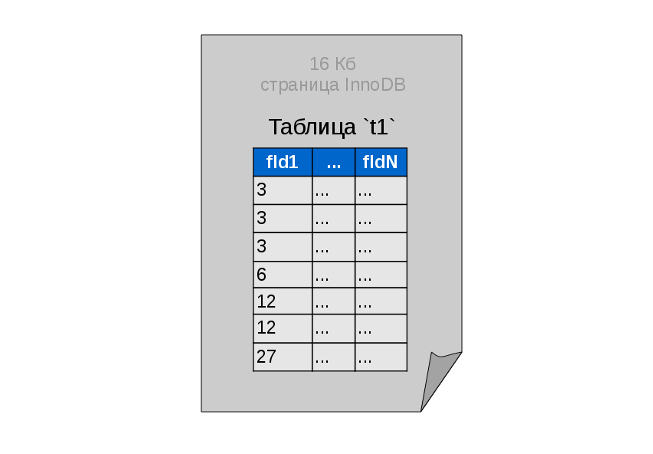
In the future, all our data will be presented with exactly the same small tablets, and the chains of index pages will combine them into a tree.
When the data ceases to fit into one page, the list turns into a tree. The data page is divided into two, and in that node (on that page), where the data used to be, there is now an index covering both new pages. A specific node of such a tree must include indices of all child nodes or final data, if the node is the last. Nodes can refer to each other only in one direction: from parent to child.
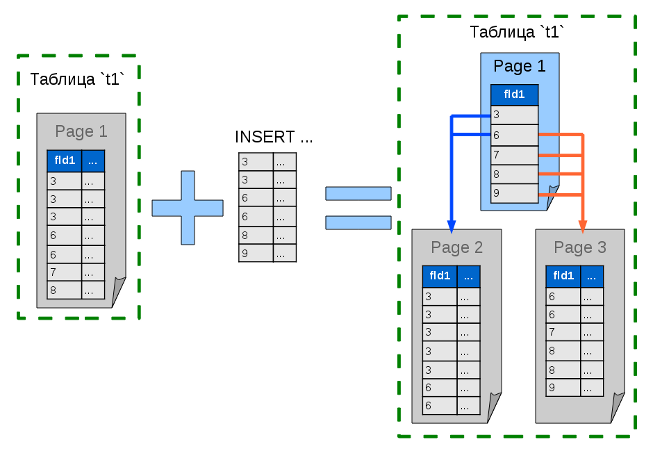
As you add more and more new data, the tree will become more complex and deeper. And the more it will be branching, the more you gain from such a data storage scheme.
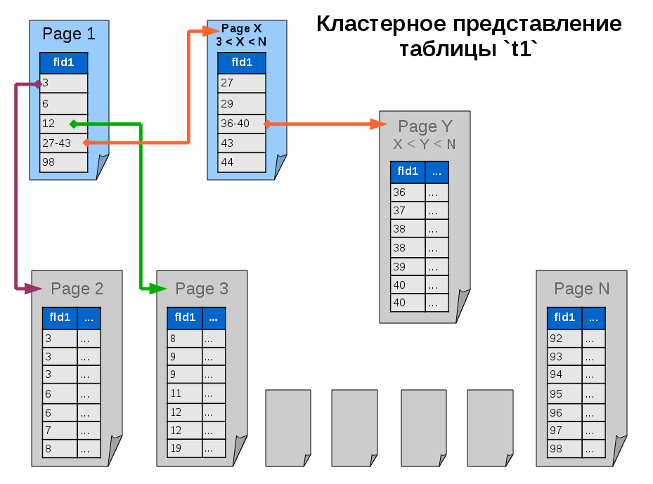
Gray pages are identical to the page of the first stage - it is just sorted data, leaves (end nodes) of our tree. Blue pages are intermediate nodes in the tree, containing only an index and not containing data. Arrows indicate the search paths for specific key values.
Recall our query (green arrow):
Turning to the table, the query goes to the first page and receives an index, which immediately sends it to the final page with data, where the rows that meet the search criteria are located. The page has already been read at the search stage, all data has been collected, the database can return a response.
However, an index pointing to another page does not necessarily lead directly to a page with data. The index may point to a page with an intermediate index. Perhaps, with large volumes of the table, the database will have to perform more search iterations, but each such iteration includes a minimum amount of data, and therefore, in general, the search is still faster.
There is a simple rule that applies to any type of index: the more diverse the data, the more efficient it is to use the index to search for specific values.
Since the data is part of the index, sorted and purposefully fragmented, it is obvious that only one cluster key can be used for one table. From such a rather complex logic of storing indexes and data, there is another important consequence: the write operations, and especially the change in the existing data of key fields, is an extremely resource-intensive process. Try to use rarely changeable fields for clustered indexes.
As for the complex (composite) cluster keys, the same scheme works for them, only the data is sorted by two fields. The index itself differs little from a nonclustered composite key.
Everything is simple here. Each InnoDB table has a cluster key. Each Without exception.
It is much more interesting which fields are selected for this.
Up to the third point, it is better not to bring your long-suffering server, and add the same ID yourself.
And do not forget that InnoDB in the secondary keys stores the full set of field values of the cluster key as a reference to the final row in the table. The larger the primary key, the greater the secondary keys.
And at once it becomes obvious how much less data you need to shovel to find two or three necessary lines. Brilliant. Simply. Clear.
')
And personally, I always thought that there was no place to improve this scheme ... Until I became acquainted with clustered indexes. It turned out that everything is not so rosy with the "usual" indices.
So, what is a cluster index, how is it better than a non-cluster index, and how does MySQL deal with it?
Noncluster indexes
In order not to get confused, for the time being we will consider a simple index by one field. A simplified nonclustered index can be represented as a separate table, each row in which refers to one or more rows in the table with data. The rows in the index table are ordered and grouped by the values of the key fields. Imagine an elementary query:
SELECT * FROM `t1` WHERE `fld1` = 12; Without any indexing, every line will be read and checked, and the unsatisfying lines will simply not fall into the result. But they will be read.
When using the “normal”, nonclustered index, the search task is greatly accelerated. First , the index table weighs a lot less than the table with data, which means it can easily be read faster. Secondly , DBMS most often try to cache indexes into RAM, which in itself is much quicker than a hard disk *. Third , there are no duplicate rows in the indexes. So, as soon as we find the first value, the search can be stopped - it is the last one. Fourth , the data in the index is sorted. And thirdly and fourthly, together they make it possible to use a binary search algorithm (also known as the method of dividing in half), the efficiency of which exceeds many times the simple search.
* If resources allow, the data table can also (and should) be cached into RAM. However, indices and the place for them in RAM, for obvious reasons, it is customary to pay more attention.
Indexing is a great power. But if we present all the indexes of the index table to the rows in the data table SIMULTANEOUSLY, we get a rather complicated “web”:
And this web, with a multitude of intersecting arrows, brings us to the problem (it just demonstrates it clearly) that the nonclustered index creates.
Fragmentation
The MySQL optimizer may decide not to use indexes at all for searching small tables (up to a couple of dozen entries - depending on the specific data structure and index). Why? Because the search is brute-force reading data sequentially. A pointer in the index refers to disparate sections of data. And jumping on the links from the index may ultimately cost more than a complete search.
So, what we have at this stage in the evolution of indexing. Imagine a large, fragmented indexing table. As the data arrived in a chaotic and unsorted way, they were preserved. Now imagine an index table to it. And our good old request:
SELECT * FROM `t1` WHERE `fld1` = 12; What's happening? The value is located in the index — this is quick and simple — and the lines referenced by this index are read from the data table. Naturally, with a large fragmentation of the table, the overhead of reading from different parts of it becomes tangible.
And here it will be useful to us ...
Cluster indices
Cluster indexes differ from noncluster indexes in the same way as the book’s table of contents differs from the index. The alphabetical index (nonclustered index) for the exact word (value) gives the exact page numbers (rows in the database). A table of contents indicates the range of pages corresponding to a particular chapter, in which the search term is already found. Moreover, each chapter, if it is large enough, may contain its own table of contents.
A clustered index is a tree-like data structure, in which the index values are stored along with the data corresponding to them. Both indexes and data with such an organization are ordered. When a new row is added to the table, it is added not to the end of the file *, not to the end of the flat list, but to the desired branch of the tree structure corresponding to it by sorting.
* In different engines and with different settings it may not be the end at all, and not a file at all. The word file here means "a certain unit of measurement of data corresponding to one table", and "end of file" is used as a symbol of sequential, linear record.
One of the most powerful and productive engines for MySQL is InnoDB. There are many reasons for this, and one of them is cluster indices. The easiest way to understand is how clustered indexes are structured, if we present them in dynamics: how they grow as the data is added, and how the table begins to branch.
First Stage: Flat List
Data in InnoDB is stored in pages of 16 KB each. The size of one page is the limiting size of the node of our tree structure, on which depends at what point the branch will begin. If the entire table fits into one page, then it is stored as a flat list, sorted by key field, without a separate index table.
In the future, all our data will be presented with exactly the same small tablets, and the chains of index pages will combine them into a tree.
Second stage: wood
When the data ceases to fit into one page, the list turns into a tree. The data page is divided into two, and in that node (on that page), where the data used to be, there is now an index covering both new pages. A specific node of such a tree must include indices of all child nodes or final data, if the node is the last. Nodes can refer to each other only in one direction: from parent to child.
As you add more and more new data, the tree will become more complex and deeper. And the more it will be branching, the more you gain from such a data storage scheme.
Gray pages are identical to the page of the first stage - it is just sorted data, leaves (end nodes) of our tree. Blue pages are intermediate nodes in the tree, containing only an index and not containing data. Arrows indicate the search paths for specific key values.
Recall our query (green arrow):
SELECT * FROM `t1` WHERE `fld1` = 12; Turning to the table, the query goes to the first page and receives an index, which immediately sends it to the final page with data, where the rows that meet the search criteria are located. The page has already been read at the search stage, all data has been collected, the database can return a response.
However, an index pointing to another page does not necessarily lead directly to a page with data. The index may point to a page with an intermediate index. Perhaps, with large volumes of the table, the database will have to perform more search iterations, but each such iteration includes a minimum amount of data, and therefore, in general, the search is still faster.
There is a simple rule that applies to any type of index: the more diverse the data, the more efficient it is to use the index to search for specific values.
Since the data is part of the index, sorted and purposefully fragmented, it is obvious that only one cluster key can be used for one table. From such a rather complex logic of storing indexes and data, there is another important consequence: the write operations, and especially the change in the existing data of key fields, is an extremely resource-intensive process. Try to use rarely changeable fields for clustered indexes.
As for the complex (composite) cluster keys, the same scheme works for them, only the data is sorted by two fields. The index itself differs little from a nonclustered composite key.
Cluster keys in InnoDB
Everything is simple here. Each InnoDB table has a cluster key. Each Without exception.
It is much more interesting which fields are selected for this.
- If the table is set PRIMARY KEY - this is it
- Otherwise, if the table contains UNIQUE (unique) indexes, this is the first one.
- Otherwise, InnoDB independently creates a hidden field with a surrogate ID of 6 bytes in size.
Up to the third point, it is better not to bring your long-suffering server, and add the same ID yourself.
And do not forget that InnoDB in the secondary keys stores the full set of field values of the cluster key as a reference to the final row in the table. The larger the primary key, the greater the secondary keys.
Source: https://habr.com/ru/post/141767/
All Articles