What It Worth Thinking About, Keeping Your Data in the Cloud. Part 2
In short, we are talking about the fact that, by saving data on several clouds, it is possible to significantly increase their availability and security. Under security means that the data will exist, even if one provider (or several) had a serious problem. Detailed motivation in the first part .
In this article I want to make out the theoretical part about the method by which it is better to create redundant data. And the practical part - what you can currently use. So that there is no disappointment, what I am writing about is relatively recent scientific developments, so the practical part will be rather poor. But I hope to attract the attention of those who would like to develop a program for such a task.
')
I want to make a digression right away. I consciously use the English term erasure codes in the article - I did not find this term in Russian. These are not corrective error codes in any way. If anyone knows and tells you - I will be grateful.
Fortunately, there is a different approach that allows you to save on both disk space and traffic, while not reducing data availability. This is erasure codes .
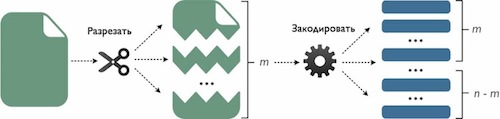
The essence of erasure codes is that after encoding a file, n fragments are obtained (in practical implementation, these are also files). Any m of these fragments are equal in size to the original file. Moreover, n> m . Each of the fragments is stored in a separate cloud storage. To restore the original file, just collect m of any fragments and decode it. The remaining nm fragments can be deleted, corrupted, cloud storage containing them are not available, etc. Thus, a system using erasure codes can cope with the appearance of n - m errors.
For those who want to dig deeper, I describe MDS erasure codes. There are other types of codes and they have slightly different properties. If there is interest, I can describe in detail with all the math.
The ratio of the parameters n and m can be selected. For example, you can set the parameters so that n = 2 * m , in which case the size of the encoded data will be exactly two times larger than the original. For example, let m = 5, n = 10 . Then the fragments after encoding get 10 pieces. The size of one fragment will be equal to the ratio of the file size to m . If you collect any 5 of these fragments and calculate the total size, it will be equal to the size of the original file. Each of the fragments is stored on one of the 10 cloud storages. At the same time, any 5 storages may be unavailable at one time, but this will not affect the availability of user data - the file can be restored.
In mathematical notation, it looks like this. Suppose the file size is L. Then the size of one fragment is p = L / m , the total size of the redundant data is 2 * L. The size of all fragments required for restoration is L = p * m .
Compare with replication. To have a system in which any 5 cloud storage can fail, you must have 6 cloud storage, each of which stores a copy of the file. In this case, the size of the data stored in the system will be 6 times the size of the file. While using erasure codes, you will need to save redundant data twice the size of the original file.
Thus, in a system that is able to survive the appearance of a certain number of errors, when using the erasure code:
The last point may outweigh the merits of the first two, and maybe not. It all depends on the specific situation. You can discuss this in comments if you are interested.
Well, that's obvious. If the amount of data that needs to be saved is less, then the amount of traffic spent on saving will be proportionally less. Plus in the direction of erasure codes. When recovering in any of the cases - whether replication is used or erasure codes, the size of the data that is to be transferred will be equal to the size of the original file, those L.
Obviously, replication does not require coding. How much does the use of codes slow down? There are a great many similar tests. On average, it took me less than 4 seconds to encode a 512 megabyte file (I repeated the test 1000 times). The configuration was the following - a computer with 3 gigabyte RAM, 3 GHz Intel Core 2 Duo processor. The operating system is 11.10 Ubuntu. As a codec, I used the famous Jerasure library, the current version of which is on github.
Erasure codes:
Actually, I began to delve into this topic because I want to save my data so that their security and accessibility are guaranteed not only by the statements of the providers. Accordingly, the easiest way to improve the current situation is to keep at least one more copy of the data, in addition to the copy stored on one of their cloud storages. Or another copy besides the local copy.
If you want to be confused. There are several young implementations of this approach that can be played with. More than playing, I would not become for two reasons. First - they are in fact still very young, and my data is an important thing for me. The second good reason is that all projects have a weak part of data security in terms of their confidentiality. I promised to write about this in the third part.
So far I present to your attention toys:
NCCloud uses the latest codes - regenerative codes. The main pretext for using these codes is to reduce traffic in the event that one or more clouds have errors and your data is unavailable and corrupted. At the same time, the ability to recover data from such codes falls (in comparison with those considered in this article, with the same level of availability). I totally disagree with this approach. The reason is simple. Such codes play an important role if the data is stored in a p2p network, where network nodes appear and then disappear. In the case of the use of clouds, the availability of each cloud is very high and errors, problems rarely occur. Accordingly, the data recovery process will rarely occur. Saving on traffic during this process, while worsening its effectiveness seems to me not reasonable.
NubiSave uses Cauchy Reed-Solomon code to create redundant data. Data coding occurs in stages, that is, at the moment when one data block is encoded, the previous one is already loaded on cloud storage. This reduces waiting time for the user. The positive aspect of their architecture is that you can flexibly customize the processing of data - whether they will be encrypted or compressed. A serious drawback is the implementation of encryption and confidentiality in general have not been thought out yet (I repeat, more on this in more detail in another part of the article).
By the way, some cloud providers already use erasure codes too. For example, a propual solution from Wuala.
In this article I want to make out the theoretical part about the method by which it is better to create redundant data. And the practical part - what you can currently use. So that there is no disappointment, what I am writing about is relatively recent scientific developments, so the practical part will be rather poor. But I hope to attract the attention of those who would like to develop a program for such a task.
')
I want to make a digression right away. I consciously use the English term erasure codes in the article - I did not find this term in Russian. These are not corrective error codes in any way. If anyone knows and tells you - I will be grateful.
Theory
Codes
Fortunately, there is a different approach that allows you to save on both disk space and traffic, while not reducing data availability. This is erasure codes .
The essence of erasure codes is that after encoding a file, n fragments are obtained (in practical implementation, these are also files). Any m of these fragments are equal in size to the original file. Moreover, n> m . Each of the fragments is stored in a separate cloud storage. To restore the original file, just collect m of any fragments and decode it. The remaining nm fragments can be deleted, corrupted, cloud storage containing them are not available, etc. Thus, a system using erasure codes can cope with the appearance of n - m errors.
For those who want to dig deeper, I describe MDS erasure codes. There are other types of codes and they have slightly different properties. If there is interest, I can describe in detail with all the math.
How is this approach better?
Size of redundant data
The ratio of the parameters n and m can be selected. For example, you can set the parameters so that n = 2 * m , in which case the size of the encoded data will be exactly two times larger than the original. For example, let m = 5, n = 10 . Then the fragments after encoding get 10 pieces. The size of one fragment will be equal to the ratio of the file size to m . If you collect any 5 of these fragments and calculate the total size, it will be equal to the size of the original file. Each of the fragments is stored on one of the 10 cloud storages. At the same time, any 5 storages may be unavailable at one time, but this will not affect the availability of user data - the file can be restored.
In mathematical notation, it looks like this. Suppose the file size is L. Then the size of one fragment is p = L / m , the total size of the redundant data is 2 * L. The size of all fragments required for restoration is L = p * m .
Compare with replication. To have a system in which any 5 cloud storage can fail, you must have 6 cloud storage, each of which stores a copy of the file. In this case, the size of the data stored in the system will be 6 times the size of the file. While using erasure codes, you will need to save redundant data twice the size of the original file.
Thus, in a system that is able to survive the appearance of a certain number of errors, when using the erasure code:
- on each of the server you need to store less data
- the total size of the data to be saved will be substantially less
- total number of cloud storage required more
The last point may outweigh the merits of the first two, and maybe not. It all depends on the specific situation. You can discuss this in comments if you are interested.
Traffic
Well, that's obvious. If the amount of data that needs to be saved is less, then the amount of traffic spent on saving will be proportionally less. Plus in the direction of erasure codes. When recovering in any of the cases - whether replication is used or erasure codes, the size of the data that is to be transferred will be equal to the size of the original file, those L.
Coding time
Obviously, replication does not require coding. How much does the use of codes slow down? There are a great many similar tests. On average, it took me less than 4 seconds to encode a 512 megabyte file (I repeated the test 1000 times). The configuration was the following - a computer with 3 gigabyte RAM, 3 GHz Intel Core 2 Duo processor. The operating system is 11.10 Ubuntu. As a codec, I used the famous Jerasure library, the current version of which is on github.
Total
Erasure codes:
- Allowed to save on disk space occupied by redundant data, both on a separate server, and on all combined
- For the same level of availability, more servers are required than when using replication
- Allowed to save on outgoing traffic when data is saved to the server (which occurs most often during backup)
- Spend user time coding data
- Nevertheless, the coding rate is quite high, especially in comparison with the speed of data transmission over the network.
Practice
Actually, I began to delve into this topic because I want to save my data so that their security and accessibility are guaranteed not only by the statements of the providers. Accordingly, the easiest way to improve the current situation is to keep at least one more copy of the data, in addition to the copy stored on one of their cloud storages. Or another copy besides the local copy.
If you want to be confused. There are several young implementations of this approach that can be played with. More than playing, I would not become for two reasons. First - they are in fact still very young, and my data is an important thing for me. The second good reason is that all projects have a weak part of data security in terms of their confidentiality. I promised to write about this in the third part.
So far I present to your attention toys:
NCCloud uses the latest codes - regenerative codes. The main pretext for using these codes is to reduce traffic in the event that one or more clouds have errors and your data is unavailable and corrupted. At the same time, the ability to recover data from such codes falls (in comparison with those considered in this article, with the same level of availability). I totally disagree with this approach. The reason is simple. Such codes play an important role if the data is stored in a p2p network, where network nodes appear and then disappear. In the case of the use of clouds, the availability of each cloud is very high and errors, problems rarely occur. Accordingly, the data recovery process will rarely occur. Saving on traffic during this process, while worsening its effectiveness seems to me not reasonable.
NubiSave uses Cauchy Reed-Solomon code to create redundant data. Data coding occurs in stages, that is, at the moment when one data block is encoded, the previous one is already loaded on cloud storage. This reduces waiting time for the user. The positive aspect of their architecture is that you can flexibly customize the processing of data - whether they will be encrypted or compressed. A serious drawback is the implementation of encryption and confidentiality in general have not been thought out yet (I repeat, more on this in more detail in another part of the article).
By the way, some cloud providers already use erasure codes too. For example, a propual solution from Wuala.
Source: https://habr.com/ru/post/141487/
All Articles