Amateur Game Translation: Anatomy of a Process, Part One
 Amateur localization is a phenomenon that has affected many gamers, and sometimes even played a significant role in shaping their interests and attitudes towards the gaming industry as a whole. Probably due to the fact that it has long pursued mainly good goals, the majority of fans of interactive entertainment at its mention appear mostly positive associations, and sometimes even nostalgic emotions.
Amateur localization is a phenomenon that has affected many gamers, and sometimes even played a significant role in shaping their interests and attitudes towards the gaming industry as a whole. Probably due to the fact that it has long pursued mainly good goals, the majority of fans of interactive entertainment at its mention appear mostly positive associations, and sometimes even nostalgic emotions.Last time I expounded my view on the phenomena of both amateur and official localization. Since there were people who were close or interested in this topic, and it wasn’t enough without anyone who would like to know more about the technical details of the process, I have no choice but to tell about it, albeit in a somewhat specific style.
The picture shows the logo of the Russian Romanshaking community according to the Russian Romhacking project.
Before reading
First of all, I want to say that I review only the experience that I had the opportunity to observe or practice personally. So far from being a fact that all unofficial localizers adhered to the techniques described below, and even more so for the mentioned toolkit. First of all, I will talk about the approach that I used myself. I believe that it is sufficiently indicative and benefits from many other methods practiced by other enthusiasts. However, the concept of the technique here is rather vague, and for many it is completely absent.
')
Just in case, I will mention that my actions, on which all the described experience is based, have never pursued mercenary goals and were not destructive in nature. All this was done, first of all, for the sake of the process and self-development, and it was just my hobby.
To be honest, I thought for a long time how to structure an article and what exactly to include in it - first I wanted to tell not only about the technical features of the process, but also to describe the essence of the social component. However, at some point I caught myself thinking that because of the abundance of criticism, the article is suitable for a somewhat different place than for Habr - the majority of non-professionals reproach the lack of professionalism and lack of desire to improve the techniques somewhat cynically.
As a result, I decided to describe only the technical part and only in general form - a detailed description with examples would be enough for a dozen of such articles, or even for another useless book, so for now let's put it on the back burner. Despite this, the article, even in its incomplete form, turned out to be quite large, and I decided to split it into several posts. How it came out interesting or useful - to judge you.
The technical side of the issue
If you make a small breakdown of the translation process into subtasks, you can get something like this:
- Reverse engineering is a process much better known by the term reverse engineering. The game is examined, analyzed formats, define algorithms, find the necessary data.
- Resource Extraction - converts the resources needed to translate into an easy-to-edit form. Text - in text files, graphics - in common image formats, etc. All this can be done either manually (inscrutable ways are amateurish), or through tools - written at best by the translators themselves.
- Translation and editing is the essence of the process. The result of these works is estimated by the players.
- Translation assembly - converting resources back into game formats and replacing original game data with them. Ideally, this process should consist only in launching tools for automatic assembly, but, unfortunately, for most translators it consists in manual editing each time if necessary to make changes.
- Testing is a mandatory step that allows you to identify many errors and sometimes improve the translation. Among those who desire to play their favorite game in their native language, the most responsible and competent are selected, then they are handed a beta version of the translation with a request to reproduce as many game situations as possible. And a fresh view from the outside is always good, the team may simply not see many mistakes.
If you delve into the details, then there is no sequence of actions that is the same for all cases, which must be carried out in order to prepare the game for translation. Also, there are no universal methods with which you can perform certain steps. In fact, it is always improvisation, but still there is a list of tasks that occur almost always.
I will try to highlight the most often arising and important tasks, having told about each of them separately. As a platform, we will not consider anything concrete - i.e. Everything described below is valid for both PCs and any other platform - be it from any PlayStation, XBOX, or at least Sega or Dendy (NES).
Since in this context most of the reverse engineering tasks can be solved by means of a debugger or disassembler, I will only mention them in some cases.
Text encoding definition
 It would seem that a completely trivial task is to determine in which encoding the text is stored. And in most cases this is really not difficult, but even here the thought of the developers knows no bounds.
It would seem that a completely trivial task is to determine in which encoding the text is stored. And in most cases this is really not difficult, but even here the thought of the developers knows no bounds.Not always the displayed text is stored exactly as text, more often it is just a set of character indexes in the font that need to be displayed. Often they are made compatible or partially compatible with any encoding, mostly the first 256 Unicode characters. Whatever it was, you still need to establish an exact match between the characters and their codes. However, in modern games, it is increasingly common to use ordinary encodings instead of indexes and serialize text into formats like XML - no one has ever thought much about performance for a long time.
For the encoding representation, “encoding tables” are used - text files, where in each line of a certain sequence of bytes a certain sequence of characters is mapped. It looks like this:
41=A 42=B ... 5A=Z 1E20=Hero 1E21=Item 1E22=Bonus For example, the text “Hero obtains Item!” Would be encoded as follows: “
1E 20 20 6F 62 74 61 69 6E 73 20 1E 21 21 ”. However, if it turns out that the resulting encoding is sufficiently compatible with any usable encoding (say, with Unicode), then the table is generally not needed and you can skip this step.The most common way to determine the encoding and find the text is the so-called "relative search" (relative search). Its essence is that no absolute values are searched for: the search criterion is the difference between the values of the desired sequence. To do this, it is enough to take some not too short word found in the game, and all sequences of bytes will be found in which the difference between the elements is equal to the difference between the character codes of the source word.
For example, for the word "WORLD" there is both the sequence "57 4F 52 4C 44" and "77 6F 72 6C 64". Yes, at least "13 0B 0E 08 00"! Finding such sequences and making sure that it is an encoded word, we can easily create a table of encoding. The most famous program with such functionality is the Hex editor Translhexion . There is also a bunch of specialized utilities like Search Relative . And many of the technically literate translators wrote similar utilities for themselves.
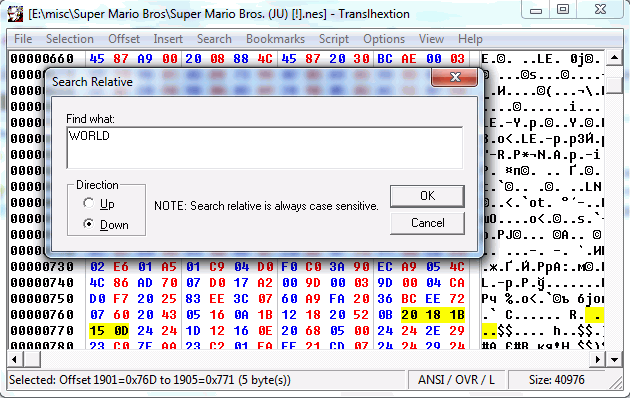
A typical case: if you compare this screenshot with a canvas of a font, you can see that the sequence found is the character indexes in the font:

In general, this technique, although applicable in the vast majority of cases, but without some tweaks, does not always work. After all, no one guarantees that the character codes in the encoding are in the same order as the letters in the alphabet.
For example, in reprints of many parts of Final Fantasy for the GameBoy Advance and Nintendo DS, the characters in the font are sorted by frequency of occurrence, and for encoding indices the method resembling UTF-8 is used. Those. Any character with a code greater than 0x7F is encoded with two bytes, while the first 128 characters are encoded with only one:
uint16 encode(uint16 code) { return 0x8000 | ((code << 2) & 0x1F00) | (code & 0x3F); } A more severe case in my memory is Final Fantasy: 20th Anniversary Edition for the PlayStation Portable. For each location there existed its own font, its own text and, as a result, its own encoding. The font consisted only of characters found in the text, which were also ordered by frequency of occurrence. It would be good to use neural networks to recognize the encoding of each location, but the benefit is enough pixel-by-pixel comparison of the character transparency masks.
In these cases, the relative search is also suitable for solving the problem, but it is necessary to search not for the difference between the numbers of letters, but for the difference between the indexes of their characters in the font. Those. You can simply write a sequence of indexes - it is quite fit for such a search.
Like other resources, text can be packed or encrypted. In this case, the search among the game data will help only in cases where at least some fragments of words are still present in the packed or encrypted data (this often happens when using algorithms like LZ77 or RLE ). Therefore, the output can be a search in the core dump. The ability to extract a dump depends on the platform for which the transfer is being made. For emulated consoles and PCs, there should be no difficulties - there are a lot of tools for accessing the game’s memory. But in other cases, you need the opportunity during the game to run the necessary code on the console, for which, as a rule, the console must be “hacked”. I will tell you about the methods for analyzing the algorithms themselves in the next article.
Pointer Search
 If the data is stored in serialized form, this item can be safely skipped. If resources are stored in an executable file (which is almost always true for consoles using cartridges) in a ready-to-use form, then, as a rule, there is a pointer to each such resource. Naturally, this also applies to the text. Moreover, in order to make it possible to freely modify the text, it is necessary to find all the pointers and references to each of the variable lines.
If the data is stored in serialized form, this item can be safely skipped. If resources are stored in an executable file (which is almost always true for consoles using cartridges) in a ready-to-use form, then, as a rule, there is a pointer to each such resource. Naturally, this also applies to the text. Moreover, in order to make it possible to freely modify the text, it is necessary to find all the pointers and references to each of the variable lines.It's funny that for a number of beginners understanding the concept of pointers is one of the most difficult obstacles in mastering the art of amateur translation. As a rule, such people for a long time do not bother themselves with the technical side of the process and translate the text so that it fits in the length of the original line. Even more amusing is that in order to improve skills, many of them end up mastering programming. It would be worth it in the reverse order - and everything would be much easier. Although it is worth noting that people who have become full-fledged IT-specialists often leave this scene and begin to deal with things more seriously.
Very often, all pointers are stored in a single place, which is usually called the "table of pointers" - it is an array of pointers or elements containing them. In such cases, the game accesses the rows by indices, which, in turn, take a pointer from such a table. Then it suffices to find a pointer to any line in the block of text - and the table is found!
But not everything is so simple ... or rather, not always everything is so simple. One of the difficulties that make it difficult to find pointers is called the “offset difference”. The fact is that the pointer can be not only absolute (pointing to the logical or physical address of the resource), but also relative (indicating an offset relative to some address). Or, say, on old disk consoles like the PlayStation, data is often stored in a form prepared for loading into memory - i.e. as long as they are in the file, it is impossible to just calculate what the pointer will point to without knowing the address where the download will take place.
Until the difference in offsets is known, it is impossible to uniquely calculate the pointer. Therefore, the first step is usually to check the availability of the table - for this the same relative search can help. As the elements of the desired sequence, the distances between the beginnings of the lines are taken - the difference between the values of the pointers will be exactly the same. If the table is not found - repeat the search, sorting out possible sizes of pointers and possible distances between them (if in addition to pointers there are other data in the tables).
// char* strings[] = {...}; // ... struct Message { int characterId; int messageType; char* string; }; Message messages[] = {...}; However, not all cat Shrovetide - some games refer to the line straight at the pointer without using tables. Then the difference is calculated as they can: for example, by visual analysis of data or using a disassembler. There is one more “old-fashioned” way: the data sections will be “lousy”, replacing the bytes, and see if this has any effect on the game. Thus, by shortening the search range using the exclusion method, you can localize the code segment that is responsible for displaying any line and find the pointer. For such purposes, there are even whole specialized tools such as Toadstool or Visual Poganka .
Without the use of tables, the pointers will be scattered throughout the code space in the executable file, and sometimes not in a single instance. If the text is stored in one place, this problem can be solved by scanning it and finding all the pointers to the beginning of each line. And in most cases it is not difficult - due to the peculiarities of the address space, the likelihood of a pointer's value colliding with another value is minimal (for example, the memory is addressed in the range 0x08000000-0x09FFFFFF or the data section starts at 0x00472000).
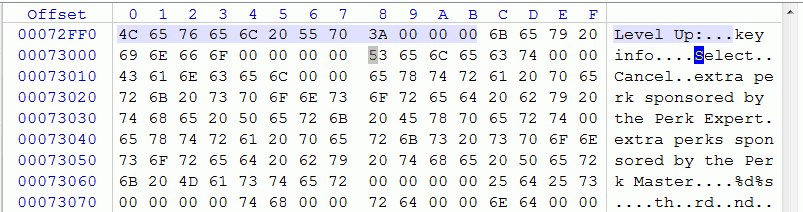
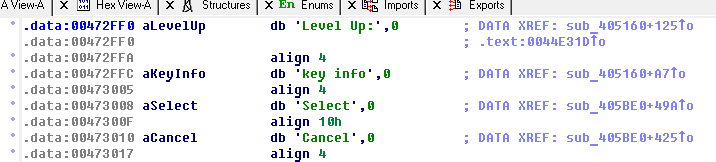
But it also happens that the memory is addressed in a less successful way for the translator: for example, starting with a zero address. And then the collisions are certainly not to be avoided ... It is necessary to manually check each value that occurs more than once for whether it is a pointer or data with the same value. And if the text itself is scattered around the file, then you can only automate the process of searching for pointers by writing some script or plugin for IDA Pro .
One way or another, patience and hard work are going to be done. It is enough to find the pointers once and then with this task you can not bother, moving on to the next step.
Extract text
 The method of “digging out” the text on the tables depends on the level of organization of the translators. So, the most unorganized guys (as a rule, beginners) do not bother at all and translate the text directly into hex editors. A little bit more serious - they use for extracting all-matching programs like PokePerevod or the same Translhexion. People with deeper knowledge use more specialized automation tools like Kruptar . The most advanced specialists usually write their own scripts or tools for this, which completely allows them to control the process completely.
The method of “digging out” the text on the tables depends on the level of organization of the translators. So, the most unorganized guys (as a rule, beginners) do not bother at all and translate the text directly into hex editors. A little bit more serious - they use for extracting all-matching programs like PokePerevod or the same Translhexion. People with deeper knowledge use more specialized automation tools like Kruptar . The most advanced specialists usually write their own scripts or tools for this, which completely allows them to control the process completely.In any case, in most cases the process is reduced to converting a stream of bytes into a form suitable for reading and editing, using information about encodings, binary tags and bytecode used by the game, if it takes place.

But it’s not at all the fact that the developers initially stored the text separately and in a pure form. Very often it is only a part of other data - level maps, scenarios, etc. If someone is familiar with game editors like the TES Construction Set , he will understand what this is about. In such cases, since the text is stored together with other data, it is necessary to “parse” their structure and accurately extract text and other necessary information — for example, sometimes in addition to text, you also need to change data such as its output coordinates and the size of dialog boxes. Sometimes, whole editors are written for this, which partially reproduce the functionality of the tools used by the developers.
In general, to extract the text I have my own approach. To begin with, the standard encoding table format is quite simple and does not cover all cases. For example, it is sometimes important to know which byte sequences are used to indicate the end of text, line breaks, or clear the screen. Also in the game can be used, for example, markup codes, where a certain part of the bits acts as a parameter. In this case, you would have to write down the whole thing like this:
1E40=[size=0] 1E41=[size=1] 1E42=[size=2] ... 1E4F=[size=15] Therefore, there are many add-ons over this format - I even developed my own extension, which allowed to describe even markup codes and other bytes with parameters, and also supported directives like include (conveniently, when there are tables for different languages, but they have the same elements) .
Consider an example of a table in an extended format:
; escape- ( \n ..) .format ; ( ) ; , C2A5=[Av-0] C2B3={Hero} ; , «» ("~") ; ( , ..) C2B7C391~=\n-> C2B7~=\n- ; — , «» "^" ; ... :) C28E^=\n ; .include opcodes.tbl .include avatars.tbl ; ( - C string), «» ; , , ; 0D!= Despite some porridge in the table, the output was pretty neat for the game script text:
Jenica: I've served this castle for quite
some time. I looked after both Princess
Lenna and Princess Sarisa.
-
[Av-0] {Hero}: Sarisa?
->
Jenica: Princess Lenna's older sister.
Sarisa was sailing with her father when
a storm hit
The role of neatness will be discussed below, and now we will consider the problem of bytecode. Some games even use their own scripting languages , and it's good if the text in them is used as external resources. But sometimes still have to rake a jumble of text and code.
If it is impossible to separate the code from the text, then usually for each instruction, a mnemonic and a form of a recording are created on the basis of its purpose. Having a database with information about all instructions, it is easy to write a translator. But in order not to write such things every time, I came up with another extension for the encoding table.
The instruction in the bytecode is identified by the specific values of some bits. Suppose we have two instructions the size of a byte. In one instruction, bits one through four are
0101 , i.e. it looks like 0101nnnn ; the other one - the first two bits are 11 , i.e. We write it as 11nnnnnn . The easiest way to identify an instruction is by mask comparison — i.e. it is necessary to produce a logical multiplication of the identifiable code by the bit mask, thus highlighting the necessary bits, and compare the result with the reference data (hereinafter, we will call this the instruction identifier). Thus, for the first instruction, the mask will be 11110000 , since we need to take only the first 4 bits, and the identifier, respectively, will be 01010000 . For the second instruction, both the mask and the identifier are equal to 11000000 .
The essence of the extension is that for instructions, you can directly write bit masks and identifiers in the table that are needed to define them and read the parameters. And instead of a simple sequence of characters, you can use a special string that will talk about how to format and convert the text representation of the instruction back to bytecode. Those. according to such tables one could even primitively disassemble executable files.
The form of such an instruction record in the encoding table is as follows:
<OpcodeMask>?<OpcodeID>:<ValuesMasks>=<FormatString> Where OpcodeMask is a mask, OpcodeID is an identifier, ValueMasks is a comma-separated list of bitmasks of parameters, and FormatString is a string for formatting the text representation of the instruction and converting it back into bytecode (this is a modified equivalent of format strings for the printf function).
For example, we have an instruction of the form
1010iiii cccccccc , showing in the pop-up window the colors with the item i . Let's call it "popup (item, color)". The mask of this instruction is 11110000 00000000 , which in hexadecimal representation will be F000 . The instruction identifier will be equal to 10100000 00000000 , i.e. C000 , and the parameter masks are 00001111 00000000 and 00000000 11111111 , that is, 0F00 and 00FF respectively.Suppose we have such a coded text:
0000: 4F 62 74 61 69 6E 65 64 20 61 6E 20 69 74 65 6D Obtained an item0010: 21 C1 0F 0A 4E 6F 77 20 79 6F 75 20 63 61 6E 20 !##\nNow you can0020: 6F 70 65 6E 20 74 68 65 20 64 6F 6F 72 2E open the door.Let's try to decode it using a table in which there is such a record:
F000?C000:0F00,00FF=popup(%d, %d) We get the following result:
Obtained an item! Popup (1, color)
Now you can open the door.
Not very well combined with the text. Therefore we will try to resort to the help of tags. Let it be XML tags:
F000?C000:0F00,00FF=<popup item="%d" color="%d"/> Already much better:
Obtained an item! <Popup item = "1" color = "255" />
Now you can open the door.
But it would be even better if instead of “magic constants” we saw a textual representation of the parameters. For this, I introduced the ability to declare transfers in the form:
%{<member1>[=value],<member2>[=value],...} Suppose such an instruction applies only to three items: a bomb with the number 0, a key with the number 1, and a coin with the number 10:
F000?C000:0F00,00FF=<popup item="%{Bomb,Key,Coin=10}" color="#%2x"/> As you can see, at the same time for the color, I applied a more familiar entry. Of course, it’s silly to do this with an eight-bit color representation, but this is just an example taken from the head for clarity.
Next, we just have to turn on tag highlighting and can get more or less readable text:
Obtained an item!<popup item="Key" color="#0F"/> Now you can open the door. If the semantics of instructions are not so important (that is, the translation does not imply editing them), then it is better to resort to a shorter record, or in some places the code may turn out more than text. For example:
Obtained an item! {Popup: Key, 0F}
Now you can open the door.
For instructions with exactly one parameter, I provided a shortened form of recording. The following are two equivalent strings:
FF00?3C00:00FF=<pause time="%d"> 3C??=<pause time="%d"> As can be seen from the record, I selected the parameter bits with the question marks, the remaining bits are considered the unit bits of the mask, and the identifier is obtained by replacing the question marks with zeros. Unfortunately, such a record is possible only for instructions where the sizes of the parameter and identifier are a multiple of four bits, i.e. the size of one hexadecimal character.
Text presentation
 This is one of the most important parts of the process, because the extracted text will go straight to the translators, and not only the productivity of their work, but also the number of structural and semantic errors that they make will depend on how tidy it is. In essence, this process is the refinement of the text extraction mechanism so as to simplify the work of translators as much as possible.
This is one of the most important parts of the process, because the extracted text will go straight to the translators, and not only the productivity of their work, but also the number of structural and semantic errors that they make will depend on how tidy it is. In essence, this process is the refinement of the text extraction mechanism so as to simplify the work of translators as much as possible.If we consider the text described in the previous paragraph, then for the translator a brief excursion on the purpose of tags and other rubbish is sufficient, especially it should not frighten him. But, it should be noted that the main, in my opinion, error in the presentation of the text is an overwhelming amount of technical information. For most amateurs, such a text would look very different:
Jenica: I've served this castle for quite ^
some time. I looked after both Princess ^
Lenna and Princess Sarisa. ^ {CLS}
[# C2] [# A5] [# C2] [# B3]: Sarisa? ^ {CLS} [# C3] [# 91]
Jenica: Princess Lenna's older sister. ^
Sarisa was sailing with her father when ^
a storm hit the sea. {END}
In the place of a translator, I would say: “and how would you like it to be translated?”
Alas, judging by the fragmentary information, this is also encountered in the process of official localizations: they will give the text in XML or INI format with “\ n” as a line break, and translate as you wish. At the same time, many people, even in such cases, do not change Word, which is able to kill almost any such format with any kind of auto replacement, or worse.
, , , , . - «» — Word, «», .
, . , , , .. . , :
&push;&main-color=#E67E00FF;Energy Cell ID:&pop;
SN-3871S-7
&push;&main-color=#E67E00FF;Status:&pop;
&if=hasitem:Fuse7Used;Used&else;&if=hasitem:Fuse7;Acquired&else;Unknown&endif;&endif;&if=scan:SCAN,0x6479E69556A56AC8;
&if=(hasitem:Fuse7Used)|(hasitem:Fuse7);
&push;&main-color=#E67E00FF;Previous Coordinates:&pop;&else;
&push;&main-color=#E67E00FF;Coordinates:&pop;&endif;
&if=mapped:PirateCommand;04P-MET, Pirate Homeworld&else;04P-MET, Unknown&endif;
&just=left;Data indicates Energy Cell is connected to &push;&main-color=#FF6705B3;processing&pop; containment core.&endif;
, , ( , ). WYSIWYG-, , , . ( ) , - .
( ) , . , , «{code}» «{<group_number>}», . , , , .
But there was still some way out, and it lies in syntax highlighting. BecauseAll technical data are usually easily processed automatically, and it is not a problem to select them among the rest of the text.
For these purposes, I used the capabilities of the well-known Notepad ++ - it has a tool for creating my own backlight mechanism. I was lucky that the translator with whom I worked used Notepad ++ myself, so I didn't have to persuade anyone. Despite the limitations in creating the rules for highlighting, this possibility turned out to be quite enough, although sometimes it was necessary to resort to various crutches.
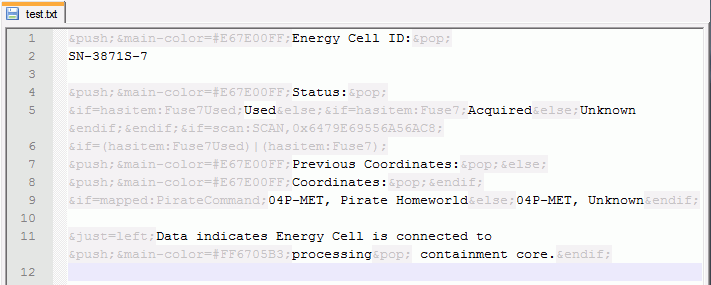
With this, it is quite possible to live. And sometimes I went even further and wrote visualizers - programs that displayed text just as it would look in a game. Well, or almost the same ...
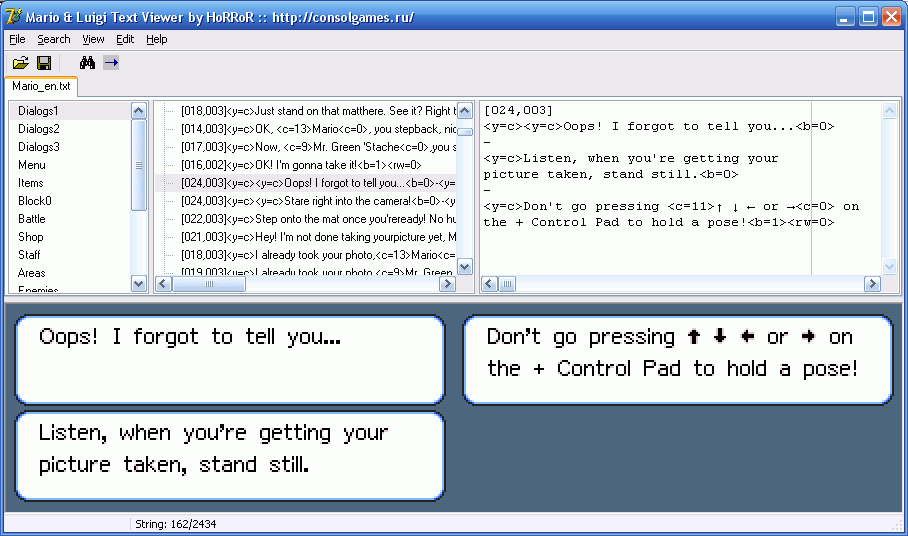
, , . , , . , .
To be continued
:
- — , , .
- — , .
- — , , .
- — , « ».
- — .
- — .
- — , .
- — , , .
Source: https://habr.com/ru/post/140930/
All Articles