Knowledge management, knowledge base creation. And what in practice?
Continuing the topic of the two previous posts ( first and second ), in which a study on knowledge management was conducted and the main results were described, I would like to delve into the practical component of this problem. There are plenty of questions for discussion here, but the main one - are there any tools that can satisfy all business needs in terms of knowledge management? Let's try to answer this question from our “bell tower”.
The knowledge management software market is extremely ambiguous. This is due to the fact that the direction is relatively young, and the definition of “knowledge management” itself is interpreted differently by different authors, which we have already mentioned in the first topic on this topic. The most famous classification is shown in the picture below (by materials - www.bigc.ru/publications/bigspb/km/itkm ). The assignment of such a broad class of software to knowledge management systems (CPS) is due to the fact that CPS knowledge refers to all types of information, including unstructured content (letters, sketches, photos), data (in databases and data warehouses), and knowledge (as patterns subject area, allowing specialists to solve their problems).
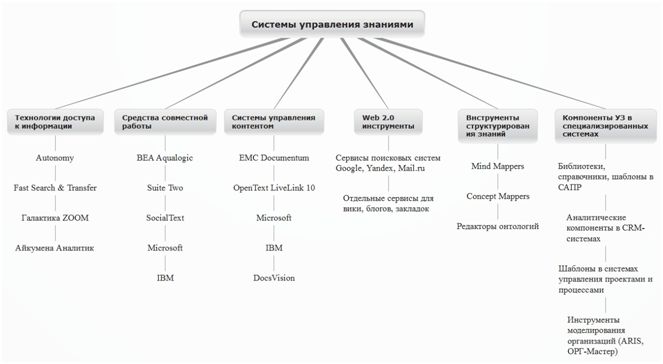
')
Of course, to analyze each branch of this small tree, even if it does not make sense, therefore, the direction for detailing has been greatly narrowed, taking into account the realities of life and the results of the research. For the sake of completeness, I cannot fail to mention two examples of creating a knowledge base (BR) in the IT field. The first is the KB of a large consulting company IBS. The information is quite old, since then, probably something has changed. I would like to mention just some basic points, the rest you can see in the presentation .
The basic concept in the KB IBS is a document. All work with the BZ from replenishment to use revolves around documents. As a software solution for such a seemingly simple approach, three dissimilar and expensive solutions are used at once. These are Documentim, SAP R / 3 and Lotus. Agree, the trinity is impressive. I want to believe that at that time there were no special alternatives, but by now something has already changed. Representatives of the company is not there at random?
The second example is the company "EliSi", which occupies a process control system in the oil and gas industry. There, it is proposed to introduce knowledge depositories using metadata, meta descriptions and ontologies as the basis of a corporate KMS. This way you can find a compromise between the necessary codification of knowledge and the high cost of this process. Those. The semantic superstructure above the enterprise information system will act as the control system of the company. The approach is more modern and meaningful, because there is semantics, which means an attempt to look inside, closer to knowledge. It is noteworthy that the initiator of the project was the general director of the company, who in parallel defended his thesis on this topic.
In the previous paragraph, Russian working examples were shown. Below is an attempt to choose the direction and criteria to which I paid attention when I outlined CPS:
Given all these factors, the direction narrowed down to wiki systems. For many reasons, one of which is the result of a survey that showed that wikis are already actively used, which means they are very familiar with their potential users. And of course, their simplicity, ease of deployment, and often openness.
The main question arose, but where is the use of semantic technologies, because it comes first? It turned out that semantic wikis have been distinguished among wiki systems for a long time, and the rest of this article will be devoted to this context. I was very surprised that there are very few mentions on this topic in Habré. In short, the main distinguishing feature compared to traditional wikis is the ability to specify the type of links between articles, the data types inside the articles, as well as information about the pages. This sentence from the eponymous article in wikipedia, for a complete description there .
In other words, semantic wikis allow you to organize and structure information more efficiently. Many semantic wikis support rdf and owl, which allows for more rigid formalization, and together with reasoners (and reasoner) and support for logical inference. At first glance, it seems that all this is an unnecessary complication, which will become another obstacle for the end user. However, in practice, working with typed data can be organized using semantic forms, and for the user it will look like another questionnaire, which is easy to operate with.
The most telling example of semantic wikis is the add-on to the MediaWiki engine, called concisely and clearly Semantic MediaWiki. Distributed under a good GNU GPL v.2 license. Ideal for those who already use the media wiki, want openness, simplicity and other features of a similar licensing policy. She has a lot of extensions, useful and not very. In general, it is worth a look.
Among all the other semantic wiki, I will focus only on two, with which I had the opportunity to at least a little, but work. Both of them are distributed under commercial licenses, but they also have a community version with somewhat limited functionality. Why on them? because they have a greater corporate focus.
The first is the semantic media wiki plus. It is based on the same extension of the semantic media wiki and is supplemented by a rich and extremely important functionality that simplifies and simultaneously expands the capabilities of semantic wikis. Plus, everything you need is immediately collected in one package, which was important for me when I was looking closely and choosing a specific system. I will not advertise any more, the product site will make it much more effective for me. What you liked:
Excellent integration capabilities, incl. including and already developed. For example, with Microsoft Office products (Word, Project), e-mail, the same SharePoint. This is also the possibility of writing connectors for your applications.
As an example of use, you can set already created ontologies project and risk management. Clearly, clearly, someone else would try in practice. In which case, the structure can always be changed by itself, it is actually easy. I also liked the fact that in the wiki with the description of the system itself, typical roles that are indicative of this class of systems were identified: ontologist, gardener, end user, developer, administrator. Perhaps two paragraphs is enough, you can see more on the site.
The second product, which I happened to meet quite a bit, is suitable for those who, for one reason or another, prefer java-technology. Called the Information Workbench (IWB). The product is exactly like the company that developed it is relatively young. I will not write about the possibilities and other usefulness, I suggest to look at the architecture and go to the developer's site for all the information. I will only note that the implementation is still damp, but everything is done competently and professionally. and scientifically;) As the representative of the company told me: “both of our directors are Ph.D.”
In this part I will briefly dwell on these three dissimilar words.
I do not conceal that I paid much attention to visualization from the very beginning. Even a separate question started in the questionnaire. The reason is that we perceive information better in visual form (I re-read my text, once again convinced of this). To work with knowledge, the best visualization is the use of the mind map (by the way, the article was quite good about this methodology).
So here. In all wikis, things are so-so. Freemind only has the ability to embed, already good. Maybe, of course, somewhere dropped something.
However, there are alternative approaches. For example, in IWB there is a representation of the ontology underlying the wiki in the form of a graph. Very comfortably. It can be used effectively. If the semantic wiki supports the SPARQL endpoint, you can try to fasten RelFinder, which will be a third-party visualizer BR. To understand the mechanism of action, you can see the finished example with Einstein and Godel. Or independently find out what is common, for example, in Moscow and Pushkin.
WorkFlow. Knowledge in isolation from practice is not needed. What is the point if they do not apply. Daily activities can be reflected in WorkFlow. What is there?
And here, too, is not very. On the one hand, the same SMW + states that smw + is “working with heterogeneous and informal workflows”. But there is no normal pragmatic solution for linking workflow and knowledge base. Here is a good comment on this:
Some first ideas (I deliberately don’t make a real distinction between a workflow and a BP here)
- using the workflows / processes => to create / improve workflows / processes =>
- using the wiki do document workflows / processes
- using the wiki to support running workflows / processes (info on background, how to share experiences, Q & A ...)
- using the workflow / BPM to steer KM processes => push info, trigger people / apps, collect info,
- using the workflow / BPM to steer wiki publishing => approvals etc
However, the BPM of the Bizagi process modeler package has an unloading of all rendered blocks of built models in the category and articles of the Media Wiki. You can very conveniently use them in bundles, facilitating your work.
The author of the English comment gave me a link where the wiki and workflow work more closely - www.adhocworkflows.com This is a third-party plugin for Confluence. Did not install, did not try, did not test. I can not comment, but I think I’m sharing what I need. Moreover, Confulence and Jira are very close, and the last one is used by many. Also for Confluence, there is also a semantic add-on - www.zagile.com/products/wikidsmart.html A great alternative for those who do not build a wiki from scratch, but redesigns an already filled existing one. I also did not test, I can not add anything from myself.
As you know, the main problem in managing knowledge in general and creating a knowledge base in particular is a lack of time and unwillingness to fill a knowledge base. Free time is often spent on surfing the Internet, to communicate with colleagues. Thinking out loud: “Let the next time doing a similar task, I’ll have to frantically recall and re-search for something, anyway, now I’m not going to work with a knowledge base, although it will contribute to more favorable work in the distant future.” But you cannot get away from this, only somehow further stimulate the employees.
As an alternative to the wiki discussed above, there is an approach that prioritizes the communication process. In part, this includes knowledge, as evidenced by the presence of one of the process of knowledge transformation in the well-known Japanese specialist Nonak - socialization, the left upper quadrant.
Here I primarily mean the project rizzoma . When I first started working on the issues raised, I really liked one of their first articles . Then the project was still under the old name. In short, rizzoma is a continuation of the concept of Google Wave, where the entire discussion is built in waves or blip-s. "Rizzoma is a collaboration-service that includes a wiki-system, an instant messenger and, in the near future, a task tracker." The service still has a lot to do, the same tasks are not there now, and the wiki is not guessed in the usual sense, but the prospects development is. I especially liked the display of the wave structure in the mindmap. With proper organization, it turns out that the structure is well perceived by an outsider. IMHO - this approach will work best in conjunction with the semantic wiki, if you instill a culture of communication in rizzoma, and the structuring is assigned to the wiki.
Waiting for your comments. Maybe someone used the products mentioned. It would be interesting to know a third-party opinion.
Ps sorry for the sheet. I didn’t want to break the topic into several, so as not to delay the next post again.
Classification of knowledge management systems
The knowledge management software market is extremely ambiguous. This is due to the fact that the direction is relatively young, and the definition of “knowledge management” itself is interpreted differently by different authors, which we have already mentioned in the first topic on this topic. The most famous classification is shown in the picture below (by materials - www.bigc.ru/publications/bigspb/km/itkm ). The assignment of such a broad class of software to knowledge management systems (CPS) is due to the fact that CPS knowledge refers to all types of information, including unstructured content (letters, sketches, photos), data (in databases and data warehouses), and knowledge (as patterns subject area, allowing specialists to solve their problems).
')
Of course, to analyze each branch of this small tree, even if it does not make sense, therefore, the direction for detailing has been greatly narrowed, taking into account the realities of life and the results of the research. For the sake of completeness, I cannot fail to mention two examples of creating a knowledge base (BR) in the IT field. The first is the KB of a large consulting company IBS. The information is quite old, since then, probably something has changed. I would like to mention just some basic points, the rest you can see in the presentation .
The basic concept in the KB IBS is a document. All work with the BZ from replenishment to use revolves around documents. As a software solution for such a seemingly simple approach, three dissimilar and expensive solutions are used at once. These are Documentim, SAP R / 3 and Lotus. Agree, the trinity is impressive. I want to believe that at that time there were no special alternatives, but by now something has already changed. Representatives of the company is not there at random?
The second example is the company "EliSi", which occupies a process control system in the oil and gas industry. There, it is proposed to introduce knowledge depositories using metadata, meta descriptions and ontologies as the basis of a corporate KMS. This way you can find a compromise between the necessary codification of knowledge and the high cost of this process. Those. The semantic superstructure above the enterprise information system will act as the control system of the company. The approach is more modern and meaningful, because there is semantics, which means an attempt to look inside, closer to knowledge. It is noteworthy that the initiator of the project was the general director of the company, who in parallel defended his thesis on this topic.
And what we need
In the previous paragraph, Russian working examples were shown. Below is an attempt to choose the direction and criteria to which I paid attention when I outlined CPS:
- The use of semantic technologies. When working with knowledge, semantics should not be ignored. One of the fundamental points.
- Orientation to small and medium business. It is clear that using Documentum, you can close a lot of issues related to IT infrastructure, and SharePoint, according to Microsoft, can do everything, but you need something more mundane.
- Collaboration support and high degree of interoperability. If the collaboration with the majority of corporate information systems is more or less, then interintergovernment (I don’t like borrowed terms) is different everywhere. It is obvious that the knowledge base should not be closed and separate IP.
- Trivia-utility, which emerged from the survey, namely: linking BR with workflow and the use of visualization (in particular, mind mapping).
Given all these factors, the direction narrowed down to wiki systems. For many reasons, one of which is the result of a survey that showed that wikis are already actively used, which means they are very familiar with their potential users. And of course, their simplicity, ease of deployment, and often openness.
The main question arose, but where is the use of semantic technologies, because it comes first? It turned out that semantic wikis have been distinguished among wiki systems for a long time, and the rest of this article will be devoted to this context. I was very surprised that there are very few mentions on this topic in Habré. In short, the main distinguishing feature compared to traditional wikis is the ability to specify the type of links between articles, the data types inside the articles, as well as information about the pages. This sentence from the eponymous article in wikipedia, for a complete description there .
In other words, semantic wikis allow you to organize and structure information more efficiently. Many semantic wikis support rdf and owl, which allows for more rigid formalization, and together with reasoners (and reasoner) and support for logical inference. At first glance, it seems that all this is an unnecessary complication, which will become another obstacle for the end user. However, in practice, working with typed data can be organized using semantic forms, and for the user it will look like another questionnaire, which is easy to operate with.
Semantic wiki. Alas, too many of them
The most telling example of semantic wikis is the add-on to the MediaWiki engine, called concisely and clearly Semantic MediaWiki. Distributed under a good GNU GPL v.2 license. Ideal for those who already use the media wiki, want openness, simplicity and other features of a similar licensing policy. She has a lot of extensions, useful and not very. In general, it is worth a look.
Among all the other semantic wiki, I will focus only on two, with which I had the opportunity to at least a little, but work. Both of them are distributed under commercial licenses, but they also have a community version with somewhat limited functionality. Why on them? because they have a greater corporate focus.
The first is the semantic media wiki plus. It is based on the same extension of the semantic media wiki and is supplemented by a rich and extremely important functionality that simplifies and simultaneously expands the capabilities of semantic wikis. Plus, everything you need is immediately collected in one package, which was important for me when I was looking closely and choosing a specific system. I will not advertise any more, the product site will make it much more effective for me. What you liked:
Excellent integration capabilities, incl. including and already developed. For example, with Microsoft Office products (Word, Project), e-mail, the same SharePoint. This is also the possibility of writing connectors for your applications.
As an example of use, you can set already created ontologies project and risk management. Clearly, clearly, someone else would try in practice. In which case, the structure can always be changed by itself, it is actually easy. I also liked the fact that in the wiki with the description of the system itself, typical roles that are indicative of this class of systems were identified: ontologist, gardener, end user, developer, administrator. Perhaps two paragraphs is enough, you can see more on the site.
The second product, which I happened to meet quite a bit, is suitable for those who, for one reason or another, prefer java-technology. Called the Information Workbench (IWB). The product is exactly like the company that developed it is relatively young. I will not write about the possibilities and other usefulness, I suggest to look at the architecture and go to the developer's site for all the information. I will only note that the implementation is still damp, but everything is done competently and professionally. and scientifically;) As the representative of the company told me: “both of our directors are Ph.D.”
Visualization - Mind map, WorkFlow and Confulence
In this part I will briefly dwell on these three dissimilar words.
I do not conceal that I paid much attention to visualization from the very beginning. Even a separate question started in the questionnaire. The reason is that we perceive information better in visual form (I re-read my text, once again convinced of this). To work with knowledge, the best visualization is the use of the mind map (by the way, the article was quite good about this methodology).
So here. In all wikis, things are so-so. Freemind only has the ability to embed, already good. Maybe, of course, somewhere dropped something.
However, there are alternative approaches. For example, in IWB there is a representation of the ontology underlying the wiki in the form of a graph. Very comfortably. It can be used effectively. If the semantic wiki supports the SPARQL endpoint, you can try to fasten RelFinder, which will be a third-party visualizer BR. To understand the mechanism of action, you can see the finished example with Einstein and Godel. Or independently find out what is common, for example, in Moscow and Pushkin.
WorkFlow. Knowledge in isolation from practice is not needed. What is the point if they do not apply. Daily activities can be reflected in WorkFlow. What is there?
And here, too, is not very. On the one hand, the same SMW + states that smw + is “working with heterogeneous and informal workflows”. But there is no normal pragmatic solution for linking workflow and knowledge base. Here is a good comment on this:
Some first ideas (I deliberately don’t make a real distinction between a workflow and a BP here)
- using the workflows / processes => to create / improve workflows / processes =>
- using the wiki do document workflows / processes
- using the wiki to support running workflows / processes (info on background, how to share experiences, Q & A ...)
- using the workflow / BPM to steer KM processes => push info, trigger people / apps, collect info,
- using the workflow / BPM to steer wiki publishing => approvals etc
However, the BPM of the Bizagi process modeler package has an unloading of all rendered blocks of built models in the category and articles of the Media Wiki. You can very conveniently use them in bundles, facilitating your work.
The author of the English comment gave me a link where the wiki and workflow work more closely - www.adhocworkflows.com This is a third-party plugin for Confluence. Did not install, did not try, did not test. I can not comment, but I think I’m sharing what I need. Moreover, Confulence and Jira are very close, and the last one is used by many. Also for Confluence, there is also a semantic add-on - www.zagile.com/products/wikidsmart.html A great alternative for those who do not build a wiki from scratch, but redesigns an already filled existing one. I also did not test, I can not add anything from myself.
And what else
As you know, the main problem in managing knowledge in general and creating a knowledge base in particular is a lack of time and unwillingness to fill a knowledge base. Free time is often spent on surfing the Internet, to communicate with colleagues. Thinking out loud: “Let the next time doing a similar task, I’ll have to frantically recall and re-search for something, anyway, now I’m not going to work with a knowledge base, although it will contribute to more favorable work in the distant future.” But you cannot get away from this, only somehow further stimulate the employees.
As an alternative to the wiki discussed above, there is an approach that prioritizes the communication process. In part, this includes knowledge, as evidenced by the presence of one of the process of knowledge transformation in the well-known Japanese specialist Nonak - socialization, the left upper quadrant.
Here I primarily mean the project rizzoma . When I first started working on the issues raised, I really liked one of their first articles . Then the project was still under the old name. In short, rizzoma is a continuation of the concept of Google Wave, where the entire discussion is built in waves or blip-s. "Rizzoma is a collaboration-service that includes a wiki-system, an instant messenger and, in the near future, a task tracker." The service still has a lot to do, the same tasks are not there now, and the wiki is not guessed in the usual sense, but the prospects development is. I especially liked the display of the wave structure in the mindmap. With proper organization, it turns out that the structure is well perceived by an outsider. IMHO - this approach will work best in conjunction with the semantic wiki, if you instill a culture of communication in rizzoma, and the structuring is assigned to the wiki.
Waiting for your comments. Maybe someone used the products mentioned. It would be interesting to know a third-party opinion.
Ps sorry for the sheet. I didn’t want to break the topic into several, so as not to delay the next post again.
Source: https://habr.com/ru/post/140903/
All Articles