Knee to PDF. PHP parser with buns
It so happened that, a month ago, a completely unexpected task grew up before me: convert PDF to html using the existing template. Including it was necessary to break everything into pages and select paragraphs in them. And a lot more then. And all would be nothing, and I would have managed with some kind of left library, but some specific tweaks, so necessary for me, were not found in the libraries. And it was sad ...
Sadly, the search for good articles and fresh documentation in Russian led me to two useful sources of information: here and here . Both the article and the other were very useful for a general understanding of the essence of the PDF, but did not at all solve the tasks set before me. And then he came onto the scene - ISO 3200-1. This Giant of 756 pages practically saved me, having devoured, in exchange, a car and a small cart of time.
And yet, I strongly recommend to anyone who is going to work with PDF, as a reference:
Buy online ISO standard here
Download here
And here from the site itself Adobe
In the shortest possible time, I needed to write a stray script in PHP, which would more or less save memory, because on average, PDF files from 6 to 40 MB were expected. At the same time, she had to extract the contents by pages, break the text into logical blocks (paragraphs and headings), extract pictures and table of contents.
First, a little theory. Here is an example of a PDF file opened in Notepad.
')

Even with the unarmed eye, you can see that in addition to the strange krakozyablikov there is also a meaningful text in the file and this is good news. It is he who will help us in everything to understand.
As it turned out (and helped ISO 3200-1 here), the PDF has approximately the following structure:
The first line describes the PDF version . The second is a mysterious line in which I did not understand as superfluous. Although I admit that it is hidden the true essence of our universe and in general. Next is the description of the objects.
Objects are universal structures that describe all the data stored in a PDF and their logical connections. Each object consists of the “NM obj” type header (without quotes), where N is the object number, M is its version (for the sake of honor, I note that I never met an object where M! = 0). After the title of the object are its properties in the << >>. And finally, there is an optional data stream surrounded by a pair of stream, endstream. All parts of the object are separated by line breaks. These elements I will discuss in more detail later. For now, let's move on from the objects to the final part of the PDF document.
cross-reference table - A certain table that stores the addresses of each object in the file. This table has approximately the following structure:

The first line is the xref keyword. The second is two numbers, which designate from what for what objects are described in it. Then the table itself goes directly. Each line of the form 0000000032 65535 f describes an object of the corresponding number. Do not forget that in some tables the numbering will not begin with the first object, but with the one that is described in the line after the keyword xref. The first group of digits: 10 digits (the value is supplemented with insignificant zeros on the left) denoting the address in the file from which the object begins.
UPD: Thank you, pleax for pointing out the flaws. Corrected.
The second group: 5 digits not more than 65535 (int) denoting the revision number of the object. and the last character is either n (for the objects used) or f for free-objects (which have been deleted). When an object is deleted, its edition number (generation) is incremented by 1, and the flag (n / f) is set to f. In addition, the revision number can be set to 65535. Such an object is considered free and is never used again. Read more on page 40 of the PDF documentation.
Immediately after the table comes the trailer keyword, after which you can find the properties of the table. We will be interested in only one: / Prev 321249. Here, the number indicates the address in the file with which the preceding table begins. Accordingly, the very first table does not have such a property.
After the properties of the table, you can find another keyword startxref, after which a number denoting the address of the beginning of this table.
This knowledge will be enough for us to unload the table of all PDF objects, so that in the future we will not have to load the entire PDF into memory. And now we take a beer and practice.
Nuss. Let's get the bat. Here are some of my govnokoda:
I think that in general, the code is clear: Find the address of the last table, save its values into an array, read the address of the trace of the table. We create the last table only because in PHP it is difficult to know the next element of the array. And in my case it was easier for me to store an extra table than to run through the entire array every time in search of the right element.
Now that we have an array of RefTable ['object number'] = 'Address of the object' We can use a simple function to read the files item by object. For example:
Let's return to our objects, and more precisely to their properties. There are 9 basic data types in PDF:
Boolean - True, False;
Numeric - int (623, +17, -98), real (34.5, -3.62)
LiteralString - Character set in parentheses (abcd)
Hexademical Strings - <4E6F7620> A string of hexadecimal values.
Name - / Prev character set field slash
Array - [/ name 1 / name1 / name2] an array of objects of arbitrary type
Dictionary - A key-value type set, where the key is always an object of type Name (/ Prev), and a value is an object of any type, including other dictionaries. Dictionaries are always surrounded by << >>
Stream - Some data that can be encoded anyway.
NULL - Speaks for itself
See the 14th documentation page for more details.
So the properties of the object are stored in dictionaries (Dictionary). And first of all we will be interested in the property / Type in which, oddly enough, is the type of the object. To begin, we will find two objects: / Type / Catalog and / Type / Pages in the first, in the form of properties, references to objects with service information and data structures are stored, including to / Pages 2 0 R (This is for example). Here you can see that the property / Pages matches the object number 2 0 R of the type / Type / Pages.
The object / Type / Pages, which we find under number 2 in our table, is valuable in that it contains an array of / Kids [3 0 R 29 0 R] with numbers in the properties. The objects that we find in this array can be either another node / Type / Pages with its / Kids, or the objects we are looking for / Type / Page I mean pages.
And here comes the time for a bottle of cold dark.
Here is the function that will receive
Next is an auxiliary function that recursively helps us in searching for kid pages.
Well, what happened is a miracle: we have the table number Object-> the address of the object and there is the table NumberPage-> Number of the object. The case is left to go: Get the contents of the pages and break it into logical structures.
Sometimes after the objects you can find a bunch of obscure characters, and sometimes they can be found in the object to which you can find links in the property / Resources of the object. This is coded data. In the dictionary of such objects you will find the / Filter property to which both a single value and an array can be assigned (Important! It may be that the data after the object will not be encrypted. In this case, the / Filter properties will not be present. And even the zhoshkolnik will be able to read the stream ). A list of all possible filters can be found in the documentation on page 22, however, I’ll stop at one. / Filter / FlateDecode is the most common filter and in 99% of cases only it is enough. FlateDecode is nothing more than a regular gzip and all we need is gzuncompress ($ stream). There is one thing here. According to the FlateDecode standard, the first 4 bits of the data are overhead and are not interpreted, but in some PDFs these bits are missing and gzuncompress () data error may occur. I can rejoice you: one well done wrote a patch for us. Go here and read
And so it means that we have done such good work and have extracted data from the stream, and there:
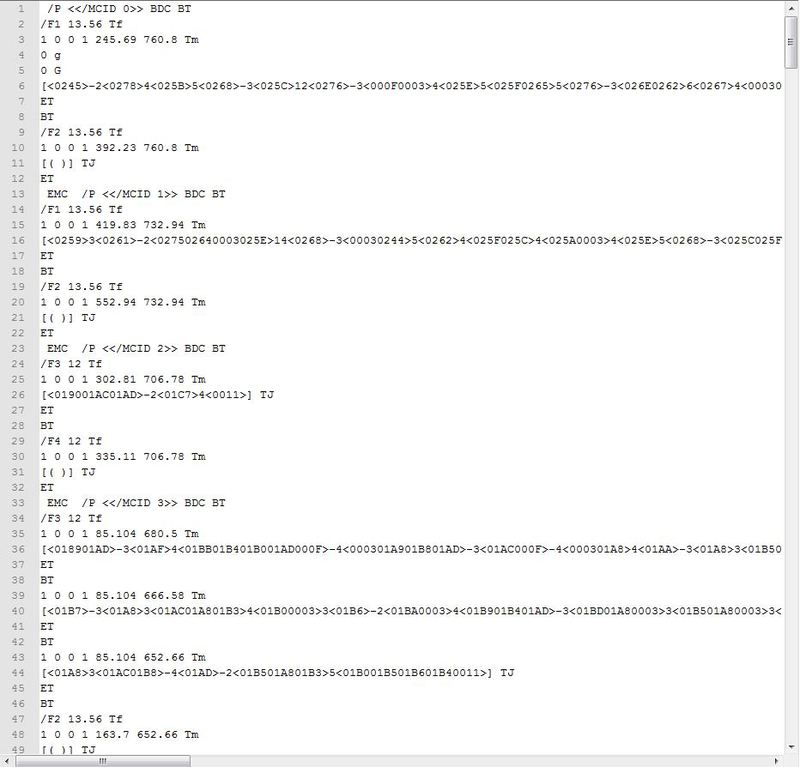
And there is a text. We are still interested in the following lines:
A string that ends in BT. It may well be that the line will only BT
A string that ends with Tf. It describes the fonts used in the text block.
String ending in TJ. In it we will find the text itself (almost).
Well, it will all end ET
Let us examine all the details on the example
/ P << / MCID 0 >> BDC BT
/ F1 13.56 Tf
1 0 0 1 245.69 760.8 Tm
0 g
0 G
[<0245> -2 <0278> 4 <025B> 5 <0268> -3 <025C> 12 <0276> -3 <000F0003> 4 <025E> 5 <025F0265> 5 <0276> -3 <026E0262> 6 < 0267> 4 <00030262> 6 <00030266> 7 <0268> -3 <026A> -3 <025F0011>] TJ
ET
BT and ET are nothing but begin of text and end of text. Before BT there is a marker that actually helps to highlight the logical structures in the text (Paragraphs and headings) In this article I will not elaborate on this. For the time being, you can take each such << / MCID 0 >>, << / MCID 1 >> block as the beginning of a paragraph or read the Logical Structure section in the documentation on page 556. If anyone is interested, I can add an article.
In the font line we are interested in / F1 and squiggles. / F1 - the name of the font that we need to decode the text (yes, yes, our torment has not yet ended) and obtain text styles
Before TJ in [] is the desired text. Now we can get lucky and we will see the text. Plain text is always in parentheses. If we are unlucky, and so it will be, then we will find groups of numbers in the triangular brackets. Every 4 digits is one character, the hexadecimal value of which can be found in the correspondence table, and the correspondence table in the font object that we found earlier, the hare in the duck, and the duck in the egg ... Oops, I suffered ...
Finding a table of character codes is not difficult: the page that we decoded has the / Resources property, and << / Font << / F1 5 0 R / F2 10 0 R / F3 12 0 R in it… .......... What do you already do we guessed it: go to the object number of the corresponding font, and in that object (this is not a joke) there is a property / ToUnicode 98 0 R There you will find the table. What to do with her well described in Habré . Who is not enough - you can look at the source, which I will attach.
For now. This was just a general overview. If there is interest, I will tell you in more detail how to extract images, a catalog, tables, styles, other buns. If you have questions, you are welcome. And yes, I ask you not to troll the code very much, it does not pretend to read it, only to explain the whole in general.
And lastly A bit of code for a common understanding.
0. First there was a word and there was this word: “documentation”
Sadly, the search for good articles and fresh documentation in Russian led me to two useful sources of information: here and here . Both the article and the other were very useful for a general understanding of the essence of the PDF, but did not at all solve the tasks set before me. And then he came onto the scene - ISO 3200-1. This Giant of 756 pages practically saved me, having devoured, in exchange, a car and a small cart of time.
And yet, I strongly recommend to anyone who is going to work with PDF, as a reference:
Buy online ISO standard here
Download here
And here from the site itself Adobe
1. From words to deeds. Attention! Task
In the shortest possible time, I needed to write a stray script in PHP, which would more or less save memory, because on average, PDF files from 6 to 40 MB were expected. At the same time, she had to extract the contents by pages, break the text into logical blocks (paragraphs and headings), extract pictures and table of contents.
2a A bit of theory. Get the table of objects.
First, a little theory. Here is an example of a PDF file opened in Notepad.
')
Even with the unarmed eye, you can see that in addition to the strange krakozyablikov there is also a meaningful text in the file and this is good news. It is he who will help us in everything to understand.
As it turned out (and helped ISO 3200-1 here), the PDF has approximately the following structure:
The first line describes the PDF version . The second is a mysterious line in which I did not understand as superfluous. Although I admit that it is hidden the true essence of our universe and in general. Next is the description of the objects.
Objects are universal structures that describe all the data stored in a PDF and their logical connections. Each object consists of the “NM obj” type header (without quotes), where N is the object number, M is its version (for the sake of honor, I note that I never met an object where M! = 0). After the title of the object are its properties in the << >>. And finally, there is an optional data stream surrounded by a pair of stream, endstream. All parts of the object are separated by line breaks. These elements I will discuss in more detail later. For now, let's move on from the objects to the final part of the PDF document.
cross-reference table - A certain table that stores the addresses of each object in the file. This table has approximately the following structure:
The first line is the xref keyword. The second is two numbers, which designate from what for what objects are described in it. Then the table itself goes directly. Each line of the form 0000000032 65535 f describes an object of the corresponding number. Do not forget that in some tables the numbering will not begin with the first object, but with the one that is described in the line after the keyword xref. The first group of digits: 10 digits (the value is supplemented with insignificant zeros on the left) denoting the address in the file from which the object begins.
UPD: Thank you, pleax for pointing out the flaws. Corrected.
The second group: 5 digits not more than 65535 (int) denoting the revision number of the object. and the last character is either n (for the objects used) or f for free-objects (which have been deleted). When an object is deleted, its edition number (generation) is incremented by 1, and the flag (n / f) is set to f. In addition, the revision number can be set to 65535. Such an object is considered free and is never used again. Read more on page 40 of the PDF documentation.
Immediately after the table comes the trailer keyword, after which you can find the properties of the table. We will be interested in only one: / Prev 321249. Here, the number indicates the address in the file with which the preceding table begins. Accordingly, the very first table does not have such a property.
After the properties of the table, you can find another keyword startxref, after which a number denoting the address of the beginning of this table.
This knowledge will be enough for us to unload the table of all PDF objects, so that in the future we will not have to load the entire PDF into memory. And now we take a beer and practice.
2b. Theory in practice. Get the table of objects.
Nuss. Let's get the bat. Here are some of my govnokoda:
private function get_ref_table(){ $currentString = ''; $matches=NULL; $tableLength = 0; $lastTable = false; /* 32 , , */ fseek($this->filePointer, -32, SEEK_END); $nextTableLink=''; /* -32 , startxref */ while(preg_match('/startxref/', $nextTableLink)!=1 && $nextTableLink!==false){ $nextTableLink = fgets($this->filePointer); } $nextTableLink = fgets($this->filePointer); while($lastTable!== true){ // fseek($this->filePointer, $nextTableLink, SEEK_SET); // fgets($this->filePointer); $currentString = fgets($this->filePointer); // preg_match('/(\d+)\x20(\d+)/', $currentString, $matches); $tableLength = $matches[2]; $startIndex = $matches[1]; // for($i=0; $i<$tableLength; $i++){ $currentString = fgets($this->filePointer); preg_match('/(\d+)\x20\d+\x20\x6E/', $currentString, $matches); if(isset($matches[1])) $this->RefTable[$startIndex+$i]=$matches[1]; } fgets($this->filePointer); $currentString = fgets($this->filePointer); // , // if(preg_match('/\x2FPrev\x20(\d+)/', $currentString, $matches)==1) $nextTableLink = $matches[1]+0; else $lastTable = true; } // asort($this->RefTable, SORT_NUMERIC); reset($this->RefTable); $pointerKey=NULL; // // , // . foreach($this->RefTable as $key => $value){ if($pointerKey!=NULL) $this->RefTableNext[$pointerKey]=&$this->RefTable[$key]; $pointerKey = $key; } if($pointerKey!=NULL) $this->RefTableNext[$pointerKey]= $nextTableLink; } I think that in general, the code is clear: Find the address of the last table, save its values into an array, read the address of the trace of the table. We create the last table only because in PHP it is difficult to know the next element of the array. And in my case it was easier for me to store an extra table than to run through the entire array every time in search of the right element.
Now that we have an array of RefTable ['object number'] = 'Address of the object' We can use a simple function to read the files item by object. For example:
public function get_obj_by_key($key){ fseek($this->filePointer, $this->RefTable[$key]); return fread($this->filePointer, $this->RefTableNext[$key]-$this->RefTable[$key]); } 3a Some more theory. Get the page table.
Let's return to our objects, and more precisely to their properties. There are 9 basic data types in PDF:
Boolean - True, False;
Numeric - int (623, +17, -98), real (34.5, -3.62)
LiteralString - Character set in parentheses (abcd)
Hexademical Strings - <4E6F7620> A string of hexadecimal values.
Name - / Prev character set field slash
Array - [/ name 1 / name1 / name2] an array of objects of arbitrary type
Dictionary - A key-value type set, where the key is always an object of type Name (/ Prev), and a value is an object of any type, including other dictionaries. Dictionaries are always surrounded by << >>
Stream - Some data that can be encoded anyway.
NULL - Speaks for itself
See the 14th documentation page for more details.
So the properties of the object are stored in dictionaries (Dictionary). And first of all we will be interested in the property / Type in which, oddly enough, is the type of the object. To begin, we will find two objects: / Type / Catalog and / Type / Pages in the first, in the form of properties, references to objects with service information and data structures are stored, including to / Pages 2 0 R (This is for example). Here you can see that the property / Pages matches the object number 2 0 R of the type / Type / Pages.
The object / Type / Pages, which we find under number 2 in our table, is valuable in that it contains an array of / Kids [3 0 R 29 0 R] with numbers in the properties. The objects that we find in this array can be either another node / Type / Pages with its / Kids, or the objects we are looking for / Type / Page I mean pages.
And here comes the time for a bottle of cold dark.
3b. Let's go back to the code. Get the page table.
Here is the function that will receive
private function get_page_table(){ $currentObj = ''; reset($this->RefTable); $key = key($this->RefTable); $matches = NULL; $nextPage = NULL; $pages = array(); // , /Type/Catalog while((preg_match('/\x2F\x54\x79\x70\x65\x2F\x43\x61\x74\x61\x6C\x6F\x67/',$currentObj) != 1) || ($currentObj === false) ){ $currentObj = $this->get_obj_by_key($key); next($this->RefTable); $key = key($this->RefTable); } // /Pages N 0 R preg_match('/\x2F\x50\x61\x67\x65\x73\x20(\d+)\x20\x30\x20\x52/', $currentObj, $matches); $currentObj = $this->get_obj_by_key($matches[1]); preg_match('/\x2FKids\[(.*)\]/',$currentObj, $kids); // preg_match_all('/\s?(\d+)\s\d+\sR/',$kids[1], $matches); foreach($matches[1] as $value){ $pages[] = $value; } foreach($pages as $key => $value){ if(isset($this->RefTable[$value])){ $page=$this->get_obj_by_key($value); // – , if(preg_match('/\/Type\/Page\W/',$page) == 1){ $this->pageTable[] = $value; } // $this->pageTable = array_merge($this->pageTable,$this->getChildren($value)); } } return true; } Next is an auxiliary function that recursively helps us in searching for kid pages.
private function getChildren($Obj){ $pages = array(); $pagesArr = array(); $currentObj = $this->get_obj_by_key($Obj); preg_match('/\x2FKids\[(.*)\]/',$currentObj, $kids); if(isset($kids[1])){ if(preg_match_all('/\s?(\d+)\s\d+\sR/',$kids[1], $matches) > 0){ foreach($matches[1] as $value){ $pages[] = $value; } foreach($pages as $key => $value){ if(isset($this->RefTable[$value])){ $page=$this->get_obj_by_key($value); if(preg_match('/\/Type\/Page\W/',$page) == 1){ $pagesArr[] = $value; } $pagesArr = array_merge($pagesArr,$this->getChildren($value)); } } return $pagesArr; } else return array(); } return array(); } Well, what happened is a miracle: we have the table number Object-> the address of the object and there is the table NumberPage-> Number of the object. The case is left to go: Get the contents of the pages and break it into logical structures.
4a. The theory is back. We retrieve data from streams.
Sometimes after the objects you can find a bunch of obscure characters, and sometimes they can be found in the object to which you can find links in the property / Resources of the object. This is coded data. In the dictionary of such objects you will find the / Filter property to which both a single value and an array can be assigned (Important! It may be that the data after the object will not be encrypted. In this case, the / Filter properties will not be present. And even the zhoshkolnik will be able to read the stream ). A list of all possible filters can be found in the documentation on page 22, however, I’ll stop at one. / Filter / FlateDecode is the most common filter and in 99% of cases only it is enough. FlateDecode is nothing more than a regular gzip and all we need is gzuncompress ($ stream). There is one thing here. According to the FlateDecode standard, the first 4 bits of the data are overhead and are not interpreted, but in some PDFs these bits are missing and gzuncompress () data error may occur. I can rejoice you: one well done wrote a patch for us. Go here and read
And so it means that we have done such good work and have extracted data from the stream, and there:
And there is a text. We are still interested in the following lines:
A string that ends in BT. It may well be that the line will only BT
A string that ends with Tf. It describes the fonts used in the text block.
String ending in TJ. In it we will find the text itself (almost).
Well, it will all end ET
Let us examine all the details on the example
/ P << / MCID 0 >> BDC BT
/ F1 13.56 Tf
1 0 0 1 245.69 760.8 Tm
0 g
0 G
[<0245> -2 <0278> 4 <025B> 5 <0268> -3 <025C> 12 <0276> -3 <000F0003> 4 <025E> 5 <025F0265> 5 <0276> -3 <026E0262> 6 < 0267> 4 <00030262> 6 <00030266> 7 <0268> -3 <026A> -3 <025F0011>] TJ
ET
BT and ET are nothing but begin of text and end of text. Before BT there is a marker that actually helps to highlight the logical structures in the text (Paragraphs and headings) In this article I will not elaborate on this. For the time being, you can take each such << / MCID 0 >>, << / MCID 1 >> block as the beginning of a paragraph or read the Logical Structure section in the documentation on page 556. If anyone is interested, I can add an article.
In the font line we are interested in / F1 and squiggles. / F1 - the name of the font that we need to decode the text (yes, yes, our torment has not yet ended) and obtain text styles
Before TJ in [] is the desired text. Now we can get lucky and we will see the text. Plain text is always in parentheses. If we are unlucky, and so it will be, then we will find groups of numbers in the triangular brackets. Every 4 digits is one character, the hexadecimal value of which can be found in the correspondence table, and the correspondence table in the font object that we found earlier, the hare in the duck, and the duck in the egg ... Oops, I suffered ...
Finding a table of character codes is not difficult: the page that we decoded has the / Resources property, and << / Font << / F1 5 0 R / F2 10 0 R / F3 12 0 R in it… .......... What do you already do we guessed it: go to the object number of the corresponding font, and in that object (this is not a joke) there is a property / ToUnicode 98 0 R There you will find the table. What to do with her well described in Habré . Who is not enough - you can look at the source, which I will attach.
For now. This was just a general overview. If there is interest, I will tell you in more detail how to extract images, a catalog, tables, styles, other buns. If you have questions, you are welcome. And yes, I ask you not to troll the code very much, it does not pretend to read it, only to explain the whole in general.
And lastly A bit of code for a common understanding.
Source: https://habr.com/ru/post/140847/
All Articles