The system of monitoring opinions using pointwise mutual information
Hello.
If you are engaged in DataMining, analyzing texts for identifying opinions, or you are just interested in statistical models for evaluating the emotional coloration of sentences - this article may be interesting.
Further, in order not to waste the time of a potential reader on a pile of theory and reasoning, the results are immediately brief.
The implemented approach works with approximately 55% accuracy in three classes: negative, neutral, positive. As Wikipedia says, 70% accuracy is approximately equal to the accuracy of human judgments on average (due to the subjectivity of each interpretation).
It should be noted that there are quite a few utilities with an accuracy higher than that obtained by me, but the described approach can be rather simply improved (to be described below) and we end up with 65-70%. If after all of the above, you still have a desire to read - welcome under cat.
To determine the emotional color of the sentence (SO - sentiment orientation), it is necessary to understand what it is about. This is logical. But how to explain to the car what is good and what is bad?
The first option, immediately appearing on the mind, is the sum of the number of bad / good words multiplied by the weight of each. The so-called “bag of words” approach. A surprisingly simple and fast algorithm, combined with rule- based preprocessing , yielding good results (up to 60–80% accuracy depending on the case ). In essence, this approach is an example of a unigram model , which means that in the most naive case, the sentences “This product rather than bad” and “This product rather than good” will have the same SO. This problem can be solved by moving from a unigram to a multinomial model. It should also be noted that it is necessary to have a solid constantly updated dictionary containing bad and good terms + their weight, which can be specific depending on the data.
An example of the simplest multinomial model is the naive Bayes method . On Habré there are several articles devoted to him, in particular this .
The advantage of the multinomial model over the unigram model is that we can take into account the context in which a particular utterance was uttered. This solves the problem with the sentences described above, but introduces a new constraint: if the selected n-gram is missing from the training set, then the SO on the test data will be 0. This problem has always been and will be. It can be solved in two ways: by increasing the size of the training sample (not forgetting that you can simultaneously capture the effect of retraining), or by using smoothing (for example, Laplace or Good-Turing).
')
Finally, we smoothly approached the idea of PMI.
Along with the Bayes formula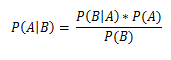 , we introduce the concept
, we introduce the concept

PMI - pointwise mutual information, point-to-point mutual information.
in the above formula, A and B are words / bigrams / n-grams, P (A), P (B) are a priori probabilities of occurrence of the term A and B, respectively, in the training set (the ratio of the number of occurrences to the total number of words in the body), P (A near B) - the probability of the term A to meet together / next to the term B; “Near” can be configured manually; by default, the distance is 10 terms left and right; the base of the logarithm does not matter, for simplicity we take it equal to 2.
A positive sign of the logarithm will mean positive color A compared to B, negative - negative.
To find neutral reviews, you can take some kind of sliding window (in this work, the segment [-0.154, 0.154] is responsible for this). The window can be either constant or floating depending on the data (shown below).
From the above, we can come to the following statements:
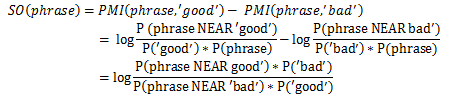
Indeed, to determine to which class the statements “good weather”, “go fast” belong, it is enough to check in the training set how often “good weather” and “go fast” are found next to the known (set by a person depending on the data model and test sample ) good and bad words and set the difference.
Let's go a little further and instead of comparing with the one pivot word from the negative and positive side, we will use a set of obviously good and bad words (here, for example, the following words were used:
Positive: good, nice, excellent, perfect, correct, super
Negative : bad, nasty, poor, terrible, wrong, awful
Accordingly, the final formula

So, with SO counting figured out, but how to choose suitable candidates?
For example, we have a sentence “Today is a wonderful morning, it would be good to go to the lake.”
It is logical to assume that the adjectives and adverbs add the emotional color to the sentence. Therefore, in order to take advantage of this, we will construct a finite automaton, which, according to given patterns of parts of speech, will be selected from the proposal of candidates for the evaluation of SO. It is not difficult to guess that the proposals will be considered a positive review if the sum SO of all candidates is> 0.154.
The following patterns were used in this work:

In this case, the candidates will be:
1. wonderful morning
2. good to go
It remains only to put everything together and test.
Here you will find Java sources. There is little beauty - it was written just to try and decide whether it will be used further.
Housing: Amazon Product Review Data (> 5.8 million reviews) liu2.cs.uic.edu/data
With the help of Lucene, the inverted index was built on this case, and the search was made by it.
In the absence of data in the index, Google search engines (api) and Yahoo! (with their operator around and near respectively). But, unfortunately, due to the speed of work and the inaccuracy of the results (according to high-frequency queries, search engines give an approximate value of the number of results), the solution is not perfect.
To determine the parts of speech and tokenization, the OpenNLP library was used.
Based on the foregoing, the most preferred vectors of improvements are:
1. Building a more complete tree of analysis of parts of speech to filter candidates
2. Using a larger binder as a training set.
3. If possible, use a learning corps from the same socialmedia as the test sample
4. Formation of reference words (good | bad) depending on the source of data and subject
5. Introducing negation into the template parse tree
6. Definition of sarcasm
In general, a system based on PMI can compete with systems based on the “bag of words” principle, but in an ideal implementation these two systems should complement each other: in the absence of data in the training set, the system of counting specific words should come into play.
1. Introduction to information retrieval. K. Manning, P. Raghavan, H. Schütze
2. Foundations of statistical natural language processing. C. Manning, H. Schutze
3. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. Peter D. Turney
If you are engaged in DataMining, analyzing texts for identifying opinions, or you are just interested in statistical models for evaluating the emotional coloration of sentences - this article may be interesting.
Further, in order not to waste the time of a potential reader on a pile of theory and reasoning, the results are immediately brief.
The implemented approach works with approximately 55% accuracy in three classes: negative, neutral, positive. As Wikipedia says, 70% accuracy is approximately equal to the accuracy of human judgments on average (due to the subjectivity of each interpretation).
It should be noted that there are quite a few utilities with an accuracy higher than that obtained by me, but the described approach can be rather simply improved (to be described below) and we end up with 65-70%. If after all of the above, you still have a desire to read - welcome under cat.
Brief description of the principle
To determine the emotional color of the sentence (SO - sentiment orientation), it is necessary to understand what it is about. This is logical. But how to explain to the car what is good and what is bad?
The first option, immediately appearing on the mind, is the sum of the number of bad / good words multiplied by the weight of each. The so-called “bag of words” approach. A surprisingly simple and fast algorithm, combined with rule- based preprocessing , yielding good results (up to 60–80% accuracy depending on the case ). In essence, this approach is an example of a unigram model , which means that in the most naive case, the sentences “This product rather than bad” and “This product rather than good” will have the same SO. This problem can be solved by moving from a unigram to a multinomial model. It should also be noted that it is necessary to have a solid constantly updated dictionary containing bad and good terms + their weight, which can be specific depending on the data.
An example of the simplest multinomial model is the naive Bayes method . On Habré there are several articles devoted to him, in particular this .
The advantage of the multinomial model over the unigram model is that we can take into account the context in which a particular utterance was uttered. This solves the problem with the sentences described above, but introduces a new constraint: if the selected n-gram is missing from the training set, then the SO on the test data will be 0. This problem has always been and will be. It can be solved in two ways: by increasing the size of the training sample (not forgetting that you can simultaneously capture the effect of retraining), or by using smoothing (for example, Laplace or Good-Turing).
')
Finally, we smoothly approached the idea of PMI.
Along with the Bayes formula
, we introduce the conceptPMI - pointwise mutual information, point-to-point mutual information.
in the above formula, A and B are words / bigrams / n-grams, P (A), P (B) are a priori probabilities of occurrence of the term A and B, respectively, in the training set (the ratio of the number of occurrences to the total number of words in the body), P (A near B) - the probability of the term A to meet together / next to the term B; “Near” can be configured manually; by default, the distance is 10 terms left and right; the base of the logarithm does not matter, for simplicity we take it equal to 2.
A positive sign of the logarithm will mean positive color A compared to B, negative - negative.
To find neutral reviews, you can take some kind of sliding window (in this work, the segment [-0.154, 0.154] is responsible for this). The window can be either constant or floating depending on the data (shown below).
From the above, we can come to the following statements:
Indeed, to determine to which class the statements “good weather”, “go fast” belong, it is enough to check in the training set how often “good weather” and “go fast” are found next to the known (set by a person depending on the data model and test sample ) good and bad words and set the difference.
Let's go a little further and instead of comparing with the one pivot word from the negative and positive side, we will use a set of obviously good and bad words (here, for example, the following words were used:
Positive: good, nice, excellent, perfect, correct, super
Negative : bad, nasty, poor, terrible, wrong, awful
Accordingly, the final formula
So, with SO counting figured out, but how to choose suitable candidates?
For example, we have a sentence “Today is a wonderful morning, it would be good to go to the lake.”
It is logical to assume that the adjectives and adverbs add the emotional color to the sentence. Therefore, in order to take advantage of this, we will construct a finite automaton, which, according to given patterns of parts of speech, will be selected from the proposal of candidates for the evaluation of SO. It is not difficult to guess that the proposals will be considered a positive review if the sum SO of all candidates is> 0.154.
The following patterns were used in this work:
In this case, the candidates will be:
1. wonderful morning
2. good to go
It remains only to put everything together and test.
Implementation
Here you will find Java sources. There is little beauty - it was written just to try and decide whether it will be used further.
Housing: Amazon Product Review Data (> 5.8 million reviews) liu2.cs.uic.edu/data
With the help of Lucene, the inverted index was built on this case, and the search was made by it.
In the absence of data in the index, Google search engines (api) and Yahoo! (with their operator around and near respectively). But, unfortunately, due to the speed of work and the inaccuracy of the results (according to high-frequency queries, search engines give an approximate value of the number of results), the solution is not perfect.
To determine the parts of speech and tokenization, the OpenNLP library was used.
Which is better
Based on the foregoing, the most preferred vectors of improvements are:
1. Building a more complete tree of analysis of parts of speech to filter candidates
2. Using a larger binder as a training set.
3. If possible, use a learning corps from the same socialmedia as the test sample
4. Formation of reference words (good | bad) depending on the source of data and subject
5. Introducing negation into the template parse tree
6. Definition of sarcasm
findings
In general, a system based on PMI can compete with systems based on the “bag of words” principle, but in an ideal implementation these two systems should complement each other: in the absence of data in the training set, the system of counting specific words should come into play.
References:
1. Introduction to information retrieval. K. Manning, P. Raghavan, H. Schütze
2. Foundations of statistical natural language processing. C. Manning, H. Schutze
3. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. Peter D. Turney
Source: https://habr.com/ru/post/140739/
All Articles