Microsoft StreamInsight - real-time data stream processing
As I said, our company works a lot with real-time data processing tasks. Solving various problems, we came up with rather curious and interesting solutions, which sometimes no one wrote on Habré. We will tell you about one such interesting system today. It was made by Microsoft, it is called StreamInsight and is the implementation of the so-called Complex Event Processing pattern. About what it is and why it is needed, we will tell you in detail inside.

A long time ago, in the 1989th year, when the grass was greener, and in IT everything was somewhat simpler, people were just starting to think that it would be nice for databases not only to perform writing and reading requests, but also somehow difficult respond to incoming data. It all started with the so-called Active database systems , which could use the given sets of intrusions under certain predefined conditions. Those. in fact, it was the launch of the built-in procedures for an external trigger. In the 90s there were Data Stream Management Systems , who developed this idea. They already knew how to work with continuous streams of incoming data. It could already be not rare requests, but an honest stream of real-time data. At about the same time, people thought that sometimes the data coming into the database are not events, but rather external manifestations of these events: the readings of sensors registering them, notifications and notifications. Such systems began to be called Complex Event Processing .
Analyzing incoming data, such systems could both detect events (determining the fact of their occurrence, based on external data and embedded internal logic), and calculate analytical values (for example, counting the average number of events occurring over a certain period of time). Thus, the use of these systems implies that their internal logic must be aware of what “real” events are outside, and analyze the incoming data with a “target” on them.
')
The project StreamInsight , which originated in the depths of Microsoft Research, was originally the implementation of this particular pattern. On the one hand, there is a whole class of tasks, operating with data streams that require a different (compared to relational databases) approach to the solution. On the other hand, lately, prices for data storage devices have fallen by orders of magnitude, and companies retain a huge amount of data on all sorts of aspects of system operation. Moreover, if expressed in business language, the value of this data sometimes falls rapidly in time: if you do not have time to react to an event, you lose your profit.
StreamInsight is a platform for building applications that work with streaming data. Most processing takes place in RAM, which allows for high throughput and low latency. The heart of this platform is the engine in which the so-called revolve. Standing Queues, written in declarative LINQ. Any incoming event immediately goes to processing in these queues.
The system allows you to do everything that the “right” CEP should do and more. For example:
It is seen that the possibilities and applications of this system are wider than the academic CEP. At the same time, the list of commercial applications is also quite large: web analytics, logistics and operational analysis, agoritmic trading, detection of cases of money laundering, fraud with payment cards, monitoring of business activity and security.
A more complete list of use scenes can be found here.
Here, for example, is an interesting use case in which SI minits patterns using data from stored logs, and then it detects these patterns in a real-time data stream:

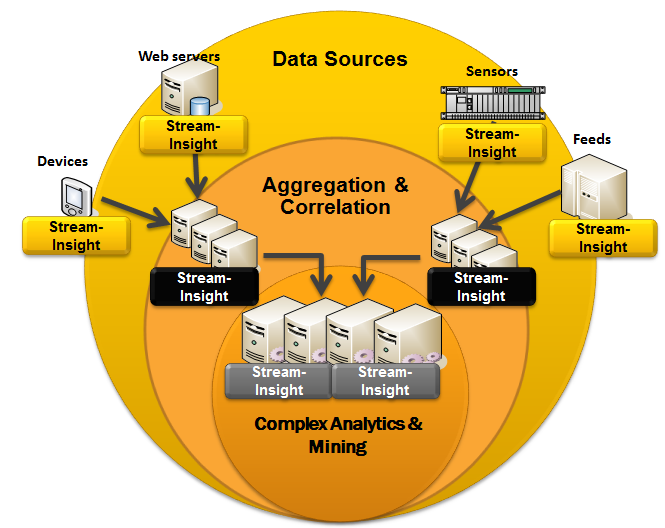
Here is another beautiful MSDN picture that describes the SI device inside:

As already mentioned, the basis of the engine are Standing Queues, constantly spinning inside the engine. Another basic component are adapters: input and output. They allow you to connect SI with the outside world and use all sorts of data sources. Some of the most popular adapters come with the platform, the rest will have to be written in C #.
You can read about how the Queues inside work in full detail in the following document: Hitchhiker's Guide to theGalaxy StreamInsayt . I will try to describe the overall picture necessary for understanding.
Firstly, all events (even atomic events) inside the StreamInsight engine have a certain duration, event data and payload (meaningful load). And the majority of operands working with these events, consider the so-called Event Windows - time windows, within which operations with data occur.
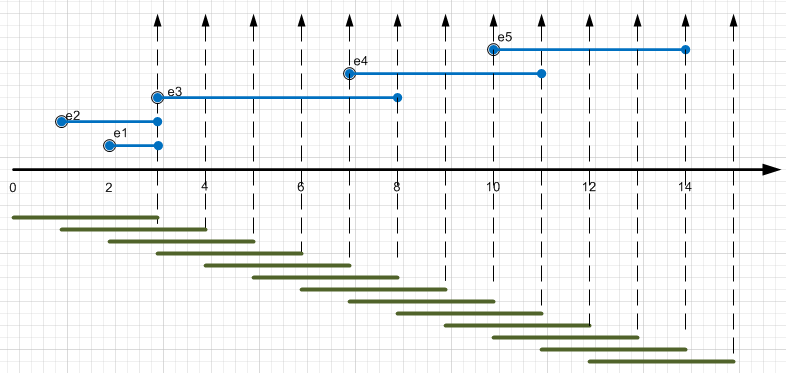
On this platform (using LINQ) you can do the following:
An important point is that the output from one Queue can be sent to another Queue, which allows you to manage data processing more flexibly (for example, realize publish / subscribe)
With all this, StreamInsight is not a big and cumbersome system that requires a developed infrastructure. It can be used directly in your application, embedded in the form of dll. In this case, the limit on performance will be only the amount of allocated RAM. You can also start the StreamInsight engine separately, in stand-alone mode. In this way, you can make systems in which the product is applied in different places: near sources of information for filtering, and in a processing center when extracting the necessary data from streams.
But with the licensing and cost is not so good. StreamInsight is sold only as part of the MS SQL server, which raises some questions. This is despite the fact that SI does not depend on the Database Engine and the relationship between these products is rather conditional. SI can be downloaded separately from MS SQL Server, but you still need an activation key from the main product. There are 2 editions: Standard and Premium. Read more about it here . There is a frank problem of marketers: the guys from the technical department came up with an excellent technology, and they couldn’t think of how to sell it well. As a result, in order to implement the image above, you will need to buy a fair amount of MS SQL licenses. And also note that if the license is lower than Enterprise, then you will be artificially limited to the performance of the StreamInsight engine. One can only hope that after some time the situation will change and there will be an opportunity to use this technology for proportional money.
And of course, for some scenarios, there is a need to use such analytics in SaaS mode. Microsoft has tried to make the corresponding service in its Azure. True, the product is still in a closed beta, and most of the information is closed by the NDA. So here I will tell only what I managed to learn from open sources (the course PluralSight and so on.)
First of all, there is hope that in this incarnation StreamInsight can normally buy for reasonable money: nevertheless, this piece does not drag a complete database.
Secondly, Austin itself cares about scaling in terms of processing incoming data: you do not need to think here about horizontal scaling. The rest of the structure remains the same: input adapters, standing queries, output adapters.
Thirdly, the main scenario is the following: there is a cloud of data, we crunch it with them, pull out the necessary knowledge and put it into a persistent storage. Thus, the input adapter is the REST endpoint with the scaling load balancer behind it, and the output adapters can add the processing results directly to Azure Storage or Azure SQL.
The scope of this service is consonant with the use of the cloud in general:
As I have already noted, most of the materials are currently under the NDA, and I cannot find any useful pictures without the Microsoft Confidential mark. :)
General overview in the video:
Microsoft StreamInsight: extracting knowledge from real-time relational data streams
A magnificent document describing the internal structure and various aspects of programming under StreamInsight.
A Hitchhiker's Guide to StreamInsight Queries
Another great source of information: a paid video course with demos of virtually all interesting places:
Pluralsight course
Official developer blog:
Official blog of the development team of StreamInsight.
Introduction
A long time ago, in the 1989th year, when the grass was greener, and in IT everything was somewhat simpler, people were just starting to think that it would be nice for databases not only to perform writing and reading requests, but also somehow difficult respond to incoming data. It all started with the so-called Active database systems , which could use the given sets of intrusions under certain predefined conditions. Those. in fact, it was the launch of the built-in procedures for an external trigger. In the 90s there were Data Stream Management Systems , who developed this idea. They already knew how to work with continuous streams of incoming data. It could already be not rare requests, but an honest stream of real-time data. At about the same time, people thought that sometimes the data coming into the database are not events, but rather external manifestations of these events: the readings of sensors registering them, notifications and notifications. Such systems began to be called Complex Event Processing .
Analyzing incoming data, such systems could both detect events (determining the fact of their occurrence, based on external data and embedded internal logic), and calculate analytical values (for example, counting the average number of events occurring over a certain period of time). Thus, the use of these systems implies that their internal logic must be aware of what “real” events are outside, and analyze the incoming data with a “target” on them.
')
Streaminsight
The project StreamInsight , which originated in the depths of Microsoft Research, was originally the implementation of this particular pattern. On the one hand, there is a whole class of tasks, operating with data streams that require a different (compared to relational databases) approach to the solution. On the other hand, lately, prices for data storage devices have fallen by orders of magnitude, and companies retain a huge amount of data on all sorts of aspects of system operation. Moreover, if expressed in business language, the value of this data sometimes falls rapidly in time: if you do not have time to react to an event, you lose your profit.
StreamInsight is a platform for building applications that work with streaming data. Most processing takes place in RAM, which allows for high throughput and low latency. The heart of this platform is the engine in which the so-called revolve. Standing Queues, written in declarative LINQ. Any incoming event immediately goes to processing in these queues.
The system allows you to do everything that the “right” CEP should do and more. For example:
- Read all possible integral values
- Modify and filter the data stream, remove duplicate events
- Detect complex event patterns
- Track the “absence” of an external event
- With the latest versions, you can implement the publish / subscribe newsletter
It is seen that the possibilities and applications of this system are wider than the academic CEP. At the same time, the list of commercial applications is also quite large: web analytics, logistics and operational analysis, agoritmic trading, detection of cases of money laundering, fraud with payment cards, monitoring of business activity and security.
A more complete list of use scenes can be found here.
Here, for example, is an interesting use case in which SI minits patterns using data from stored logs, and then it detects these patterns in a real-time data stream:
Architectural Details
Here is another beautiful MSDN picture that describes the SI device inside:
As already mentioned, the basis of the engine are Standing Queues, constantly spinning inside the engine. Another basic component are adapters: input and output. They allow you to connect SI with the outside world and use all sorts of data sources. Some of the most popular adapters come with the platform, the rest will have to be written in C #.
You can read about how the Queues inside work in full detail in the following document: Hitchhiker's Guide to the
Firstly, all events (even atomic events) inside the StreamInsight engine have a certain duration, event data and payload (meaningful load). And the majority of operands working with these events, consider the so-called Event Windows - time windows, within which operations with data occur.
On this platform (using LINQ) you can do the following:
- Event selections (filter)
- Calculations on payload (project)
- Join correlation
- Grouping and splitting threads (group and apply)
- Aggregation (sum, count, ...) inside time windows
- Ranked (topK) inside time windows
An important point is that the output from one Queue can be sent to another Queue, which allows you to manage data processing more flexibly (for example, realize publish / subscribe)
Deployment and cost
With all this, StreamInsight is not a big and cumbersome system that requires a developed infrastructure. It can be used directly in your application, embedded in the form of dll. In this case, the limit on performance will be only the amount of allocated RAM. You can also start the StreamInsight engine separately, in stand-alone mode. In this way, you can make systems in which the product is applied in different places: near sources of information for filtering, and in a processing center when extracting the necessary data from streams.
But with the licensing and cost is not so good. StreamInsight is sold only as part of the MS SQL server, which raises some questions. This is despite the fact that SI does not depend on the Database Engine and the relationship between these products is rather conditional. SI can be downloaded separately from MS SQL Server, but you still need an activation key from the main product. There are 2 editions: Standard and Premium. Read more about it here . There is a frank problem of marketers: the guys from the technical department came up with an excellent technology, and they couldn’t think of how to sell it well. As a result, in order to implement the image above, you will need to buy a fair amount of MS SQL licenses. And also note that if the license is lower than Enterprise, then you will be artificially limited to the performance of the StreamInsight engine. One can only hope that after some time the situation will change and there will be an opportunity to use this technology for proportional money.
Austin - StreamInsight in the Cloud
And of course, for some scenarios, there is a need to use such analytics in SaaS mode. Microsoft has tried to make the corresponding service in its Azure. True, the product is still in a closed beta, and most of the information is closed by the NDA. So here I will tell only what I managed to learn from open sources (the course PluralSight and so on.)
First of all, there is hope that in this incarnation StreamInsight can normally buy for reasonable money: nevertheless, this piece does not drag a complete database.
Secondly, Austin itself cares about scaling in terms of processing incoming data: you do not need to think here about horizontal scaling. The rest of the structure remains the same: input adapters, standing queries, output adapters.
Thirdly, the main scenario is the following: there is a cloud of data, we crunch it with them, pull out the necessary knowledge and put it into a persistent storage. Thus, the input adapter is the REST endpoint with the scaling load balancer behind it, and the output adapters can add the processing results directly to Azure Storage or Azure SQL.
The scope of this service is consonant with the use of the cloud in general:
- Data sources are geographically distributed or in the cloud.
- Elastic, easily scaleable power required
- Irregular and peak processing of large pieces of data
As I have already noted, most of the materials are currently under the NDA, and I cannot find any useful pictures without the Microsoft Confidential mark. :)
Literature:
General overview in the video:
Microsoft StreamInsight: extracting knowledge from real-time relational data streams
A magnificent document describing the internal structure and various aspects of programming under StreamInsight.
A Hitchhiker's Guide to StreamInsight Queries
Another great source of information: a paid video course with demos of virtually all interesting places:
Pluralsight course
Official developer blog:
Official blog of the development team of StreamInsight.
Source: https://habr.com/ru/post/140590/
All Articles