New tools and methods to optimize performance and fault tolerance on the example of MS SQL 2012 (RC0): Denali

Covering them all in one material is quite difficult, so I’ll dwell only on two of them that seemed most interesting - they are associated with increased performance and fault tolerance. They were considered on the example of a release candidate, but I do not think that in the final release something will change significantly.
Practically all the MS SQL functionality described in this article related to server performance is aimed at optimizing read operations. To effectively implement some of the new functionality, you will need to re-create the relational database and data presentation forms. It will also require modification of the software that works with these databases.
')
Often, the data processing system is located within the same data center, which is not always logical from the point of view of common sense, because a data center failure is very likely. In this part of the article, a geographically dispersed data processing environment will be considered, albeit emulated in poster conditions on a virtual farm of the following type:
One for all and all for one: AlwaysOn & Availability group
As everyone knows, a high-performance cluster is a hand-made thing and, therefore, expensive. Many would like to feel it without damage to the wallet. A similar solution first appeared for the Exchange Server in the form of Database Availability Group, and then was adapted to the needs of database servers.
So what is it? The AlwaysOn function (available, by the way, only in the Enterprise Edition) is designed to ensure the resiliency of databases. It is the database of baths, and not the instances in which these databases operate. This technology works by replicating the database between servers, more precisely, the transaction log.
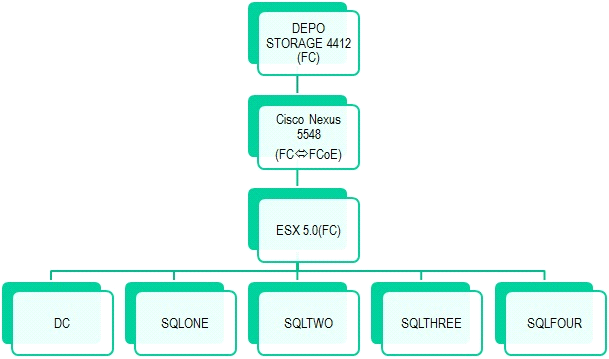
Consider the process of modeling a fault-tolerant group of geographically distributed servers. We take 4 identical servers entered into the domain, under control of the external domain controller. To see how they will exchange data in an environment close to real, for two (SQLONE, SQLTWO) we set up the connection at a speed of 10 Gb, put SQLTHREE on the channel at 1 Gb, and SQLFOUR synchronizes over 3G (since this is a spherical horse in a vacuum , then we take a speed of 10 Mb). All of them are included in the virtual cloud (ESX 5.0), created on the basis of the DEPO Storm 5302 server (FCoE) and the LSI 2600 (FC) storage, connected via Cisco Nexus 5548.
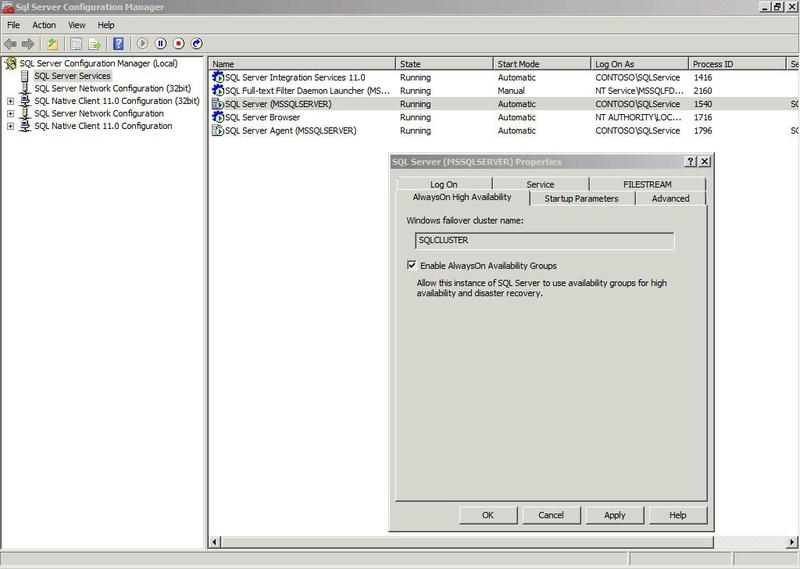
Having a group of MSSQL servers united in a failover cluster (we can do without quorum, Node Majority will suffice), we enable the option 'AlwaysOn Avaibility Groups' on each of them.
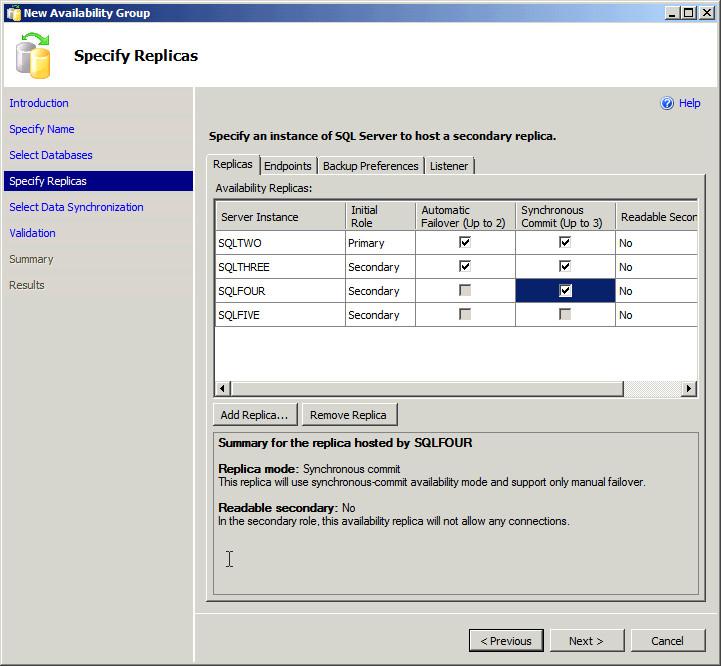
We select the future fault-tolerant database and switch to the Full recovery model, since replication is carried out by, as already mentioned, spreading the transaction log to the partner servers. We create on the basis of this database the Availability Group, to which we assign spare placement sites with up to 3 Secondary servers.

Specify the scheme of work with these servers, they will all replicate to themselves the data of the selected database. Do not forget to create on all servers a group of logins for users of this database. One or two servers can support synchronous replication with the original data set. One of them must be Failover-ready, in order to have time to intercept customer service in case of problems with Primary. By default, Secondary do nothing and just eat electricity. If you tick 'Read Access Allow' normal Secondary, which is in synchronous replication mode, becomes Active Secondary or Readable Secondary.
It looks like this:
“And what is the use of this parasite for us?” - you ask. First, it can serve read requests. Especially if an application connecting to an accessibility group does this solely for the purpose of reading data (Read Only), that is, the connection initialization string has the 'Application Intent = readonly' parameter.
Secondly, for databases that are in the Availability Group, there is a great option 'Use secondary for backup'. Thus, even if the databases have grown to such volumes that the backup takes 24 hours, you can safely do it from the data replica to the Secondary, without trying to cram the office day and server maintenance window in one day. This is especially convenient for database servers with 24/7 operation.
In general, with careful editing of applications working with the database, it is possible to ensure that all read operations will be performed from active Secondary, and write operations will be concentrated on Primary.
There is also an option to assign a dedicated “listener” (listener) so that applications that work with the database can be accessed immediately at the right address:
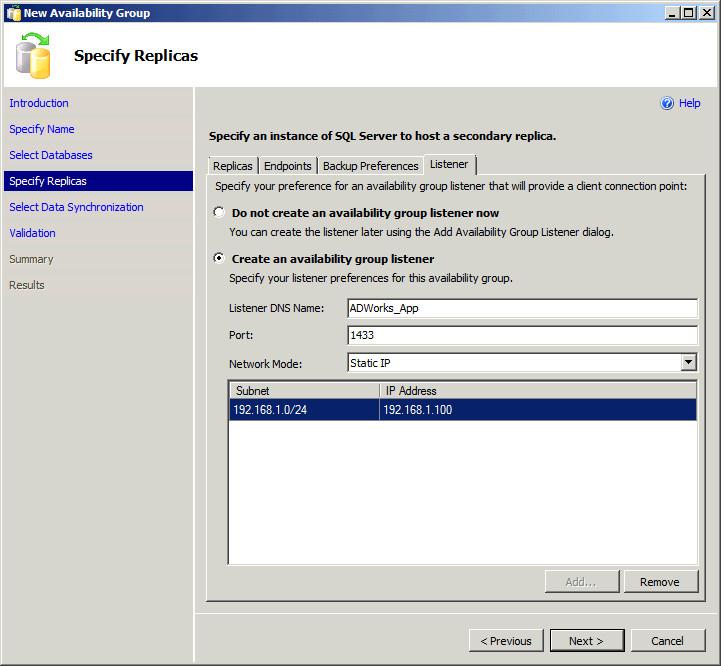
Disadvantages of this scheme, of course, there is, first of all, this price. On the other hand, we get the scheme of work when one server writes, two read, the fourth loafs and looks after its copy. Given that the writer with the first reader may be in Moscow, the second reader in St. Petersburg or London, and the “slacker” will sit in Vladivostok or Beijing. This approach allows you to reduce the load on the main server for read operations, unloading it to more efficiently perform write operations, which is more efficient than a classic failover cluster.
7 vertically and 4 horizontally - Columnstore index
Another option to optimize the work with the database is the so-called Columnar DBMS, which many probably have heard about. Their main difference from the classic Rowbased is the internal presentation of the data. Suppose we have a table of the following form:

The classic Rowbased (string) database stores this data in the form of:

This is useful in cases where we often add rows to the database completely, but it becomes very difficult to make selective selections, for example, by first and last name, because for such a sample, you still need to read the entire table.
In the case of the “newfangled” (that is, invented back in the early 70s of the last century, but according to experts from Microsoft, the database that suddenly turned out to be needed right now) Columnar database is stored in the form of:

As it is easy to notice here, we see a completely reverse situation: in order to add a row, you need to modify each column, and therefore pull the database into RAM, sort through and stack it back. But to add a new column or change an existing one in one operation - just spit. Again, selective sampling becomes very convenient: we simply take the necessary columns of the original base and thus save space in the RAM.
An additional plus of the Columnar DB manifests itself with compression - since within a column data has a more uniform appearance than within a row, LZW compression algorithms give a much greater degree of compression of data on columns than on rows.
Columnstore index (CSI) gives us the opportunity to make a kind of hybrid Rowbased and Columnar from the table. In other words, it is possible to select columns in the classic Rowbased table for storage in a Columnar view.
This entails some limitations, the most unpleasant of which are:
- if the table defines a Columnstore index, the table cannot be modified. No UPDATE, INSERT, DELETE and MERGE. You can certainly make DROP -> INSERT -> CREATE, but the sediment remains unpleasant;
- There are restrictions on the types of columns in which you can use the Columnstore index (http://msdn.microsoft.com/en-us/library/gg492088 (v=sql.110).aspx#Described);
- Columnstore Index cannot be a key (both primary - PRIMARY, and external FOREIGN), cannot be unique and cannot be sorted by ASC & DESC (for the compression algorithm is responsible for sorting) and much more (http://msdn.microsoft.com/ en-us / library / gg492088 (v = sql.110) .aspx # Restrictions);
- also the Columnstore index is very demanding of RAM, in other words, if the column does not fit into the RAM as a whole, there will be no benefit.
But, of course, there are positive aspects of this solution:
- sampling (SELECT) in the Columnstore index fields is about 10 times faster than sampling from Rowbased;
- the same can be said about * JOIN.
“Is that all?” You ask. Yes that's all. We “only” have a win approximately ten times on the two most popular queries to the database. Then begins the work of the architect to bring the base to a decent view. Some of them we leave in Rowbased as often changing, others partially transform in the Columnstore, as static.
Or we approach more creatively. For example, there are open orders that are stored in Rowbased, and every midnight the global archive of processed orders is made in the table for the last month: DROP COLUMNSTORE INDEX, INSERT DATA INTO MONTH, CREATE COLUMNSTORE INDEX. And then, quickly checking both tables, cleans the common rows from the working base and everyone lives happily.
Another variant. There are incoming telemetry data that are homogeneous in nature. There is a table in which data is collected for a certain period of time, for example, an hour or a day. Then this table with the whole clear name 20120229 is converted into a column view according to the schedule, and the data begins to flow as early as 20120301. As a result, the information is neatly folded, compressed and available for real-time reading if necessary.
Conclusion
As stated at the beginning of the article, only the gain on reading operations is visible here. Write operations benefit only in the high availability group, due to the fact that the write server can be unloaded by delegating read operations to secondary servers. In general, the feature is very useful. Saves nerves and resources, improves performance. In general, this functionality can be safely put the top five with a minus. Minus for recovery model requirements.
In the case of column indices, we have a net loss by writing - you can’t enter data into such a table at all, but you can quickly read them from it. This imposes certain restrictions on the use of this feature. It turns out something like an American dragster: the speed is high, but only along a straight and level road, and since there are also limitations on the RAM, it is not very long.
Overall, the Release Candidate left a pleasant impression. A functional has appeared that allows us not to call MS SQL 2012 a product of the Enterprise level, and I congratulate all of us.
evans2094 ,
Systems Engineer DEPO Computers
Source: https://habr.com/ru/post/140481/
All Articles