Writing features and possible features of LR-generators
Introduction
Good day.
In the final part about writing your own LALR parser generator, I would like to describe the possible features and features. In addition, I will describe what I lacked in existing solutions and for what I started writing my bicycle.
In order to set the context, let me tell you that the grammar for analysis is ECMAScript, also known as JavaScript. The specific specification is ECMA-262, version 5.1 dated June 2011.
When I first encountered the difficulties of writing, I did not immediately rush to write compiler code. At first, I learned how large companies solved these problems: Mozilla and Google (Opera and IE source codes are not publicly available). As it turned out, they were not particularly steamed with the formalization of grammar and wrote the code as is, that is, as I warned to do in the first part. Example of if'a processing in v8 (Chrome JS engine):
IfStatement* Parser::ParseIfStatement(ZoneStringList* labels, bool* ok) { // IfStatement :: // 'if' '(' Expression ')' Statement ('else' Statement)? Expect(Token::IF, CHECK_OK); Expect(Token::LPAREN, CHECK_OK); Expression* condition = ParseExpression(true, CHECK_OK); Expect(Token::RPAREN, CHECK_OK); Statement* then_statement = ParseStatement(labels, CHECK_OK); Statement* else_statement = NULL; if (peek() == Token::ELSE) { Next(); else_statement = ParseStatement(labels, CHECK_OK); } else { else_statement = factory()->NewEmptyStatement(); } return factory()->NewIfStatement(condition, then_statement, else_statement); } ')
Why did they do that? There are several reasons:
- Speed of work Although the FSM is very fast, the “linear” performance is still faster.
- Flexibility. The fact that bison / ANTLR / boost :: spirit / proprietary development was not used indirectly made me think that everything is not so simple with this grammar and it’s not me who ran into restrictions.
- They are not language developers from scratch (as with Dart, for example), so it’s enough to write once and forget for a couple of years before new changes in the standard. It follows from this that changes in grammar are not carried out every day.
Of course, there are a number of disadvantages:
- 5-10 thousand lines of code just for parsing is a bit too much.
- Without specifications do not live. Since the code is very fragmented, it is very difficult to assemble the language scheme into the system from scratch only by source code.
- Error handling inflates the code, despite the tricky macros:
#define CHECK_OK ok); \ if (!*ok) return NULL; \ ((void)0
Parser / Generator Parser Requirements
Now you can go to those grammar pitfalls and my expectations. At once I will say that some of the items are fully implemented by third-party software. But in the sum there is no complete program, and there are points for which I have not found a solution.
Comments are helpful!
In my task I needed to save the text and position of the comments, rather than discard them. ANTLR and bison / flex can do it. The first is due to the multiplexing of the lexer, the second is due to the power of the flex. Since I have not started writing my lexer yet, I use flex. And solved this problem as follows:
/* [Comment] = [MultiLineComment] | [SingleLineComment] */ /* [MultiLineComment] */ /* start of multiline, grab whole comment, that's why i use yymore() */ "/*" { BEGIN(multilinecomment); yymore(); m_loc.setMore(true); } /* skip all comments chars except "*" */ <multilinecomment>[^*\n\r]* { yymore(); } /* skip all "*", that not followed by "/" */ <multilinecomment>"*"+[^*/\n\r]* { yymore(); } /* end of comment */ <multilinecomment>"*"+"/" { m_comments.push_back(CParser::Comment(yytext, m_loc.tokenLine(), m_loc.tokenCol())); m_loc.setMore(false); BEGIN(INITIAL); } /* [SingleLineComment] increment lineNo */ ("//"([^\r\n])*{LineTerminator})|("//"([^\r\n])*) { m_comments.push_back(CParser::Comment(yytext, m_loc.tokenLine(), m_loc.tokenCol())); m_loc.linc(); } There is nothing special here. We use the internal states of the lexer and yymore () which allows you to create a holistic lexeme of several rules.
Parser-controlled lexer modes
JS has a special form for specifying reg-exps. They can be written just like that in the source code, and the signal is "/". But at the same time it is also a sign of division. Accordingly, the stream of tokens is very different in these cases. Slash is interpreted as a division mark if the parser in this position allows you to see it. And as a sign of the beginning reg-exp - in all other cases:
// regexp'a /asd[^c]/i.match(s); // - a = b / c; That is, the parser should be able to check the box if the division operator can come at the moment. At the flex level, it is simply solved:
/* [RegularExpressionLiteral] it has more length then [DivPunctor] (at least 3 == "/X/" versus 2 == "/="), that's why it would be proceeded first, before [DivPunctor] */ "/"{RegularExpressionFirstChar}({RegularExpressionFirstChar}|"*")*"/"({IdentifierStart}|[0-9])* { if (m_mode != Mode::M_REGEXP) REJECT; yylval->assign(yytext, yyleng); return token::T_REGEXP; } /* [DivPunctuator]: "/" or "/=" */ "/" return token::T_DIV; "/=" return token::T_DIVAS; Since flex is a greedy lexer and tries to process as long as possible lexemes, first it will fall into the rule for regexps, and there, if the mode for division is set, it will go to the next rule.
Parser tree output
I would love to get exactly the parser tree as a result of the analysis. It is very convenient to work with him as part of my task. AST is also suitable, but alas, the only supporting this format ANTLR requires you to specify explicit rules for its construction on top of the grammar. No special action was required. Is that a small addition to the analyzer algorithm:
while (!accepted && !error) { ... switch (act.type) { ... case Action::ACTION_SHIFT: ... node.col = m_loc.tokenCol(); node.line = m_loc.tokenLine(); node.type = ParseNode::NODE_TERM; node.termVal = s; node.symb.term = tok; nodes.push(tree.create(node)); break; case Action::ACTION_REDUCE: ... node.type = ParseNode::NODE_NONTERM; node.symb.nonTerm = (Symbols::SymbolsType)act.reduce.nonTerm; CTree<ParseNode>::TreeNode * parent = tree.create(node); unsigned long ruleLen = act.reduce.ruleLength; while (ruleLen) { tree.add(parent, nodes.top(), true); nodes.pop(); ruleLen--; } nodes.push(parent); break; } } if (nodes.top()) tree.SetRoot(nodes.top()); Custom lookahead
In grammar you can find just such a thing.
ExpressionStatement = [lookahead ∉ {{, function}] Expression ; No, this is not a standard expect-a convolution symbol, which I mentioned in the previous part. This is the opposite of trying to filter the first character of the expression. That is, according to this rule, we should throw out unnecessary subsidiary products from Expression, which begin with the terminal "{". In this case, this is done in order to avoid a conflict between Block, which may look like "{}" and one of the generations just Expression: "{}" as setting an empty javascript Object. Similarly for “function”.
The solution can be made without parser magic, but only by correcting the grammar:
ExpressionStatement = ExpressionWithoutBracket ExpressionWithoutBracket = ... | AssignmentExpressionWithoutBracket | ... ... And so until we reach the rule that begins with the terminal "{", and we exclude these rules from the penultimate grammar. The problem is that there are about 20 intermediate steps. In addition, we multiply this by 2 (also “function”!) And then by 2 because this technique is used for the same rule but in a different situation (2 lines - Expression and ExpressionNoIn). No, it does not please me at all.Technically, in my parser this is solved quite simply:
ExpressionStatement = Expression {filter: [objectLiteral, functionDeclaration]} ... ObjectLiteral = {commonId: objectLiteral} '{' '}' | '{ 'PropertyNameAndValueList '}' | '{' ',' '}' When closing, we set the filtering label from the parent to the child if necessary. And when we meet the rule that falls under the filtering, we simply do not include it in the closure.Turn off some child rules
This is almost a subtype of the previous item, but here you need to look not only at the first character, but also at an arbitrary one. The illustration is the aforementioned ExpressionNoIn and a VariableDeclarationListNoIn similar to it. If you look in more detail, the roots of the problem go to 2 types of for'a for example:
// first syntax
for (var id in obj) alret (id);
// second syntax
for (var id = 1; id <10; id) alert (id);
Under normal conditions, when initializing variables, we can use in, a la a = 'eval' in window; This operator checks the existence of a member in a given object (hussars, be silent!). However, in the loop it is used to iterate through all members of the object. And, actually, confusion may very easily arise, therefore inside the second syntax it is forbidden to use in. In fact, the LALR parser easily resolves all of this thanks to a convolution checking the next character (';' or ')'), but the creators of the grammar apparently focused on a wider class of parsers and therefore introduce duplicate 20 rules for the case without the “in” operator. However, you need to follow the grammar, so you also need a mechanism to turn off unwanted children (great-great -...) rules.
I have it completely similar to the previous paragraph, except that the differences in the details:
ExpressionNoIn = Expression {filter: [RelationalExpression_6]} ... RelationalExpression = ShiftExpression | RelationalExpression '<' ShiftExpression | RelationalExpression '>' ShiftExpression | RelationalExpression '<=' ShiftExpression | RelationalExpression '>=' ShiftExpression | RelationalExpression 'instanceof' ShiftExpression | {id: RelationalExpression_6} RelationalExpression 'in' ShiftExpression This is an optional feature that just makes life easier. And how exactly show examples of errors. In the grammar itself, they forgot to add NoIn in one of the rules:
ConditionalExpressionNoIn = LogicalORExpressionNoIn ? AssignmentExpression : AssignmentExpressionNoIn The second AssignmentExpression must be obvious with a postfix.Automatic insertion ';'
Another interesting feature of JavaScript is that the Statement does not have to be completed with a semicolon. Even in places where grammar requires it. Insertion rules are both simple to describe and difficult to implement:
- If the parser returned an error on the next token and this token '{' or it is separated from the previous one by at least one newline.
- We met EOF and it was unexpected.
- For fora, the rules do not apply. Semicolons between brackets in the header for'a.
The insertion is quite simple - if you determine the need for this action, then just go to the new FSM circle, replacing the last token read with a semicolon. Well, in the next shift, we don’t read the new token, but use the one that caused the error.
Unicode support
JS is a very competent language in this regard. Support for utf16 is written hard in the standard. Up to the point that before parsing the entire source must be converted to utf16. However, unfortunately, flex does not know how to do this (no, \ xXX is not suitable. Offhand, about a thousand characters will need to be encoded). Therefore, while this condition is not met.
Quantifier support
Another fairly large topic that makes it easier to work with grammar. I first needed the following quantifiers: "|" - variants of the rules, where the left part is common and the right part is different; "?" - optional character in the rule; "*" - the symbol is repeated 1 or more times. Yes, they are completely resolved at the level of BNF grammars:
A = B | C // A = B A = C A = B? C // A = BC A = C A = B* // A = AB A = B Here everything is fine except for the last example. In this case, we get the steps in the tree. That is, if B is repeated 5 times, then we get node A with a depth of 5. This is very inconvenient. Therefore, again, I decided to introduce modifications to the parser that provide a convenient linear representation - BBBBB form one node A with 5 leaves B. In practice, this looks like the introduction of a new type of operation - ReduceRepeated. And modifications of closure functions and definitions of convolutions. In closeItem () we loop the element.
But what will happen if done as usual:
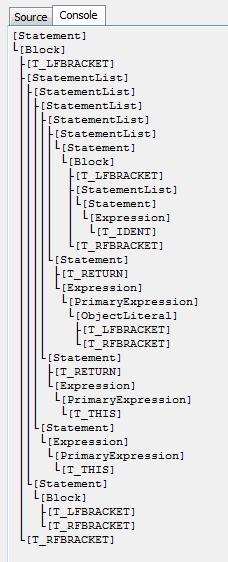
That's all. Thank you for reading this article.
Parts of the article
- Part 1. Basic theory
- Part 2. Description of LR-generators
- Part 3. Features of writing and possible features of LR-generators
Source: https://habr.com/ru/post/140441/
All Articles