AtContent.com. Internal structure and architecture
 This article opens a series of articles about the internal structure of the AtContent.com service. How the content goes from the author to the end user, what mechanisms he has to go through and how he interacts with different modules - you will learn about all this from the cycle. Opens his article with a general description of the architecture of the service. The series will also include the article “The mechanism of messaging between roles and instances”, “Caching data on the instance and caching management”, “Effective management of processing cloud queues (Queue)”, “Extensions for LINQ that implement Or and Contains operations to Azure Table Storage "," Practical tips for splitting data into parts, generating PartitionKey and RowKey for Azure Table Storage ".
This article opens a series of articles about the internal structure of the AtContent.com service. How the content goes from the author to the end user, what mechanisms he has to go through and how he interacts with different modules - you will learn about all this from the cycle. Opens his article with a general description of the architecture of the service. The series will also include the article “The mechanism of messaging between roles and instances”, “Caching data on the instance and caching management”, “Effective management of processing cloud queues (Queue)”, “Extensions for LINQ that implement Or and Contains operations to Azure Table Storage "," Practical tips for splitting data into parts, generating PartitionKey and RowKey for Azure Table Storage ".AtContent.com is a new generation service for distributing and monetizing copyright content. It is based on the income sharing model and offers qualitatively new tools for authors, distributors and media platforms. The author of the content can independently publish his work, get himself fans and get the distribution network without effort! With the help of a special widget both the author and the distributor of the publication can earn. More distribution network, more sales, more income to the authors.
Now the service is available only for authors. If you want to try it out in action and publish your material using our service - register by a special link .
As a platform for architecture, we use Microsoft Windows Azure and such components as:
- Web Role - an application instance in Azure to launch web projects;
- Table Storage - data storage in Azure that allows you to store structured data;
- Blob Storage - another data storage in Azure, but to save files;
- Worker Role - an instance of an application or service that does not need a web interface;
- Queue - cloud message queue for Azure services;
- Azure SQL is a cloud based SQL database based on MS SQL server.
Our choice of this particular platform is due to the fact that it allows us to focus on development without thinking about infrastructure. We also use Apache Lucene - an open search technology for organizing data retrieval, the international payment system PayPal for organizing the acceptance of payments from users.
')
So, to publish his works, the author visits the site and uploads the publication. The publication itself falls into Blob Storage, and various meta-information about it falls into Table Storage. At the time of publication, the indexing mechanism is launched, which consists of several stages. The first step is to add a task to the index queue. The second is the transfer of the processing task to Worker Role using the mechanism of inter-role interactions. The third is the processing of the Worker Role job. Indexing and subsequent search is performed using Apache Lucene.
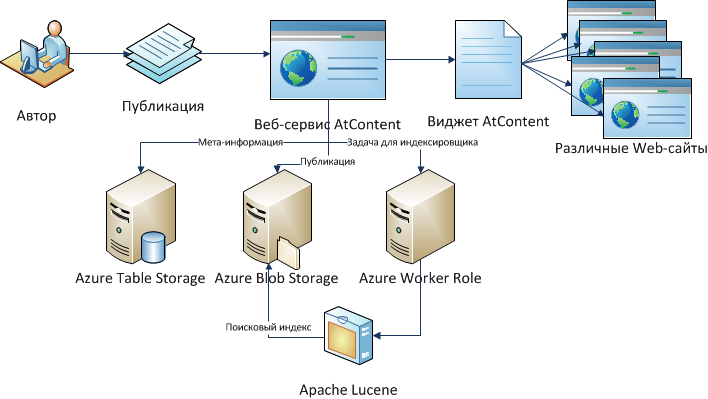
Figure 1. The scheme of publication of materials
All media files, such as pictures, audio, video and other files are stored in Blob Storage. Each file has a metadata that stores information about the owner of the file and the publication to which he belongs. Files are sent to the user through a special gateway that controls access based on the information in the metadata and user data.
After publication, the author gets a widget that he can place on any site. Also, this widget falls into the list of all publications on the site and various other lists, such as Feed subscribers, the list of publications of the author and others. Almost all of them are stored in Table Storage.
It is also worth mentioning that the publication can be free (in which all content is public), with the possibility of donations, and paid. For paid publishing, some of the content may be closed. Payment takes place directly in the widget and the paid part of the publication becomes available immediately after payment by the reader. For payment of articles using the internal mechanism of prepaid loans. Replenishment occurs through PayPal. Since the operations with loans are carried out in blocking mode, they are stored in Blob Storage, because it allows for blocking operations.

Figure 2. The scheme of purchase paid publication
At the time of purchase, the number of credits corresponding to the price of publication is taken away from the user's account, and then it is distributed between the author, distributor and service. All operations are conducted with an accuracy of one hundredth of a cent, which allows you to set the price of publication in one cent.
All data exchange between the widget and the service is carried out through the so-called Native AJAX. The widget generates requests to the service, and the latter, in turn, generates in response JavaScript files that are processed by the widget.
When a publication widget is loaded, it is selected from the database and, at the same time, is cached on the same instance where it is selected. And to ensure the relevance of the cache when updating the publication by the author, it is cleared. Using our own mechanism for interaction between instances, a special command is sent to clear the corresponding part of the cache.
The widget also collects various statistics, such as views based on the location of the widget, the distribution path of the publication, sales and donations for the respective publications. The author and the distributor are provided with various analytical information on these statistics. In this connection, we needed a mechanism to fetch Table Storage with the Or and Contains operations. For this, extensions were written for LINQ queries to Table Storage, since Azure SDK does not allow modifying queries in this way.
The site has a user rating, which is formed from user reviews. Because it is formed dynamically, and storing it in Table Storage is very expensive. Therefore, it is stored in Azure SQL, which allows you to make selections with sorting.
Using Windows Azure allows us to control the load on the service and our costs. The system is designed in such a way that allows you to easily scale it horizontally, i.e. increase the number of Web Role and Worker Role with increasing load.
Read in the series:
- " The mechanism of messaging between roles and instances ",
- " Caching data on an instance and managing caching ",
- " Effective management of processing cloud queues (Azure Queue) ",
- " LINQ extensions for Azure Table Storage, implementing Or and Contains operations ",
- " Practical tips for splitting data into parts, generating PartitionKey and RowKey for Azure Table Storage ."
Source: https://habr.com/ru/post/140418/
All Articles