Development of PHP parser using ANTLR
As a hobby for the past few months I have been developing a PHP parser using ANTLR . The project itself is rather just Just for me for me, but in the course of its implementation I, of course, had difficulties. This is reflected in both the feature of the PHP language with the complete absence of specifications and the limitations of the LL (k) algorithms.
In this article I would like to share technical solutions and some tricks in the implementation of the parser and its testing procedure. This article will be useful to those who want to understand in more detail how to use the ANTLR v2 tool.
Here I will try to tell you what this task is interesting for and what difficulties were to be solved.
')
This is perhaps the main obstacle in the development of the parser, since in this case, in addition to the development itself, some kind of reverse engineering of grammar is required.
This means that in the pure form the existing parsing algorithms (groups of algorithms LL (k) and LR (k)) are in principle inapplicable. The reasons are as follows:
The list of purely technical difficulties can be easily attributed to the alternative syntax of control structures and the incompleteness of official documentation.
When I started this job, I thought I knew php. Actually, therefore, at first, the fact that there were no specifications did not bother me at all. Initially, the most serious question seemed to be how to describe in a formal language the fact that the source code to be recognized should be considered only what is in the section
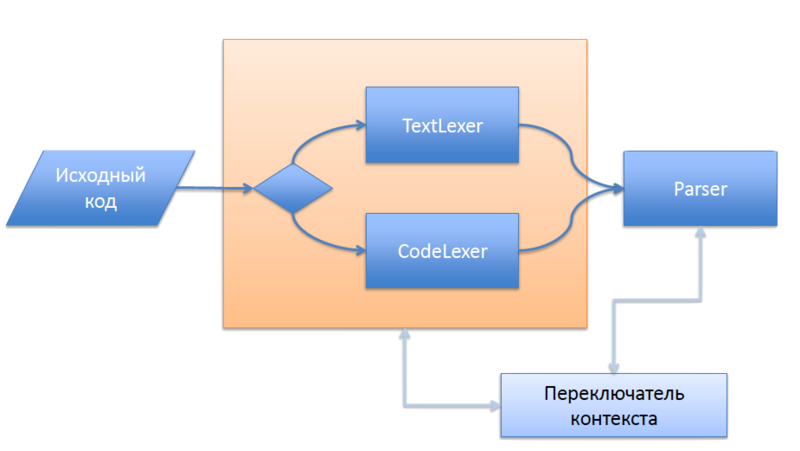
The most concise here was the solution based on the multiplexing of tokens and the use of the stack of lexers. For this purpose, I have already needed an additional entity that stores the current state of the entire parser (at least, the state is “now waiting for the code” or “we are now forwarding any text”, see ParsingState.java ).
And, of course, two different lexer grammars: phpLexer and phpOutTheCode . The signals for context switching are directly the tokens
Schematically, this idea is shown below.
The HEREDOC notation is a multi-line string literal, which can be any identifier as a “quotation”. Such a literal is recognized by embedded code, which is executed after the beginning of HEREDOC is encountered in the form of a lexeme <<<. Directly this fragment of the lexer grammar can be seen here .
Keywords in the ANTLR grammar are not identifiers. If you look at the code that in such cases is generated by ANTLR, the keyword is always recognized as a regular identifier, and then the image (string representation) is checked using the keyword dictionary. This operation is performed inside the lexer class, which at the time of recognition does not know (and cannot know) the context of the parser class for the following reasons:
Fortunately, the solution is simple enough: to declare a rule at the parser level as an identifier and to list, in addition to “honest” identifiers, keyword tokens as possible values. Here, however, there is another danger: there will be ambiguity at the level of the rules of the parser, for example, the operation of casting to type
can be interpreted as
Such a problem was solved with the help of an additional syntactic predicate (see php.g ).
A lot of effort was spent on figuring out and “setting up” the priority of operations. Official documentation is incomplete. So, among the operators there is a comma, which they are not in PHP.
Interestingly, in PHP, the use of assignment is allowed inside the ternary operator (thanks to mark_ablov for the clarification ). That is, the construction of the form
It will not compile in C / C ++, but compiled in PHP (such an example was found in the code of phpBB3).
Another curious thing: the expression
The lexeme
The dollar symbol often looks like an operator (I asked a question on this topic earlier), but it is not: the possibility of “using” several dollars in a row is recognized by the lexer and then it still looks like one lexeme - this is done in the official compiler.
All the listed subtleties of the language were found out, as a rule, during testing. In this case, testing on the source code of real projects made it possible to make sure that the grammar covers the most complete language. In addition, it is extremely important to track regressions: one small revision in a grammar can break absolutely everything.
The meaning of the tests that I use for these purposes is extremely simple: a simple console wrapper is created around the library that accepts the php file as input. If the parser has recognized the file without problems, then the wrapper does nothing, the problem is encountered - we print the relevant information.
The wrapper program is launched by the find command with output to a file.
Like that:
Output files (in this case, out-phpbb.txt) can be saved and compared with the new result. The result has improved or deteriorated - you can understand by the number of lines in the file:
The project of the parser is currently of more academic interest. It can be used as a basis, for example, to extend CheckStyle functionality or to implement your own php beautifier.
As you can see, the parser is now designed for language version 5.2, although there are no fundamental problems in bringing grammar to level 5.3 in my opinion (with version 5.4 it is more difficult: there is practically no test base for grammar validation). At the moment, the parser successfully parses the entire set of source codes ZF 1.11, Yii Framework 1.1.10 and phpBB 3.0.10.
I would be glad if this work seemed to someone interesting and / or useful. Your comments and criticisms will also be helpful.
Thank you for your attention!
In this article I would like to share technical solutions and some tricks in the implementation of the parser and its testing procedure. This article will be useful to those who want to understand in more detail how to use the ANTLR v2 tool.
Problematics
Here I will try to tell you what this task is interesting for and what difficulties were to be solved.
')
1. Lack of formal language specification
This is perhaps the main obstacle in the development of the parser, since in this case, in addition to the development itself, some kind of reverse engineering of grammar is required.
2. PHP grammar is not context free
This means that in the pure form the existing parsing algorithms (groups of algorithms LL (k) and LR (k)) are in principle inapplicable. The reasons are as follows:
- Interleaving executable code with an arbitrary text stream.
- HEREDOC notation - a quote is an arbitrary sequence of characters
- A number of keywords in a language can serve as ordinary identifiers.
The list of purely technical difficulties can be easily attributed to the alternative syntax of control structures and the incompleteness of official documentation.
Implementation
Separation of code from text "garbage"
When I started this job, I thought I knew php. Actually, therefore, at first, the fact that there were no specifications did not bother me at all. Initially, the most serious question seemed to be how to describe in a formal language the fact that the source code to be recognized should be considered only what is in the section
<?php … ?> The most concise here was the solution based on the multiplexing of tokens and the use of the stack of lexers. For this purpose, I have already needed an additional entity that stores the current state of the entire parser (at least, the state is “now waiting for the code” or “we are now forwarding any text”, see ParsingState.java ).
And, of course, two different lexer grammars: phpLexer and phpOutTheCode . The signals for context switching are directly the tokens
<?php , <?= And ?> .Schematically, this idea is shown below.
HEREDOC lines
The HEREDOC notation is a multi-line string literal, which can be any identifier as a “quotation”. Such a literal is recognized by embedded code, which is executed after the beginning of HEREDOC is encountered in the form of a lexeme <<<. Directly this fragment of the lexer grammar can be seen here .
Keywords as ids
Keywords in the ANTLR grammar are not identifiers. If you look at the code that in such cases is generated by ANTLR, the keyword is always recognized as a regular identifier, and then the image (string representation) is checked using the keyword dictionary. This operation is performed inside the lexer class, which at the time of recognition does not know (and cannot know) the context of the parser class for the following reasons:
- The parser takes the next lexeme not from a lexer, but from a special buffer. The buffer is filled ahead of time to be able to look ahead to the k lexemes, as required by the LL (k) algorithm. This means that at the moment of recognizing the lexeme, the parser may still not know whether an identifier is expected in this place or not: the lexer is working ahead.
- In the case of processing syntactic predicates (so-called Managed backtracking), the parser can perform kickbacks along the stream of tokens, and it is difficult to catch the rollback / dokat situation from the outside predicate.
Fortunately, the solution is simple enough: to declare a rule at the parser level as an identifier and to list, in addition to “honest” identifiers, keyword tokens as possible values. Here, however, there is another danger: there will be ambiguity at the level of the rules of the parser, for example, the operation of casting to type
(typeName) expressioncan be interpreted as
(expression) expression , because, for example, the int keyword will, by virtue of the reason described, be an input token in expression (since it will be an identifier). The design does not make sense and will lead to a recognition error.Such a problem was solved with the help of an additional syntactic predicate (see php.g ).
typeCastExpression[boolean allowComma]: (LPAREN typeName RPAREN expression[false, false]) => (LPAREN^ typeName RPAREN { #LPAREN.setType(TYPE_CAST) ;} typeCastExpression[allowComma] ) | (LNOT^ typeCastExpression[allowComma]) | (DOG^ typeCastExpression[allowComma]) | (BW_NOT^ typeCastExpression[allowComma] ) | (MINUS^ {#MINUS.setType(UNARY_MINUS);} typeCastExpression[allowComma]) | (PLUS^ {#PLUS.setType(UNARY_PLUS);} typeCastExpression[allowComma]) | incrementExpression[allowComma] ; Priority of operations and other
A lot of effort was spent on figuring out and “setting up” the priority of operations. Official documentation is incomplete. So, among the operators there is a comma, which they are not in PHP.
Interestingly, in PHP, the use of assignment is allowed inside the ternary operator (thanks to mark_ablov for the clarification ). That is, the construction of the form
a = test() ? b = c : d = e; It will not compile in C / C ++, but compiled in PHP (such an example was found in the code of phpBB3).
Another curious thing: the expression
echo (this is not a function, but an expression) allows for the enumeration of operands separated by commas. This will work as concatenation during output, but thanks to the phpMyAdmin source, another similar construct was found - print, which is similar to echo, but does not allow commas anymore.The lexeme
?> Turns out to be equivalent to a semicolon. The <?= Operator is equivalent to echo (including the remark above about the comma).The dollar symbol often looks like an operator (I asked a question on this topic earlier), but it is not: the possibility of “using” several dollars in a row is recognized by the lexer and then it still looks like one lexeme - this is done in the official compiler.
Testing
All the listed subtleties of the language were found out, as a rule, during testing. In this case, testing on the source code of real projects made it possible to make sure that the grammar covers the most complete language. In addition, it is extremely important to track regressions: one small revision in a grammar can break absolutely everything.
The meaning of the tests that I use for these purposes is extremely simple: a simple console wrapper is created around the library that accepts the php file as input. If the parser has recognized the file without problems, then the wrapper does nothing, the problem is encountered - we print the relevant information.
The wrapper program is launched by the find command with output to a file.
Like that:
$ (find ~/Documents/distr/phpBB3/ -name '*.php' -print -exec java -jar bin/jar/parse-php-test.jar -f {} \; ) &>./out-phpbb.txtOutput files (in this case, out-phpbb.txt) can be saved and compared with the new result. The result has improved or deteriorated - you can understand by the number of lines in the file:
$ wc -l ./out-koh.txt* 498 ./out-koh.txt 502 ./out-koh.txt.old Conclusion
The project of the parser is currently of more academic interest. It can be used as a basis, for example, to extend CheckStyle functionality or to implement your own php beautifier.
As you can see, the parser is now designed for language version 5.2, although there are no fundamental problems in bringing grammar to level 5.3 in my opinion (with version 5.4 it is more difficult: there is practically no test base for grammar validation). At the moment, the parser successfully parses the entire set of source codes ZF 1.11, Yii Framework 1.1.10 and phpBB 3.0.10.
I would be glad if this work seemed to someone interesting and / or useful. Your comments and criticisms will also be helpful.
Thank you for your attention!
Source: https://habr.com/ru/post/140179/
All Articles