Search engine indexing in Evernote
The index system in Evernote is designed to expand the search capabilities of Evernote and provide search through media files. Its task is to examine the contents of these files and make any textual information found in them available for search. It currently processes images and PDF files, as well as “digital ink” (digital ink), but we have plans to support indexing and other types of media files. The resulting index is displayed in the form of an XML or PDF document and contains recognized words, alternative recognition options, as well as the coordinates of the found words in the document (for subsequent highlighting).
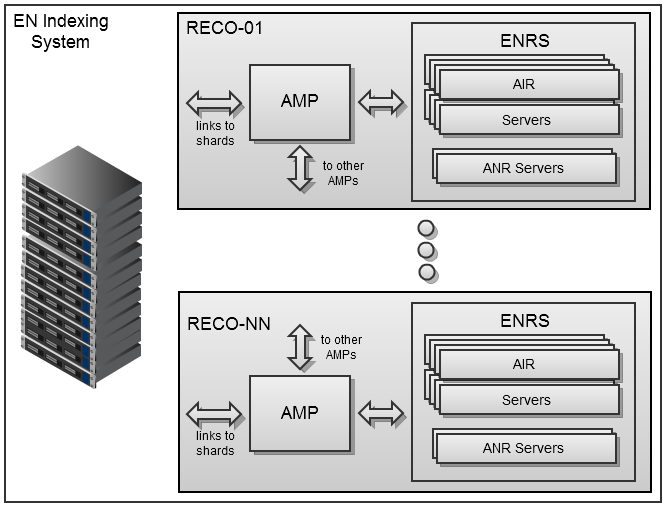
The indexing system is implemented as a farm of dedicated Debian64 servers, each of which runs the management service AMP (Asynchronous Media Processor) and several ENRS processes (Evernote Recognition Server) - usually based on the total number of processor cores. ENRS is implemented as a set of native libraries packaged in a Java6 web server application. Now it includes two components under the code names AIR and ANR. The first handles various types of images and PDF, and the second is designed for indexing “digital ink”. AMP communicates with servers through the HTTP REST API, which allows flexible system configuration while maintaining high bandwidth when transferring large files.
AMP receives source resources from cluster servers (shards) that store user data, and returns created indexes. They will be included in the search index of the Evernote web service and will be synchronized to Evernote clients for computers and mobile devices to simplify local search in media files. In order to minimize additional traffic to shards, AMP handlers already engaged in processing user requests in turn broadcast information to each other. Thus, a single distributed media content handler is generated, optimized for current load priorities and service processes. The Evernote indexing system turns out to be quite stable and will work even if only one component of each type remains in the system (currently the system includes 37 AMP handlers and over 500 ENRS server processes that deal with approximately 2 million media files per day).
')
Let's take a closer look at the AIR component in the ENRS server. Ideologically, AIR recognition differs from traditional OCR systems, since its goal is to create not a complete readable text, but a full search index. This means that we strive to find in the images the maximum number of words with any minimum acceptable quality, including alternative readings for incomplete, fuzzy and out-of-focus word images.
When recognizing images from the real world, the AIR server processes them in several approaches, each time making different assumptions. The image can be huge, but contain only a few words. It may also contain words scattered in a picture and differently oriented in space. Fonts can be both very small and large enough in the same area. The text can alternate: black on a white background and immediately white on black. It can be a mixture of different languages and alphabets. In the case of Asian languages, horizontal and vertical text lines can be represented in one area. Font colors with the same intensity can merge into a single gray level during standard OCR processing. Printed text may include handwritten comments. Promotional material may contain text that is distorted, slanted or resized on the go. And these are just a few of the problems that AIR servers now face about 2 million times a day.

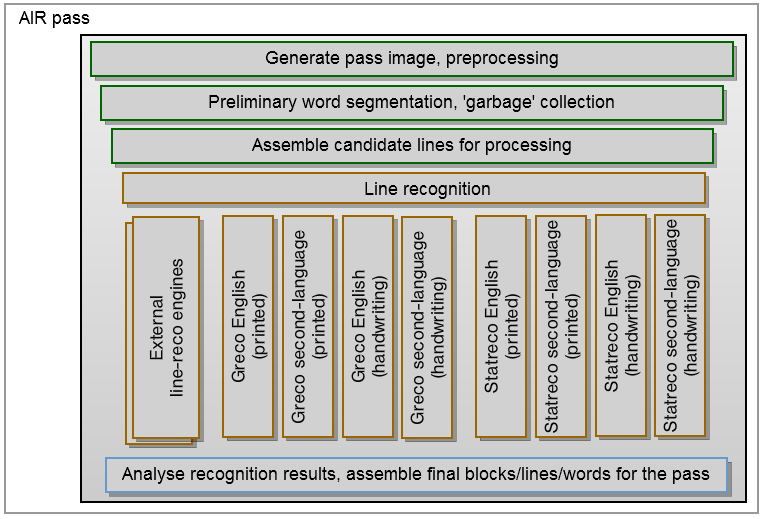
Below is a diagram of a single “passage” of an AIR server. Depending on the call parameters, such a pass will specialize in individual types of processing (size, orientation, etc.), but the basic scheme remains the same. It begins with the preparation of a set of images for processing - scaling, translation in shades of gray, binarization. Then pictures, tables, markup, and other non-text artifacts must be cleaned up to the maximum, so that the system can focus on specific words. After the intended words are defined, they are assembled into text lines and blocks.
Each row of each block will then be processed by several recognition mechanisms - among them are those that were developed within the company and licensed from other manufacturers. The use of several mechanisms is important not only because they specialize in different types of text and languages, but also because they allow for the implementation of “voting”. This implies the analysis of word recognition alternatives, which are the results of different processing mechanisms, which makes it possible to better cut off false recognitions and provides a higher-quality result due to the large number of proposed options. These approved answers will form the basis from which the text string will be recreated at the final stage. Re-use of solutions for text lines, segmentation of words and clearing away from the most questionable options will reduce the number of false positives during the search.
The number of passes required to obtain the result is determined at the initial stage by the rendering and image analysis module, but as the recognition progress is made, this number can be increased or decreased. In the case of a conventional clear scanned document, you can restrict yourself to the standard OCR recognition process. A photograph of a complex scene taken by a phone camera under poor lighting may require in-depth analysis with a full set of passes to extract most text data. The presence of a plurality of colored words on a heterogeneous background may require additional approaches specifically designed to separate the color. The presence of a small blurred text will require the use of an expensive way of reversing digital filtering, which allows you to recover the text before recognizing.
When all the passes are complete, it is time for another important part of the AIR process — the final assembly of the results. In complex images, different approaches can create completely different interpretations for the same areas. All these conflicts should be resolved, the best interpretations should be chosen, most of the incorrect alternatives should be rejected and eventually the final blocks and lines of text should be built.
After the internal structure of the document is created, the last step remains to form the necessary output format. For PDF documents, this is still the same PDF, where the images are replaced by text blocks of recognized words. For other incoming documents, this is an XML index that contains a list of recognized words and indications of their location or lists of strokes (for “digital ink”). This location information will highlight the found word in the source image when the user searches for a document that contains the word.
The indexing system is implemented as a farm of dedicated Debian64 servers, each of which runs the management service AMP (Asynchronous Media Processor) and several ENRS processes (Evernote Recognition Server) - usually based on the total number of processor cores. ENRS is implemented as a set of native libraries packaged in a Java6 web server application. Now it includes two components under the code names AIR and ANR. The first handles various types of images and PDF, and the second is designed for indexing “digital ink”. AMP communicates with servers through the HTTP REST API, which allows flexible system configuration while maintaining high bandwidth when transferring large files.
AMP receives source resources from cluster servers (shards) that store user data, and returns created indexes. They will be included in the search index of the Evernote web service and will be synchronized to Evernote clients for computers and mobile devices to simplify local search in media files. In order to minimize additional traffic to shards, AMP handlers already engaged in processing user requests in turn broadcast information to each other. Thus, a single distributed media content handler is generated, optimized for current load priorities and service processes. The Evernote indexing system turns out to be quite stable and will work even if only one component of each type remains in the system (currently the system includes 37 AMP handlers and over 500 ENRS server processes that deal with approximately 2 million media files per day).
')
Let's take a closer look at the AIR component in the ENRS server. Ideologically, AIR recognition differs from traditional OCR systems, since its goal is to create not a complete readable text, but a full search index. This means that we strive to find in the images the maximum number of words with any minimum acceptable quality, including alternative readings for incomplete, fuzzy and out-of-focus word images.
When recognizing images from the real world, the AIR server processes them in several approaches, each time making different assumptions. The image can be huge, but contain only a few words. It may also contain words scattered in a picture and differently oriented in space. Fonts can be both very small and large enough in the same area. The text can alternate: black on a white background and immediately white on black. It can be a mixture of different languages and alphabets. In the case of Asian languages, horizontal and vertical text lines can be represented in one area. Font colors with the same intensity can merge into a single gray level during standard OCR processing. Printed text may include handwritten comments. Promotional material may contain text that is distorted, slanted or resized on the go. And these are just a few of the problems that AIR servers now face about 2 million times a day.
Below is a diagram of a single “passage” of an AIR server. Depending on the call parameters, such a pass will specialize in individual types of processing (size, orientation, etc.), but the basic scheme remains the same. It begins with the preparation of a set of images for processing - scaling, translation in shades of gray, binarization. Then pictures, tables, markup, and other non-text artifacts must be cleaned up to the maximum, so that the system can focus on specific words. After the intended words are defined, they are assembled into text lines and blocks.
Each row of each block will then be processed by several recognition mechanisms - among them are those that were developed within the company and licensed from other manufacturers. The use of several mechanisms is important not only because they specialize in different types of text and languages, but also because they allow for the implementation of “voting”. This implies the analysis of word recognition alternatives, which are the results of different processing mechanisms, which makes it possible to better cut off false recognitions and provides a higher-quality result due to the large number of proposed options. These approved answers will form the basis from which the text string will be recreated at the final stage. Re-use of solutions for text lines, segmentation of words and clearing away from the most questionable options will reduce the number of false positives during the search.
The number of passes required to obtain the result is determined at the initial stage by the rendering and image analysis module, but as the recognition progress is made, this number can be increased or decreased. In the case of a conventional clear scanned document, you can restrict yourself to the standard OCR recognition process. A photograph of a complex scene taken by a phone camera under poor lighting may require in-depth analysis with a full set of passes to extract most text data. The presence of a plurality of colored words on a heterogeneous background may require additional approaches specifically designed to separate the color. The presence of a small blurred text will require the use of an expensive way of reversing digital filtering, which allows you to recover the text before recognizing.
When all the passes are complete, it is time for another important part of the AIR process — the final assembly of the results. In complex images, different approaches can create completely different interpretations for the same areas. All these conflicts should be resolved, the best interpretations should be chosen, most of the incorrect alternatives should be rejected and eventually the final blocks and lines of text should be built.
After the internal structure of the document is created, the last step remains to form the necessary output format. For PDF documents, this is still the same PDF, where the images are replaced by text blocks of recognized words. For other incoming documents, this is an XML index that contains a list of recognized words and indications of their location or lists of strokes (for “digital ink”). This location information will highlight the found word in the source image when the user searches for a document that contains the word.
Source: https://habr.com/ru/post/139857/
All Articles