Implications for process planning in RTOS
After completing the study of Tanenbaum and picking the Linux kernel, I decided to do something practical. For personal reasons, I decided to remake the minix3 core for planning in hard real-time. Many existing scheduling algorithms have put me in despair, especially since I want to make the OS as versatile and flexible as possible. An obsession with the client-server model led to the idea of removing the planning mechanisms from the OS kernel and dividing the processes into groups that are managed: each with its own scheduler (in kernel mode, leave only the deadline processing).
The main problem that became apparent immediately was the choice of a mathematical model for constructing a scheduling algorithm. It is obvious that the approach of sharing a common resource can be considered in the analogy with the network protocols of sharing common physical space.
IPv4 addressing algorithms and dynamic routing protocols (RIP1 \ 2, OSPF) were considered for inspiration.
So, the algorithm itself:
By analogy with IP addressing, the flows / planning processes are described by number and mask (as subnets), and the groups themselves only by number (target points). Depending on the implementation of the processes, we transmit data about the processes, their execution time, priorities, and so on between the group planners. In my examples, the address byte address / mask byte addressing is used. In total, up to 255 process groups with the ability to run up to 8 schedulers controlling a group, in total up to 510 scheduler processes.
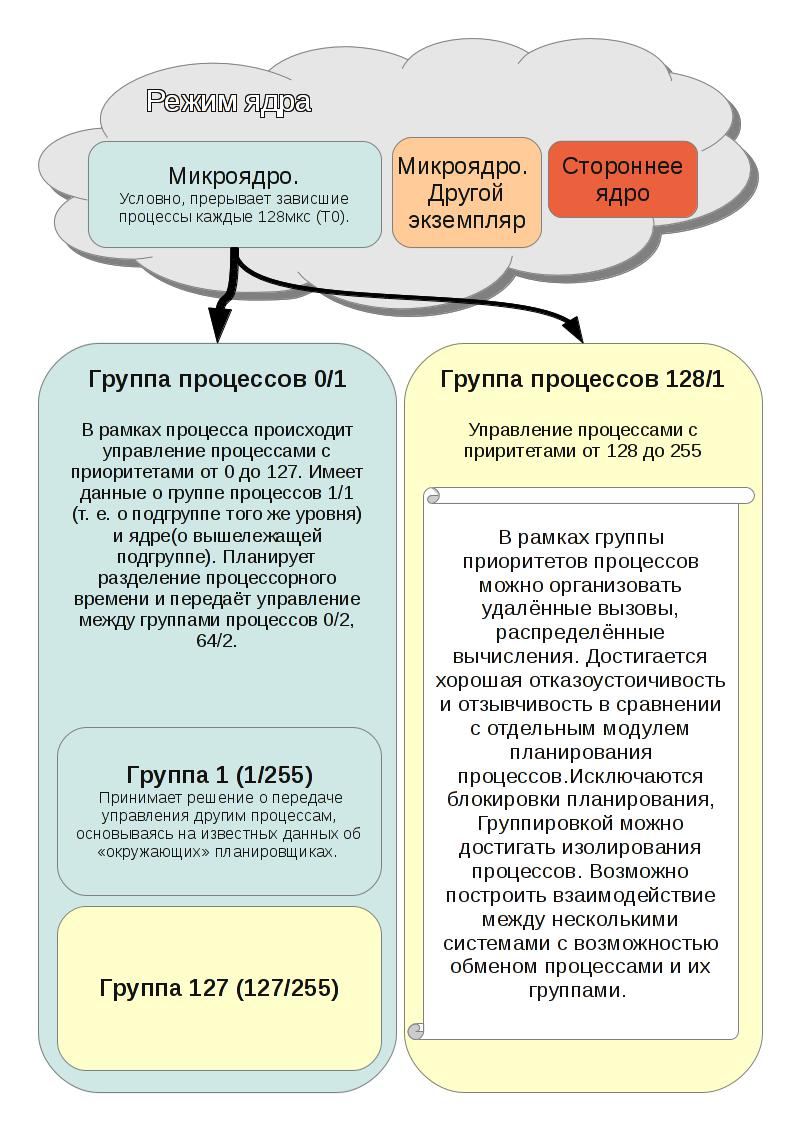
As I develop this idea for a real-time OS, then all application ideas are connected with fault tolerance and predictability.
From the sketch you can understand the basic ideas of application:
1) Transfer processes between schedulers. For example, when a wathcdog is triggered, you can transfer a process from soft real-time mode to hard mode, or if you loop one process, you can replace it with another.
2) The ability to restart the microkernel without stopping the schedulers. For example, you can transfer all processes to another physical device to replace equipment.
3) Schedulers can be run on separate processors / controllers. It is very important for industrial equipment, which is often required to distribute in space.
4) From the 3rd follows the possibility of implementing RPC at the level of system calls. You will not need to use additional middleware.
5) It is possible to implement several scheduling algorithms operating in parallel. Allows you to easily transfer existing projects prepared for a specific algorithm.
6) In case of errors in the scheduler, it will be enough to restart the process group with the new scheduler. It is possible to restore information about the state of the group before the failure of information from other planners.
There are a lot of ideas on how to use, but there are no resources to create an OS kernel from scratch with system libraries, so I’m picking up the minix3 kernel. What can be realized and what is not in question. I hope someone the idea of the algorithm itself is useful. Still thinking about the possibility of implementation in linux || * bsd; with GNU \ Hurd should be easier. Another idea is to increase the address to 16 bits, which will make it possible to unambiguously match the PPID and address (instead of the groups will be the processes themselves), but have not yet come up with a decent use of such a scheme. Here I will place the source code and news (the site on the home computer is not always available ).
I forgot to add that in order to bring the algorithm to completeness, it is necessary to determine the rule for setting the value of the graph vertices and calculate the path of the graph using the Dijkstra algorithm .
I will simulate with a normal distribution of the value of the graphs and conduct tests with the most common packages that I can port.
The main problem that became apparent immediately was the choice of a mathematical model for constructing a scheduling algorithm. It is obvious that the approach of sharing a common resource can be considered in the analogy with the network protocols of sharing common physical space.
IPv4 addressing algorithms and dynamic routing protocols (RIP1 \ 2, OSPF) were considered for inspiration.
So, the algorithm itself:
By analogy with IP addressing, the flows / planning processes are described by number and mask (as subnets), and the groups themselves only by number (target points). Depending on the implementation of the processes, we transmit data about the processes, their execution time, priorities, and so on between the group planners. In my examples, the address byte address / mask byte addressing is used. In total, up to 255 process groups with the ability to run up to 8 schedulers controlling a group, in total up to 510 scheduler processes.
Sketching to the algorithm
As I develop this idea for a real-time OS, then all application ideas are connected with fault tolerance and predictability.
From the sketch you can understand the basic ideas of application:
1) Transfer processes between schedulers. For example, when a wathcdog is triggered, you can transfer a process from soft real-time mode to hard mode, or if you loop one process, you can replace it with another.
2) The ability to restart the microkernel without stopping the schedulers. For example, you can transfer all processes to another physical device to replace equipment.
3) Schedulers can be run on separate processors / controllers. It is very important for industrial equipment, which is often required to distribute in space.
4) From the 3rd follows the possibility of implementing RPC at the level of system calls. You will not need to use additional middleware.
5) It is possible to implement several scheduling algorithms operating in parallel. Allows you to easily transfer existing projects prepared for a specific algorithm.
6) In case of errors in the scheduler, it will be enough to restart the process group with the new scheduler. It is possible to restore information about the state of the group before the failure of information from other planners.
There are a lot of ideas on how to use, but there are no resources to create an OS kernel from scratch with system libraries, so I’m picking up the minix3 kernel. What can be realized and what is not in question. I hope someone the idea of the algorithm itself is useful. Still thinking about the possibility of implementation in linux || * bsd; with GNU \ Hurd should be easier. Another idea is to increase the address to 16 bits, which will make it possible to unambiguously match the PPID and address (instead of the groups will be the processes themselves), but have not yet come up with a decent use of such a scheme. Here I will place the source code and news (the site on the home computer is not always available ).
I forgot to add that in order to bring the algorithm to completeness, it is necessary to determine the rule for setting the value of the graph vertices and calculate the path of the graph using the Dijkstra algorithm .
I will simulate with a normal distribution of the value of the graphs and conduct tests with the most common packages that I can port.
')
Source: https://habr.com/ru/post/139356/
All Articles