Performance: LINQ to XML vs XmlDocument vs XmlReader on Desktop and Windows Phone
Not so long ago, I had to make a Windows Phone application working with xml files. Everything was not bad, but when ~ 100.000 records became in the file, reading them took a very long time. And I decided to compare the performance of various ways of reading data from xml possible on the .Net platform.
Details under the cut.
For a better understanding of the indicators of the tests performed, it is worth telling what they were conducted on. I performed the tests from the category "Desktop" on my home computer:
Tests on Windows Phone were performed on the HTC 7 Mozart.
')
For testing, a simple xml file was used. ID for each element was generated randomly, and the number of records differed depending on the test and was: 1, 10, 100, 1 000, 100 000 pieces, respectively. The final file looked like this:
To reduce errors, each test was performed 100 times and the data averaged. And to simulate some of the actions on the record, the empty ProcessId (id) method was called.
In my opinion, the implementation of reading data in this way is the most simple and clear. But, as we will see at the end, this is achieved at a very high price (at the end of the article the implementation of this method without using XPath is given, but the results, personally, I do not differ much). The method code is as follows:
Using Linq-to-XML also leaves the implementation of the method fairly simple and straightforward.
Finally, the last way to read data from XML is to use XmlTextReader. It is worth saying that this method is the most difficult to understand. In the process of reading the xml file, you move from top to bottom (without the possibility of moving in the opposite direction), and you need to check each time if you need to extract the data? Accordingly, the method code looks like this:
* For simplicity, checks have been omitted from the methods.
Below are the test results. To run each test, time was measured separately and then averaged. The time in the table is in milliseconds.
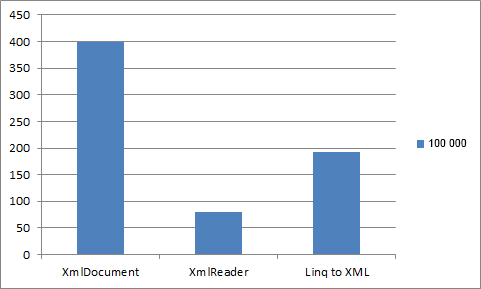
As can be seen from the table, XmlReader when reading large xml files wins Linq To XML performance 2.42 times, and XmlDocument more than 5 times!
Now it's time to conduct tests on the phone. It is worth noting that the older version of the .Net Framework is installed on Windows Phone, so the method using XmlDocument.Load does not work, and the code for the XmlReader had to be slightly rewritten:
Predictably, the XmlReader turned out to be faster on the phone. But unlike a desktop computer, the difference in performance on large files is different. On the XmlReader phone, LINQ to XML is 1.91 times faster, and on the desktop it is 2.42 times faster.
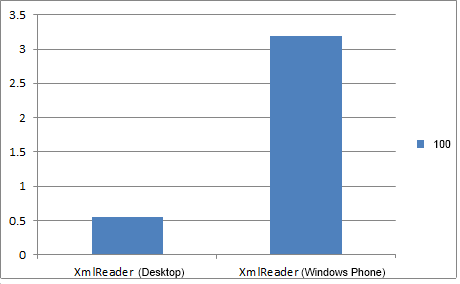
The difference in the speed of reading 100 items from a file on Desktop and Windows Phone.
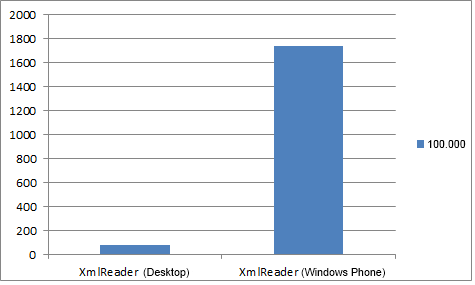
The difference in the speed of reading 100,000 items from a file on Desktop and Windows Phone.
As you can see, the speed of reading data on the phone and desktop, depending on the amount of data varies nonlinearly. I wonder why this is so?
As we explained, the most productive way to read data from xml is to use an XmlReader, regardless of platform. But the inconvenience of its use lies in the rather complicated method of data sampling - every time we have to check on which element the pointer stands.
If, for you, performance is not the cornerstone, and most importantly, the clarity and simplicity of the accompanying code, then the most appropriate is to use LINQ to XML. You should also try to avoid using XmlDocument.Load in work projects because of its poor performance.
PS It is worth mentioning that this article inspired me to write all this.
Update: at the suggestion of alex_rus made a test for XmlDocument without using XPath. The results were better, but still this method remained the slowest.
Table No. 3. Comparison of XmlDocument performance with and without XPath.

As can be seen from the table (and figure), the performance increased only by 10%. Although there were suggestions that this value will be much higher.
Actually, the code for an XmlDocument without XPath is below. I hope, knowledgeable people will show where I have errors, as a result of which the processing speed increased by only 10%, and not “at times”.
Details under the cut.
Equipment
For a better understanding of the indicators of the tests performed, it is worth telling what they were conducted on. I performed the tests from the category "Desktop" on my home computer:
- Processor: Pentium Dual-Core T4300 2100 Mhz
- RAM: DDR2 2048Mb
Tests on Windows Phone were performed on the HTC 7 Mozart.
')
Preparation for testing
For testing, a simple xml file was used. ID for each element was generated randomly, and the number of records differed depending on the test and was: 1, 10, 100, 1 000, 100 000 pieces, respectively. The final file looked like this:
<? xml version ="1.0" ? >
< items >
< item id ="433382426" />
< item id ="1215581841" />
< item id ="2085749980" />
........
< item id ="363608924" />
</ items >
* This source code was highlighted with Source Code Highlighter .To reduce errors, each test was performed 100 times and the data averaged. And to simulate some of the actions on the record, the empty ProcessId (id) method was called.
XmlDocument.Load
In my opinion, the implementation of reading data in this way is the most simple and clear. But, as we will see at the end, this is achieved at a very high price (at the end of the article the implementation of this method without using XPath is given, but the results, personally, I do not differ much). The method code is as follows:
private static void XmlDocumentReader( string filename)
{
var doc = new XmlDocument ();
doc.Load(filename);
XmlNodeList nodes = doc.SelectNodes( "//item" );
if (nodes == null )
throw new ApplicationException( "invalid data" );
foreach ( XmlNode node in nodes)
{
string id = node.Attributes[ "id" ].Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter .LINQ to XML
Using Linq-to-XML also leaves the implementation of the method fairly simple and straightforward.
private static void XDocumentReader( string filename)
{
XDocument doc = XDocument .Load(filename);
if (doc == null || doc.Root == null )
throw new ApplicationException( "invalid data" );
foreach ( XElement child in doc.Root.Elements( "item" ))
{
XAttribute attr = child. Attribute ( "id" );
if (attr == null )
throw new ApplicationException( "invalid data" );
string id = attr.Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter .Xmlreader
Finally, the last way to read data from XML is to use XmlTextReader. It is worth saying that this method is the most difficult to understand. In the process of reading the xml file, you move from top to bottom (without the possibility of moving in the opposite direction), and you need to check each time if you need to extract the data? Accordingly, the method code looks like this:
private static void XmlReaderReader( string filename)
{
using ( var reader = new XmlTextReader (filename))
{
while (reader.Read())
{
if (reader.NodeType == XmlNodeType .Element)
{
if (reader.Name == "item" )
{
reader.MoveToAttribute( "id" );
string id = reader.Value;
ProcessId(id);
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter .* For simplicity, checks have been omitted from the methods.
Results for Desktop
Below are the test results. To run each test, time was measured separately and then averaged. The time in the table is in milliseconds.
| one | ten | 100 | 1,000 | 10,000 | 100,000 | |
| Xmldocument | 0.59 ms | 0.5 ms | 0.67 ms | 2.49 ms | 21.73 ms | 398.91 ms |
| Xmlreader | 0.51 ms | 0.47 ms | 0.55 ms | 1.31 ms | 8.62 ms | 79.65 ms |
| Linq to XML | 0.57 ms | 0.59 ms | 0.64 ms | 2.09 ms | 15.6 ms | 192.66 ms |
As can be seen from the table, XmlReader when reading large xml files wins Linq To XML performance 2.42 times, and XmlDocument more than 5 times!
Testing on Windows Phone
Now it's time to conduct tests on the phone. It is worth noting that the older version of the .Net Framework is installed on Windows Phone, so the method using XmlDocument.Load does not work, and the code for the XmlReader had to be slightly rewritten:
private static void XmlReaderReader( string filename)
{
using ( var reader = XmlReader.Create(filename)) {
while (reader.Read()) {
if (reader.NodeType == XmlNodeType .Element) {
if (reader.Name == "item" ) {
reader.MoveToAttribute( "id" );
string id = reader.Value;
ProcessId(id);
}
}
}
}
}
* This source code was highlighted with Source Code Highlighter .Results for Windows Phone
Predictably, the XmlReader turned out to be faster on the phone. But unlike a desktop computer, the difference in performance on large files is different. On the XmlReader phone, LINQ to XML is 1.91 times faster, and on the desktop it is 2.42 times faster.
| one | ten | 100 | 1,000 | 10,000 | 100,000 | |
| Xmlreader | 1.67 ms | 1.74 ms | 3.19 ms | 19.5 ms | 173.84 ms | 1736.18 ms |
| Linq to XML | 1.73 ms | 2.21 ms | 4.75 ms | 31.39 ms | 314.39 ms | 3315.13 ms |
The difference in the speed of reading 100 items from a file on Desktop and Windows Phone.
The difference in the speed of reading 100,000 items from a file on Desktop and Windows Phone.
As you can see, the speed of reading data on the phone and desktop, depending on the amount of data varies nonlinearly. I wonder why this is so?
Conclusion
As we explained, the most productive way to read data from xml is to use an XmlReader, regardless of platform. But the inconvenience of its use lies in the rather complicated method of data sampling - every time we have to check on which element the pointer stands.
If, for you, performance is not the cornerstone, and most importantly, the clarity and simplicity of the accompanying code, then the most appropriate is to use LINQ to XML. You should also try to avoid using XmlDocument.Load in work projects because of its poor performance.
PS It is worth mentioning that this article inspired me to write all this.
Update: at the suggestion of alex_rus made a test for XmlDocument without using XPath. The results were better, but still this method remained the slowest.
Table No. 3. Comparison of XmlDocument performance with and without XPath.
| one | ten | 100 | 1,000 | 10,000 | 100,000 | |
| XmlDocument (with XPath) | 0.59 ms | 0.5 ms | 0.67 ms | 2.49 ms | 21.73 ms | 398.91 ms |
| XmlDocument (without XPath) | 0.56 ms | 0.5 ms | 0.65 ms | 2.24 ms | 19.47 ms | 362.75 ms |
As can be seen from the table (and figure), the performance increased only by 10%. Although there were suggestions that this value will be much higher.
Actually, the code for an XmlDocument without XPath is below. I hope, knowledgeable people will show where I have errors, as a result of which the processing speed increased by only 10%, and not “at times”.
private static void XmlDocumentReader2( string filename)
{
var doc = new XmlDocument ();
doc.Load(filename);
XmlElement root = doc.DocumentElement;
foreach (XmlElement el in root.ChildNodes)
{
if (el.Name != "item" ) continue ;
string id = el.Attributes[ "id" ].Value;
ProcessId(id);
}
}
* This source code was highlighted with Source Code Highlighter .Source: https://habr.com/ru/post/138848/
All Articles