HyperDex is a new open source NoSQL key-value repository, sharpened to a very fast search.
The authors position HyperDex as a distributed, fault-tolerant, easy-to-scale, sharpened for a very fast search NoSQL key-value storage.
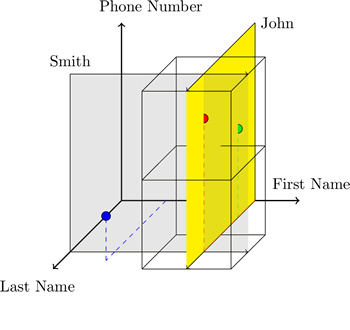
The main feature is the new principle of storing objects in multidimensional Euclidean space (fig. Left) using hyperspace hashing ( which, by the way, the authors now receive a patent ), which allows you to perform most typical tasks from 2 to 13 times faster than in MongoDB, Redis, Cassandra.
')
about the project
HyperDex appeared in the depths of the Faculty of Computer Science at Cornell University by 3 authors.
One of the authors announced the project on Hacker News & Slashdot only yesterday, February 22.
Judging by the site and the description of the project - there is still little information. The nature of this topic is introductory, I decided to translate the introductory information about the project, available on their website and in the documentation. If you are interested in the project, I advise you to familiarize yourself with a more detailed 15-page description (link below)
Written in C ++; 39,750 LoC; Githab Sors ( 3-clause BSD license )
Website | Full Description (PDF, 15 pp., Eng.)
Installation manual (there are packages for Debian, Ubuntu, Fedora)
* Important: HyperDex starts only on the x86_64 platform.
In a nutshell about hyperspace hashing
HyperDex presents each table as an independent multidimensional space, where the axes are the attributes of the table. On the example of the 1st figure, we have a table containing information about the user with the attributes “First Name” (X axis), “Last Name” (Y) and “Phone Number” (Z). HyperDex assigns each object the appropriate coordinates based on its attributes. Further, the object is mapped to these coordinates by hashing each attribute on its corresponding axes.
In the case where there are many attributes, the space is divided into subspaces


More detailed info on the principles of hashing, storage on disk, as well as sharding and replication - read the full description of the project.
Benchmarks
Benchmarks were held by the YCSB (Yahoo! Cloud Serving Benchmark) tool on a cluster of 14 nodes each (2x Intel Xeon 2.5 GHz E5420, 16 GB RAM, 500 GB SATA 3G Gbit 7200 RPM, 64-bit Debian 6 Linux 2.6.32 kernel)
MongoDB 2.0.0
Cassandra 0.7.3
UPD: Now, a few days after publication on HN & Slashdot, it is clear that these benchmarks are the main topic of debate, in which the authors of both the project itself and Radish (antirez) and other specialists on the compared products participate. Obviously, each database works best on its own front of tasks and “universal” benchmarks do not provide a picture for objective comparison.
Description of load scenarios on graphs ( Workloads (English)):

- A. 50/50 read-write (session, a couple of actions with the database)
- B. 95/5 read-write
- C. Read Only
- D. Adding New Records and Reading Recent Changes
- E. Search
- F. Read object / change / write back
 Insert 10,000,000 objects |  Workload B. 95% read, 5% write on 10K scenario operations |
 Search. 10K scenario operations. Important note on this bench: HyperDex is not looking for index-based (non-primary) attributes of objects, while the rest are looking only for primary-key |
 Linear Scalability. on 32 nodes, HyperDex handles 3.2 million operations per second |  Comparison with Redis. Workload E - Search. Discussion of this bench in the Redis mailing list ( agladysh ) |
Discussion with one of the authors (rescrv) on Hacker News | Slashdot
Source: https://habr.com/ru/post/138737/
All Articles