Linux QoS: U32 filter
It so happened that the U32 filter in the Linux kernel traffic control subsystem is considered simple and straightforward, and therefore does not need detailed documentation. For example, in LARTC (Linux Advanced Routing and Traffic Control) there are only a few paragraphs about it. But in fact, the U32 is much more complicated and interesting, but in use it is not as simple as it may seem. Under the cut article on this filter with examples of use and detailed explanations.
And so, the main function of the U32 filter is that it takes some block of data from the packet and compares it with the specified value. If the values match, then some actions are performed on the package. The data block in the packet is specified by the following parameters:
')
For example, take the following tc command example:
We add a u32 type filter with a priority of 10 to the eth: discipline 1: 0. And if the mapping is successful, the package will fall into the 1: 8 class. The seventh line is especially interesting to us, we will consider it in detail:
With these actions we check the source address (this can be seen if you look at the format of the IPv4 header), and if it belongs to the 192.168.1.0/24 subnet, then we send the packet to class 1: 8. Naturally, it is too tiring to constantly dig into the RFC, and it’s difficult to keep all the displacements in your head, so tc provides syntactic sugar for frequently used cases. For example, our example becomes much clearer if we write it like this:
You can specify several “match” parameters in one command, and the matching will be successful only if all the conditions are met. Let's send all packets with source address 192.168.1.0/24 and ToS value equal to 0x10 (interactive traffic) in class 1: 1:
Check if everything works correctly:
As you can see, everything works as it should - packages fall into the desired class. But if you look closely at the output of tc, then some moments are still unknown to us. For example, these mysterious values fh 800 :: 800. These are the so-called handles (tracing from the English "handle") - identifiers of filters inside U32.
Each handle of a separate filter consists of three hexadecimal numbers and is unique within the U32 filter space for the interface. In our case, this is handle 800 :: 800. We are now interested in only the last digit - the number of the added filter. If you do not specify it, the system itself assigns it - the next most senior one, starting from 0x800. The filter number ranges from 0x001 to 0xfff. You can manually specify the filter number with the appropriate parameter:
Filters are executed in the order of their numbers.
Suppose we add two filters:
Both filters will have the same prefix - the first two numbers of the handle (800: 0). If you imagine them written down one after another in the order of the number - the last number of the handle, you get a list of filters:
Since in the filters of one list the handles differ only in the last numbers, the list itself can be identified by the first two numbers of the handles - their prefix (800: 0). As previously mentioned, the filters are executed in the order they are followed. If the match was successful in any of the filters, then some action is performed and U32 exits. If we have reached the end of the list, and have not received a single successful match, the U32 filter will return the unclassified packet to the top.
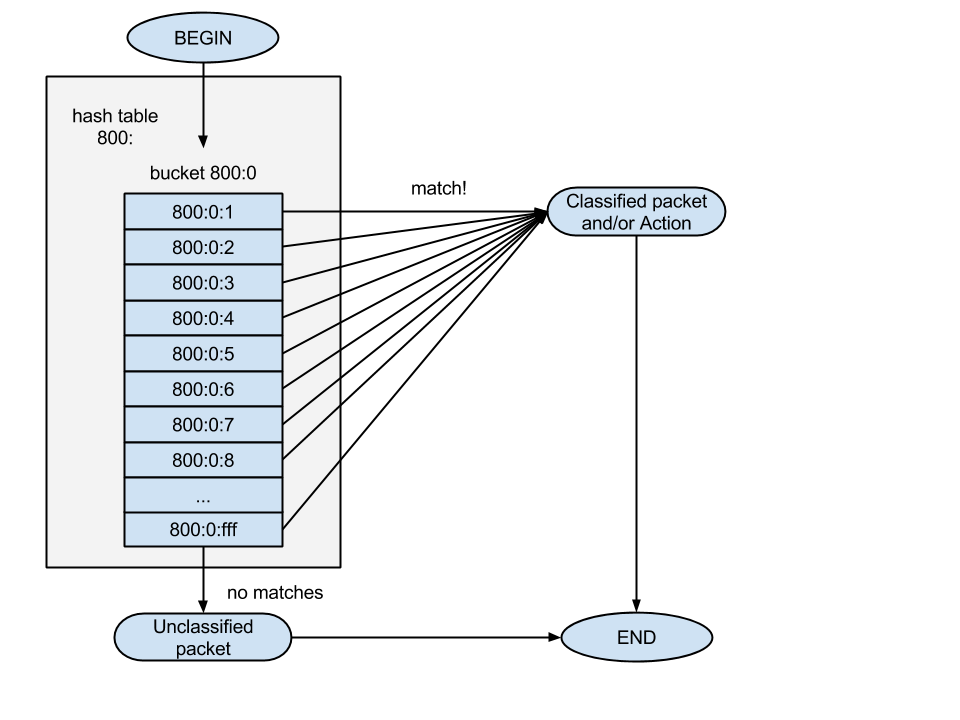
In addition to the classification, the action may be a transition to another list of filters to check the package. This is done using the “link” parameter instead of “classid” (even if the “classid” parameter is specified, it is still ignored), for example, like this:
If the packet has a source address from the subnet 192.168.1.0/24, then the filter list with the handle 1: 0 starts to be checked. If there are no successful matches in it, then we will return to the previous 800: 0 list and continue checking it. In turn, filters from the 1: 0 list can make transitions to other lists, and those to third ones, etc. And so up to seven transitions (for whom this is not enough, you can change the macro substitution of TC_U32_MAXDEPTH in the kernel sources).

It should also be noted that, on its own, splitting a large number of filters into multiple lists and organizing such transitions on average will not be much faster than checking a single large list. But, as a rule, the binding is used in conjunction with another mechanism of U32 - hashing.
Before that, we looked at filter lists. But in reality they are only part of a larger structure called a hash table. The hash table, in this case, is a one-dimensional array of cells (English array of buckets), each of which contains one filter list.
In the handles, the first number is the number of the hash table, and the second is the number of the cell. Hash table numbers range from 0x000 to 0xfff, and cells from 0x00 to 0xff. The number of cells can be from 1 to 256, and it should be a power of two (you will not be able to set another value — tc will give an error message). The hash table with the number 0x800 is called the root and consists of a single cell, it is created automatically. Checking a package always starts with a list in cell 800: 0.
You can create additional hash tables like this:
Where “handle 1:” sets the number of the hash table, and “divisor 1” is the number of cells in it (in this case, the hash table with number 1 has only one cell containing the 1: 0 filter list).
Let us extend our example with classification by source address and ToS field by navigating through the lists:
But with the help of the “link” parameter you can only go to the lists of filters located in the cell with the number 0. How then can you check the lists in other cells? For this, the hashkey parameter and the hashing mechanism are used. The meaning of hashing in U32 is that the system obtains the number of the cell to which it should go to the list based on the data from the packet. It is necessary to reduce the number of checks. Unlike the list, the viewing time of which linearly depends on the number of filters in it, hashing is performed in a constant time (and, quite short). Using a large number of filters using hashing allows you to achieve an order of magnitude greater performance than using lists and transitions alone.
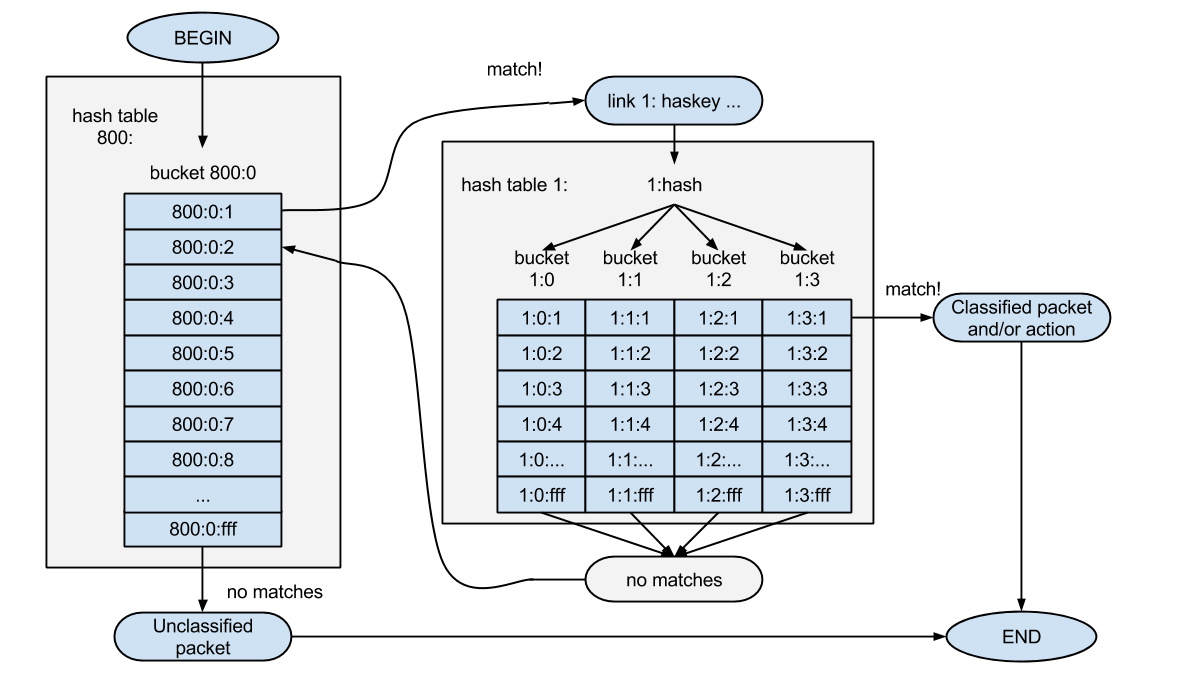
Rewrite our previous example using hashing:
Consider the hashing algorithm in our example. This algorithm was introduced in the 2.6 version of the kernel and has not changed so far (in the 2.4 kernel, the algorithm is different).
Unfortunately, tc does not provide any means to simplify writing offsets in this case, so it will not work to write something like “hashkey ip tos”. Another difficulty is the definition in which the named cell to place filters. There is only one way - manually count the hash (tc has the parameter “sample”, which allows you to automatically calculate the hash in order to place the filter in the desired cell, but the hashing algorithm is still not suitable for the 2.4 kernel and is not suitable for more recent kernels).
Everything would be simple if the headers had a fixed length. But, unfortunately, this is not the case - the headers may have additional optional elements, which makes it very difficult to match the header fields of the following levels. Fortunately, this is provided in U32. This function is called “header offsets” and is designed to find out the offset of the next header from the packet itself.
But first, let's take a look at two new notions of the U32 filter: constant displacement (for brevity, we will designate it as “permoff”) and temporal displacement (we will designate it as “tempoff”). The value of permoff is always added to all offsets in the next and further transitions performed using the “link” parameter, and is used to calculate the new values for permoff and tempoff. The value of tempoff is added only to the indicated offsets only at the next transition if the key word “nexthdr +” is used in the parameters, and does not affect further transitions. When returning back to the previous list, the values are “rolled back”.
Consider a small hypothetical example. Let permoff be zero when the list is 1: 0, and we have a successful match; and the new permoff value became equal to 20, and at the same time we moved to the implementation of the 2: 5 list. In this case, the value 20 will be added to all the specified offsets in the filters of the 2: 5 list. If we have another successful match in the 2: 5 list with the transition to the 3:12 list, and the change of the constant offset to 8 is indicated, the new the permoff value becomes 28. And when the 3:12 list is executed, the value 28 will be added to all offsets. If there are no successful matches in the 3:12 list, then U32 will go back to the 2: 5 list and permoff will again be equal to 20. If there will be no successful matches, and we will return to the 1: 0 list, then permoff will become equal again Nym zero. In fact, we simply shift the zero mark, relative to which we further indicate the offset. Initially, the permoff and tempoff values are zero.
Let's take a look at the RFC and look at the format of the IPv4 header. Fortunately for us, it provides a special field, the value of which is equal to the length of the title in double words. And we can use this information in order. to calculate the position of the next level heading.
This is done like this:
Consider in detail the last line and what happens when this happens:
After that, we can add to the list 1: 0 filters with a mapping of ICMP message type. For example, ICMP Echo-Request packets will be sent to class 1: 8.
In general, that's all. In the original you will find some more information - a dry guide and a list of comparisons (the very syntactic sugar).
Original - The u32 filter. - the author, unfortunately, is unknown to me, but everything points to Russell Stewart.
Matching
And so, the main function of the U32 filter is that it takes some block of data from the packet and compares it with the specified value. If the values match, then some actions are performed on the package. The data block in the packet is specified by the following parameters:
')
- The size of the data block. It is determined by the parameters u32 / u16 / u8. Intuitively, numbers are the block length in bits. The kernel operates with 32bit blocks. In tc, you can also set the block length to 8, 16, and 32 bits.
- Bit mask It is needed if you need to check not the entire data block, but only its individual bits. Naturally, the length of the mask should match the length of the block. A mask is applied to the block using the bitwise AND operation, and the result of this operation is already compared with the specified value.
- Offset from the beginning of the package. All offsets are aligned at the 32-bit boundary. Here, not everything is as obvious as it seems, and we'll talk about it later, but for now this simplification is enough. An offset of zero, in most cases, corresponds to the beginning of the header of the network layer, i.e. top of the ipv4 / ipv6 packet.
For example, take the following tc command example:
tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ u32 \ match u32 0xc0a80100 0xffffff00 at 12 \ classid 1:8 We add a u32 type filter with a priority of 10 to the eth: discipline 1: 0. And if the mapping is successful, the package will fall into the 1: 8 class. The seventh line is especially interesting to us, we will consider it in detail:
- match u32 - sets the beginning of the match condition and the size of the data block that will be taken from the packet.
- 0xc0a80100 is the value with which we will compare the bits from the packet.
- 0xffffff00 is a bitmask that will be superimposed on the data from the packet, and the result will already be compared with what we specified. If our value and masked data block are equal, then certain actions are performed. Most often, this action will be the classification of the package.
- at 12 - the offset from the beginning, which is the beginning of the data block. If this parameter is not specified, then the offset is considered to be zero. At the very beginning of the filter, the zero border is considered the beginning of the network layer header, for example, IPv4. Negative displacements are also possible.
With these actions we check the source address (this can be seen if you look at the format of the IPv4 header), and if it belongs to the 192.168.1.0/24 subnet, then we send the packet to class 1: 8. Naturally, it is too tiring to constantly dig into the RFC, and it’s difficult to keep all the displacements in your head, so tc provides syntactic sugar for frequently used cases. For example, our example becomes much clearer if we write it like this:
tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ u32 \ match ip src 192.168.1.0/24 \ classid 1:8 You can specify several “match” parameters in one command, and the matching will be successful only if all the conditions are met. Let's send all packets with source address 192.168.1.0/24 and ToS value equal to 0x10 (interactive traffic) in class 1: 1:
tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ u32 \ match ip src 192.168.1.0/24 \ match ip tos 0x10 0x1e \ classid 1:1 Check if everything works correctly:
# ~$ tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1911 success 0) match c0a80100/ffffff00 at 12 (success 0 ) match 00100000/001e0000 at 0 (success 0 ) # -p, tc # , - ~$ tc -s -pf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 3413 success 0) match IP src 192.168.1.0/24 (success 0 ) (success 0 ) # - ToS $ ping -f -I 192.168.1.1 -Q 0x10 www.ya.ru PING ya.ru (93.158.134.3) from 192.168.1.1 : 56(84) bytes of data. --- ya.ru ping statistics --- 107 packets transmitted, 107 received, 0% packet loss, time 619ms rtt min/avg/max/mdev = 4.492/5.240/7.560/0.536 ms, ipg/ewma 5.842/5.403 ms #, ~$ tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 354903 success 107) match c0a80100/ffffff00 at 12 (success 107 ) match 00100000/001e0000 at 0 (success 107 ) As you can see, everything works as it should - packages fall into the desired class. But if you look closely at the output of tc, then some moments are still unknown to us. For example, these mysterious values fh 800 :: 800. These are the so-called handles (tracing from the English "handle") - identifiers of filters inside U32.
Each handle of a separate filter consists of three hexadecimal numbers and is unique within the U32 filter space for the interface. In our case, this is handle 800 :: 800. We are now interested in only the last digit - the number of the added filter. If you do not specify it, the system itself assigns it - the next most senior one, starting from 0x800. The filter number ranges from 0x001 to 0xfff. You can manually specify the filter number with the appropriate parameter:
tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::1 \ u32 \ match ip src 192.168.1.0/24 \ match ip tos 0x10 0x1e \ classid 1:1 Filters are executed in the order of their numbers.
Binding
Suppose we add two filters:
tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::1 \ u32 \ match ip src 192.168.1.0/24 \ match ip tos 0x10 0x1e \ classid 1:1 tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::2 \ u32 \ match ip src 192.168.1.0/24 \ match ip tos 0x08 0x1e \ classid 1:2 Both filters will have the same prefix - the first two numbers of the handle (800: 0). If you imagine them written down one after another in the order of the number - the last number of the handle, you get a list of filters:
800 list: 0: :: 1 - ip src 192.168.1.0/24 tos 0x10 -> classid 1: 1 :: 2 - ip src 192.168.1.0/24 tos 0x08 -> classid 1: 2
Since in the filters of one list the handles differ only in the last numbers, the list itself can be identified by the first two numbers of the handles - their prefix (800: 0). As previously mentioned, the filters are executed in the order they are followed. If the match was successful in any of the filters, then some action is performed and U32 exits. If we have reached the end of the list, and have not received a single successful match, the U32 filter will return the unclassified packet to the top.
In addition to the classification, the action may be a transition to another list of filters to check the package. This is done using the “link” parameter instead of “classid” (even if the “classid” parameter is specified, it is still ignored), for example, like this:
tc filter add \ dev eth0 \ parent 1: \ prio 10 \ protocol ip \ handle ::2 \ u32 \ match ip src 192.168.1.0/24 \ link 1: If the packet has a source address from the subnet 192.168.1.0/24, then the filter list with the handle 1: 0 starts to be checked. If there are no successful matches in it, then we will return to the previous 800: 0 list and continue checking it. In turn, filters from the 1: 0 list can make transitions to other lists, and those to third ones, etc. And so up to seven transitions (for whom this is not enough, you can change the macro substitution of TC_U32_MAXDEPTH in the kernel sources).
It should also be noted that, on its own, splitting a large number of filters into multiple lists and organizing such transitions on average will not be much faster than checking a single large list. But, as a rule, the binding is used in conjunction with another mechanism of U32 - hashing.
Hashing
Before that, we looked at filter lists. But in reality they are only part of a larger structure called a hash table. The hash table, in this case, is a one-dimensional array of cells (English array of buckets), each of which contains one filter list.
In the handles, the first number is the number of the hash table, and the second is the number of the cell. Hash table numbers range from 0x000 to 0xfff, and cells from 0x00 to 0xff. The number of cells can be from 1 to 256, and it should be a power of two (you will not be able to set another value — tc will give an error message). The hash table with the number 0x800 is called the root and consists of a single cell, it is created automatically. Checking a package always starts with a list in cell 800: 0.
You can create additional hash tables like this:
tc filter add \ dev eth0 \ parent 1: pref 10 \ protocol ip \ handle 1: \ u32 divisor 1 Where “handle 1:” sets the number of the hash table, and “divisor 1” is the number of cells in it (in this case, the hash table with number 1 has only one cell containing the 1: 0 filter list).
Let us extend our example with classification by source address and ToS field by navigating through the lists:
# prio ~$ tc q add \ dev eth0 \ root \ est 0.1s 10s \ handle 1: \ prio bands 8 # - 1: ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle 1: \ u32 \ divisor 1 # - ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::1 \ u32 \ match ip src 192.168.1.0/24 \ link 1: # ToS - 1: ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::1 \ u32 \ ht 1: \ match ip tos 0x08 0x1e \ classid 1:3 ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::2 \ u32 \ ht 1: \ match ip tos 0x10 0x1e \ classid 1:1 # , , #, ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::2 \ u32 \ match ip src 192.168.1.0/24 \ classid 1:7 # ~$ tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 1: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 1::1 order 1 key ht 1 bkt 0 flowid 1:3 (rule hit 0 success 0) match 00080000/001e0000 at 0 (success 0 ) filter parent 1: protocol ip pref 10 u32 fh 1::2 order 2 key ht 1 bkt 0 flowid 1:1 (rule hit 0 success 0) match 00100000/001e0000 at 0 (success 0 ) filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::1 order 1 key ht 800 bkt 0 link 1: (rule hit 33900 success 0) match c0a80100/ffffff00 at 12 (success 0 ) filter parent 1: protocol ip pref 10 u32 fh 800::2 order 2 key ht 800 bkt 0 flowid 1:7 (rule hit 3583 success 0) match c0a80100/ffffff00 at 12 (success 0 ) # , #ToS 192.168.1.0/24, ~$ ping -fc10 -I 192.168.1.1 -Q 0x08 8.8.8.8 ~$ ping -fc15 -I 192.168.1.1 -Q 0x10 www.kernel.org ~$ ping -fc25 -I 192.168.1.1 -Q 0xaa www.habrahabr.ru # ~$ tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 1: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 1::1 order 1 key ht 1 bkt 0 flowid 1:3 (rule hit 50 success 10) match 00080000/001e0000 at 0 (success 10 ) filter parent 1: protocol ip pref 10 u32 fh 1::2 order 2 key ht 1 bkt 0 flowid 1:1 (rule hit 40 success 15) match 00100000/001e0000 at 0 (success 15 ) filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::1 order 1 key ht 800 bkt 0 link 1: (rule hit 578192 success 0) match c0a80100/ffffff00 at 12 (success 50 ) filter parent 1: protocol ip pref 10 u32 fh 800::2 order 2 key ht 800 bkt 0 flowid 1:7 (rule hit 547850 success 25) match c0a80100/ffffff00 at 12 (success 25 ) But with the help of the “link” parameter you can only go to the lists of filters located in the cell with the number 0. How then can you check the lists in other cells? For this, the hashkey parameter and the hashing mechanism are used. The meaning of hashing in U32 is that the system obtains the number of the cell to which it should go to the list based on the data from the packet. It is necessary to reduce the number of checks. Unlike the list, the viewing time of which linearly depends on the number of filters in it, hashing is performed in a constant time (and, quite short). Using a large number of filters using hashing allows you to achieve an order of magnitude greater performance than using lists and transitions alone.
Rewrite our previous example using hashing:
# - 1: 32 ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle 1: \ u32 \ divisor 32 # ToS ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle 1:08:1 \ u32 \ ht 1:08 \ match u32 0 0 \ classid 1:3 ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle 1:10:1 \ u32 \ ht 1:10 \ match u32 0 0 \ classid 1:1 # 192.168.1.0/24 # - 1: ToS ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::1 \ u32 \ match ip src 192.168.1.0/24 \ link 1: \ hashkey mask 0x001f0000 at 0 # , # ~$ tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle ::2 \ u32 \ match ip src 192.168.1.0/24 \ classid 1:7 # ToS ~$ ping -fc10 -I 192.168.1.1 -Q 0x08 8.8.8.8 ~$ ping -fc30 -I 192.168.1.1 -Q 0x10 www.kernel.org ~$ ping -fc50 -I 192.168.1.1 -Q 0xaa www.habrahabr.ru # ~$ tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 1: ht divisor 32 filter parent 1: protocol ip pref 10 u32 fh 1:8:1 order 1 key ht 1 bkt 8 flowid 1:3 (rule hit 10 success 10) match 00000000/00000000 at 0 (success 10 ) filter parent 1: protocol ip pref 10 u32 fh 1:10:1 order 1 key ht 1 bkt 10 flowid 1:1 (rule hit 30 success 30) match 00000000/00000000 at 0 (success 30 ) filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::1 order 1 key ht 800 bkt 0 link 1: (rule hit 30135 success 0) match c0a80100/ffffff00 at 12 (success 90 ) hash mask 001f0000 at 0 filter parent 1: protocol ip pref 10 u32 fh 800::2 order 2 key ht 800 bkt 0 flowid 1:7 (rule hit 27250 success 50) match c0a80100/ffffff00 at 12 (success 50 ) Consider the hashing algorithm in our example. This algorithm was introduced in the 2.6 version of the kernel and has not changed so far (in the 2.4 kernel, the algorithm is different).
- Take a 32-bit word at the “at” offset specified in the “hashkey” parameter. Since we have zero offset, the first 32 bits of the IP packet are taken.
- Put a bit mask on it from the same parameter. Our bitmask is “0x001f0000”, which corresponds to the position of the ToS field.
- The result is shifted to the low-order bits by n-bit. The value of n is calculated from the mask and is equal to the number of lower zero bits in it. In our mask, the number of low zero bits is 16, which means the masked double word will be shifted to these 16 bits. After that, the ToS value will appear in the lower five digits.
- On the resulting value to impose a mask 0xff. In this case, it will not change anything. In other cases, this will reset all octets except the minor.
- And at the end, if the target table has less than 256 cells, a bit mask equal to the number k is superimposed on the result. The value of k is one less than the cells in the hash table to which the transition will be. In our target table there are 32 cells, which means the value of k will be equal to 31. After applying this mask, our result is guaranteed not to be more than the number of cells.
Unfortunately, tc does not provide any means to simplify writing offsets in this case, so it will not work to write something like “hashkey ip tos”. Another difficulty is the definition in which the named cell to place filters. There is only one way - manually count the hash (tc has the parameter “sample”, which allows you to automatically calculate the hash in order to place the filter in the desired cell, but the hashing algorithm is still not suitable for the 2.4 kernel and is not suitable for more recent kernels).
Offsets
Everything would be simple if the headers had a fixed length. But, unfortunately, this is not the case - the headers may have additional optional elements, which makes it very difficult to match the header fields of the following levels. Fortunately, this is provided in U32. This function is called “header offsets” and is designed to find out the offset of the next header from the packet itself.
But first, let's take a look at two new notions of the U32 filter: constant displacement (for brevity, we will designate it as “permoff”) and temporal displacement (we will designate it as “tempoff”). The value of permoff is always added to all offsets in the next and further transitions performed using the “link” parameter, and is used to calculate the new values for permoff and tempoff. The value of tempoff is added only to the indicated offsets only at the next transition if the key word “nexthdr +” is used in the parameters, and does not affect further transitions. When returning back to the previous list, the values are “rolled back”.
Consider a small hypothetical example. Let permoff be zero when the list is 1: 0, and we have a successful match; and the new permoff value became equal to 20, and at the same time we moved to the implementation of the 2: 5 list. In this case, the value 20 will be added to all the specified offsets in the filters of the 2: 5 list. If we have another successful match in the 2: 5 list with the transition to the 3:12 list, and the change of the constant offset to 8 is indicated, the new the permoff value becomes 28. And when the 3:12 list is executed, the value 28 will be added to all offsets. If there are no successful matches in the 3:12 list, then U32 will go back to the 2: 5 list and permoff will again be equal to 20. If there will be no successful matches, and we will return to the 1: 0 list, then permoff will become equal again Nym zero. In fact, we simply shift the zero mark, relative to which we further indicate the offset. Initially, the permoff and tempoff values are zero.
Let's take a look at the RFC and look at the format of the IPv4 header. Fortunately for us, it provides a special field, the value of which is equal to the length of the title in double words. And we can use this information in order. to calculate the position of the next level heading.
This is done like this:
tc filter add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ u32 \ match ip src 192.168.1.0/24 \ match protocol 0x01 0xff \ link 1: \ offset at 0 mask 0x0f00 shift 6 plus 0 eat Consider in detail the last line and what happens when this happens:
- offset - indicates that we change the values of permoff or tempoff upon successful matching.
- A single word is taken at the offset specified in the "at" parameter. In our case, it is zero, so the first 16 bits of the packet will be taken. The value of the “at” parameter is reduced to a multiple of two.
- A bitmask is superimposed on the value received from the packet. In our case, it is equal to 0x0f00, which corresponds to the position of the IPv4 header length field. Suppose that we have the value 5 in this field (in binary representation 0101). In binary format, the result of previous operations will be equal to "0000.0101.0000.0000".
- We know that the value of the IP header length field is equal to the length of the header in double words. So, you need to somehow convert the resulting value to bytes. The matter is complicated by the fact that as a result, the necessary bits are additionally shifted. Shift the value so that it is in the lower octets - move it towards the lower bits by 8 bits and get “0000.0000.0000.0101”. Now multiply this by 4, since the size of the title is specified in double words. Multiplication is replaced by a shift towards higher bits by 2 bits. After the shift, we get "0000.0000.0001.0100". We got the right value. Combine both shift operations into one. As a result, to get the length of the header in bytes, we will need to shift the original masked value by six bits in the direction of the lower digits. This is done using the “shift” parameter. After all operations, we got the value 20.
- The value of the parameter “plus” is added to the value obtained. In our case, this is 0, so nothing is added. You could not even specify this parameter.
- The “eat” parameter says that the computed value is added to the permoff value. Otherwise, the tempoff value will be calculated.
- As a result, when checking filters from the 1: 0 list, the zero offset will correspond to the beginning of the next header, and we can build filters based on matching ICMP header fields, for example, checking the message type values. If you change the tempoff value, then you should explicitly specify it in the called list, using the keyword “nexthdr +” to set the offsets.
After that, we can add to the list 1: 0 filters with a mapping of ICMP message type. For example, ICMP Echo-Request packets will be sent to class 1: 8.
~$tc f add \ dev eth0 \ parent 1: \ pref 10 \ protocol ip \ handle 1::1 \ u32 \ ht 1: \ match u8 0x08 0xff \ classid 1:8 # ~$ sudo tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 1: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 1::1 order 1 key ht 1 bkt 0 flowid 1:8 (rule hit 0 success 0) match 08000000/ff000000 at 0 (success 0 ) filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::1 order 1 key ht 800 bkt 0 link 1: (rule hit 48553 success 0) match c0a80100/ffffff00 at 12 (success 0 ) match 00010000/00ff0000 at 8 (success 0 ) offset 0f00>>6 at 0 eat # - ~$ ping -fc5 -I 192.168.1.1 www.ixbt.com # ~$ tc -sf ls dev eth0 filter parent 1: protocol ip pref 10 u32 filter parent 1: protocol ip pref 10 u32 fh 1: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 1::1 order 1 key ht 1 bkt 0 flowid 1:8 (rule hit 5 success 5) match 08000000/ff000000 at 0 (success 5 ) filter parent 1: protocol ip pref 10 u32 fh 800: ht divisor 1 filter parent 1: protocol ip pref 10 u32 fh 800::1 order 1 key ht 800 bkt 0 link 1: (rule hit 149972 success 0) match c0a80100/ffffff00 at 12 (success 5 ) match 00010000/00ff0000 at 8 (success 5 ) offset 0f00>>6 at 0 eat In general, that's all. In the original you will find some more information - a dry guide and a list of comparisons (the very syntactic sugar).
Original - The u32 filter. - the author, unfortunately, is unknown to me, but everything points to Russell Stewart.
Source: https://habr.com/ru/post/138463/
All Articles