Learning to write a kernel module (Netfilter) or Transparent Proxy for HTTPS
This article is aimed at readers who are starting or just want to start programming Linux kernel modules and network applications. It can also help to deal with transparent proxying of HTTPS traffic.
A small table of contents so that you can assess whether to read further:
PS For those who just want to look at a transparent proxy server for HTTP and HTTPS, just set up a transparent proxy server for HTTP , for example, Squid with a transparent port 3128, and download the Shifter source archive . Compile (make) and, after successful compilation, execute ./Start with root rights. If necessary, you can correct the settings in shifter.h before compiling.
Like all beginners in the field of IT wanted to dig a little bit in the core. Here and the area for experiments appeared by itself. If you look at Google, you can see that if no one has problems with a transparent proxy server for HTTP, then in the case of HTTPS some people are sure that there is no transparent proxy for the HTTPS protocol. And it will never be. All this served the appearance of this article.
To begin, consider some aspects of the proxy server that we need. When the browser directly accesses the HTTP server, it creates the following typical request:
When we specify a proxy server in the browser settings, the browser starts to connect to the proxy server, and sends it a request with the full address:
If the proxy server receives a request with an incomplete address, as in the first case, it may not know to whom this request is intended and will return an error.
I will say a few words about HTTPS. The browser establishes a tcp connection and, using the SSL protocol: exchanges certificates and transmits encrypted HTTP traffic. Since the SSL protocol is designed to ensure that no one can read the transmitted data in the middle, the proxy server cannot, as in the case of HTTP, find out with whom it should establish a connection. To transmit data over HTTPS through a proxy server, the browser must inform the proxy server with whom it wants to connect using the HTTP method CONNECT:
To which the proxy server must respond that the connection is successfully established:
As a result, the browser receives a direct tcp connection through a proxy server, in which it can transmit absolutely any data. A proxy server is engaged only in the exact transfer of data from the tcp connection established with the browser to the tcp connection established with the specified host in the CONNECT method, and, accordingly, the reverse transfer.
When transparent proxying is used, i.e. If the browser does not even suspect the existence of a proxy server, then the browser will not prepare its data so beautifully. And the proxy server will have to think about it.
Schematically take a look at the transparent proxy for HTTP:

Here, of course, there are inaccuracies, for example, a proxy, receiving a packet to its port 3128, does not pass it on to Google, but creates a new connection with Google, but, in general, the interaction scheme is approximately the same. In this scheme, it is clear that NAT is starting to send packets to the proxy server, which are not intended for it, and it needs to know who it is to send them. In the case of HTTP traffic, some proxy servers incorrectly begin to use information from the HOST field of the HTTP request header, violating the specification. Most often, of course, HOST contains exactly the name of the host to which the request is addressed, but, in general, HOST can contain anything. For HTTPS, this solution is not suitable at all. To find out who the packet is addressed to, it immediately suggests a solution in which the proxy server would look in NAT and look at who the data were intended for and then there would be no problem. That's actually what we do.
Unfortunately, iptables itself is not useful, but the basic principles of its operation will be well understood. Schematically it will look like this:
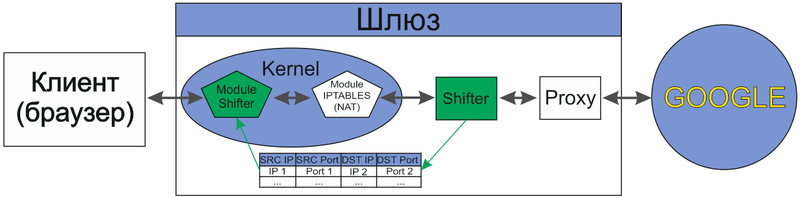
For the intended purposes, it will be enough to write a tiny kernel module (Module Shifter) and implement a small software layer (Shifter) in the user space to interact with our module, which will prepare the data for the proxy server.
Let's write a small client-server application, which I called Shifter. Shifter will hang on its port and when someone establishes a tcp connection with it, it will create a tcp connection with the proxy server and send it a CONNECT (HTTP) method, and then it will only deal with the exact transfer of data between these two connections. If the client or proxy closes the connection with it, it will close this pair of sockets.
To send a CONNECT method, you need the ip address of the remote node with which the client actually wanted to establish a connection. To obtain this information, the Shifter will communicate with the kernel module (Module Shifter) using the Netlink library. This will be discussed in the last part of this article.
With this application, we will prepare a proxy server for receiving data (HTTPS) from a client that does not know anything about the proxy server. Since there are many resources where it is written in detail about sockets, here I will only provide a link to a part of the Shifter source code with detailed comments .
')
In order to find out what a kernel module is, you can read, for example, Working with kernel modules in Linux . Let's start writing the module. First you need to perform initialization of the module, which will occur once, when the module will be loaded into the kernel. You should also perform a correct shutdown of the module in order not to leave any unnecessary traces of the past presence when the module is unloaded from the kernel. For these purposes, the library <linux / module.h>: <linux / init.h> has two macros module_init and module_exit , which take the name of the function for this purpose as a parameter. There are also MODULE_AUTHOR , MODULE_DESCRIPTION , MODULE_LICENSE macros to perpetuate your name :) There is also a very useful int printk output function (const char * fmt, ...) in the <linux \ kernel.h> library: <linux \ printk.h> . It is not much different from the usual printf (..) . Since the module is located in the kernel, and is not running in the console, the messages are respectively output to the logs (you can use the dmesg command to view). Messages can be displayed in various types:
Now we have all the information to write the frame of our first module:
I'll tell you a little more about how to compile and run all this. I have to say that I have Ubuntu 11.10 (x86) Kernel 3.0 installed.
The system has a directory / lib / modules / [kernel version] / it contains modules for the corresponding kernel version. Also there is a build - this is a symbolic link to the headers of the kernel libraries (kernel-headers), which are located in the / usr / src / linux-headers- [kernel version] / directory. If you do not already have kernel headers, then you need to download them ( sudo apt-get install linux-headers- [kernel version] ). To find out the version of the current kernel you are working in, you can issue the uname –r command. If you use a library with a version different from the version of the current kernel, then such a compiled module may work fine, or it may not start at best. It all depends on what changes have occurred in the kernel, and what you use in the function module.
To compile the module, write the Makefile . Let's create two goals: all (build the module) and clean (clean the project), for writing we will use the goals already written for us: modules and clean in the Makefile from the kernel-headers .
Now we can easily compile the module using the make command and clean the make clean project. As a result, we get a ready-made module module_test.ko , which can be immediately loaded into the kernel using the insmod command ./module_test.ko . There is another option for loading a module into the kernel - with the modprobe module_test command . To do this, put the module module_test.ko in the directory / lib / modules / [current kernel version] / [any directory] / and do not forget to run depmod , since This command creates a list of module dependencies in / lib / modules / . Even if the module has no dependencies, modprobe will not see the added module without depmod . The main differences between insmod and modprobe are as follows: modprobe automatically loads all modules on which it depends upon loading a module, but insmod can load a module from any directory. Remove module from kernel: rmmod module_test . View information about the module: modinfo module_test or modinfo ./module_test.ko .
And so back to the proxy for https. Our task is to make the module view the network packets before DNAT (iptables) processes them. The Netfilter library will help us for this . (For a more detailed understanding, I recommend further reading about Netfilter in other sources, at least on Wikipedia ) Consider what the path of a network package looks like in the kernel:

More details can be found here .
Netfilter <linux / netfilter.h> provides 5 hook functions that give access to a network package in 5 different places:
The kernel module can register its function in any of these 5 places. When registering, the module must indicate the priority of its function in this place. In the library <linux / netfilter_ipv4.h> you can find priority for various standard tasks:
The list shows that DNAT has a priority of -100, so any priority <-100 is suitable for our purpose. If the priority of the function is> -100, then it will receive packets with the already changed IP address of the destination (recipient).
Each registered function in any of the 5 points must return one of the following values, which determines the further fate of the packet passed to it:
In my free translation it will sound like this:In this case, iteration is the transition of a packet from a function to a function, since At one point many functions can be registered, which in turn can be divided by priorities.
With the theory figured out, now we continue to write the module. When a module is loaded into the kernel, you need to register the function, call it Hook_Func , which will scan all incoming packets, and upon completion, you must unregister this function, otherwise the kernel will try to call a non-existent function.
Now all we have to do is write the function Hook_Func . It should have the following prototype:
Consider its parameters:
Now more about the pointer to the packet struct sk_buff * skb .
When working with tcp, you can use two more structures - this is a struct iphdr and a struct tcphdr .
As the name implies, these structures are designed to work with the IP header and, accordingly, with the TCP header . To get pointers to these structures from skb_buff, you can use two functions:
In this place I would like to appeal to the reader. It remains unclear to me exactly who should set the transport_header pointer in the sk_buff structure, since at the NF_INET_PRE_ROUTING and NF_INET_LOCAL_IN points (with any priorities) I could not get a structure on the tcp header using skb_transport_header , although it worked perfectly at the other points. I had to manually specify the offset for transport_header from the pointer sk_buff-> data , using the void skb_set_transport_header (skb, offset) .
The sk_buff-> data pointer is a pointer to the package contents, i.e. points to the memory area after the Ethernet protocol, for example, immediately to the IP header structure, and then it can be followed by the TCP header structure or your own protocol.
Since pointers to data in the package itself are used everywhere, it is possible not only to read various fields, but also to change them. However, it must be remembered that when changing, for example, the IP address of the sender or recipient, it is necessary to recalculate the checksum in the IP packet header.
And so, our function will save the destination IP address only when it sees the IP-TCP packet going to port 443 (HTTPS) and containing the SYN flag, which says that the client wants to establish a TCP connection for the HTTPS protocol. And delete when packets containing FIN or RST flags appear that say that the tcp connection is broken and we do not need this IP address anymore.
There are two functions AddTable and DelTable , which should save and delete the recipient's IP address from memory, for each IP and port of the sender. This is necessary so that the client-server Shifter can communicate with the Shifter module and use the ReadTable function to find out by the client's IP and port what IP address he really wanted to contact. I didn’t think much about the data type to save the IP and used the usual static array using the elementary hash function. The hash function ( KeyHash ) receives at the input ip and the port of the sender and returns the index of the array where the ip destination address is stored. It is written taking into account the fact that the client is behind the nat and has a subnet with a mask of 255.255.255.0, so I use only the last byte of the sender's ip, and this byte is also superimposed by 3 bits on two bytes of the port. As a result, I managed to compress the array to a size of 0x1FFFFF (~ 8 MB). Of course, you need to take into account that now, after loading into the kernel, this module will take at least 8 MB of memory, and this may be too much for some embedded systems. And we don’t forget about the collision :) But for my demo, it all pays off with simplicity and, in addition, DelTable is completely empty.
That’s the end of the article, and the only thing left is to connect the client-server Shifter with the core module Shifter.
Now our goal is to create one socket in the Shifter and in the Shifter module and connect them together. The exchange protocol between the module and the Shifter server will be simple. Shifter will send 4 bytes of client IP and 2 bytes of client port, and the module will respond with 4 bytes of IP destination, taken from its table. To do this, use the library Netlink.
I want to note that the header <linux / netlink.h> for user applications is /usr/include/linux/netlink.h and for kernel modules is / usr / src / linux-headers- [kernel version] / include / linux / netlink. h has many differences .
With regard to netlink from the user space in the network a lot of information, for example, here:
RFC 3549 - Linux Netlink as a protocol for IP services
Working with NetLink on Linux. Part 1
A simple monitor of Linux network interfaces, using netlink.
Therefore, here I will tell only what we need to ensure the exchange of information between the kernel module and user-space programs.
Netlink socket is created by the usual function: int socket (PF_NETLINK, socket_type, netlink_family);
Where as socket_type can be used as SOCK_RAW , and SOCK_DGRAM ; nevertheless, the netlink protocol does not draw the line between datagram and raw sockets. And netlink_family selects a kernel module or netlink group for communication. The <linux / netlink.h> , you can view the complete list of families .
Netlink messages are a stream of bytes with one or more nlmsghdr headers (netlink message header). To access byte streams, only NLMSG_ * macros should be used . I also want to note that the netlink protocol does not provide guaranteed message delivery. If there is a shortage of memory or other errors, the protocol may drop packets.
Consider the sockaddr_nl, nlmsghdr (<linux / netlink.h>), iovec and msghdr (<sys / socket.h>) structures that we will work with:

struct sockaddr_nl - describes the netlink addresses for user programs and kernel modules. The structure is used to describe the sender or recipient of the data.
struct nlmsghdr is the netlink message header and immediately after the structure the sent / received data is located in the memory, to access it, use the NLMSG_DATA (struct nlmsghdr *) macro.
struct iovec - located in msghdr , it will contain a pointer to the nlmsghdr structure .
struct msghdr - contains a pointer to the address ( sockaddr_nl ) and data ( iovec )
Consider some Netlink macros:
Part of the source code of the server Shifter with Netlink.
When using the netlink library in kernel modules, there are some differences, for example, the nlmsghdr structure from <linux / netlink.h> remains the same, but is already wrapped in the well-known sk_buff structure . And instead of the usual functions for working with sockets, we will use a new set of functions. Consider some of them.
In a module, a socket is not represented as an int type , but as a sock structure from <net / sock.h> . struct sock is a very big one I will not describe it, besides its description is not needed.
To create a netlink socket, <linux / netlink.h> has the function netlink_kernel_create . It not only creates a netlink socket, but also registers a function that will be called whenever data arrives.
To close the netlink socket and remove the "registration function" use:
We also need functions from <net / netlink.h> , there you can find functions with an amazing description.
I will simply translate some of the necessary functions:
It remains to add Module Shifter.
In conclusion, in order to redirect packets to the proxy server, it is enough to add a rule to iptables on the gateway:
Download Shifter source archive
NetFilter.org
Linux, Kernel, Firewall
Kernel Korner -
Linking Netlink as a protocol for IP services
Working with NetLink on Linux. Part 1
Linux netlink protocol
A small table of contents so that you can assess whether to read further:
- How does the proxy server. Formulation of the problem.
- Client is a server application using non-blocking sockets.
- Writing a kernel module using the Netfilter library.
- Interaction with kernel module from user space (Netlink)
PS For those who just want to look at a transparent proxy server for HTTP and HTTPS, just set up a transparent proxy server for HTTP , for example, Squid with a transparent port 3128, and download the Shifter source archive . Compile (make) and, after successful compilation, execute ./Start with root rights. If necessary, you can correct the settings in shifter.h before compiling.
Formulation of the problem
Like all beginners in the field of IT wanted to dig a little bit in the core. Here and the area for experiments appeared by itself. If you look at Google, you can see that if no one has problems with a transparent proxy server for HTTP, then in the case of HTTPS some people are sure that there is no transparent proxy for the HTTPS protocol. And it will never be. All this served the appearance of this article.
To begin, consider some aspects of the proxy server that we need. When the browser directly accesses the HTTP server, it creates the following typical request:
GET / HTTP/1.1 Host: www.google.ru … When we specify a proxy server in the browser settings, the browser starts to connect to the proxy server, and sends it a request with the full address:
GET http://www.google.ru/ HTTP/1.1 Host: www.google.ru … If the proxy server receives a request with an incomplete address, as in the first case, it may not know to whom this request is intended and will return an error.
I will say a few words about HTTPS. The browser establishes a tcp connection and, using the SSL protocol: exchanges certificates and transmits encrypted HTTP traffic. Since the SSL protocol is designed to ensure that no one can read the transmitted data in the middle, the proxy server cannot, as in the case of HTTP, find out with whom it should establish a connection. To transmit data over HTTPS through a proxy server, the browser must inform the proxy server with whom it wants to connect using the HTTP method CONNECT:
CONNECT mail.google.com:443 HTTP/1.1 Host: mail.google.com … To which the proxy server must respond that the connection is successfully established:
HTTP/1.0 200 Connection established As a result, the browser receives a direct tcp connection through a proxy server, in which it can transmit absolutely any data. A proxy server is engaged only in the exact transfer of data from the tcp connection established with the browser to the tcp connection established with the specified host in the CONNECT method, and, accordingly, the reverse transfer.
When transparent proxying is used, i.e. If the browser does not even suspect the existence of a proxy server, then the browser will not prepare its data so beautifully. And the proxy server will have to think about it.
Schematically take a look at the transparent proxy for HTTP:
Here, of course, there are inaccuracies, for example, a proxy, receiving a packet to its port 3128, does not pass it on to Google, but creates a new connection with Google, but, in general, the interaction scheme is approximately the same. In this scheme, it is clear that NAT is starting to send packets to the proxy server, which are not intended for it, and it needs to know who it is to send them. In the case of HTTP traffic, some proxy servers incorrectly begin to use information from the HOST field of the HTTP request header, violating the specification. Most often, of course, HOST contains exactly the name of the host to which the request is addressed, but, in general, HOST can contain anything. For HTTPS, this solution is not suitable at all. To find out who the packet is addressed to, it immediately suggests a solution in which the proxy server would look in NAT and look at who the data were intended for and then there would be no problem. That's actually what we do.
Unfortunately, iptables itself is not useful, but the basic principles of its operation will be well understood. Schematically it will look like this:
For the intended purposes, it will be enough to write a tiny kernel module (Module Shifter) and implement a small software layer (Shifter) in the user space to interact with our module, which will prepare the data for the proxy server.
Client - server application (Shifter)
Let's write a small client-server application, which I called Shifter. Shifter will hang on its port and when someone establishes a tcp connection with it, it will create a tcp connection with the proxy server and send it a CONNECT (HTTP) method, and then it will only deal with the exact transfer of data between these two connections. If the client or proxy closes the connection with it, it will close this pair of sockets.
To send a CONNECT method, you need the ip address of the remote node with which the client actually wanted to establish a connection. To obtain this information, the Shifter will communicate with the kernel module (Module Shifter) using the Netlink library. This will be discussed in the last part of this article.
With this application, we will prepare a proxy server for receiving data (HTTPS) from a client that does not know anything about the proxy server. Since there are many resources where it is written in detail about sockets, here I will only provide a link to a part of the Shifter source code with detailed comments .
')
Kernel module shifter
In order to find out what a kernel module is, you can read, for example, Working with kernel modules in Linux . Let's start writing the module. First you need to perform initialization of the module, which will occur once, when the module will be loaded into the kernel. You should also perform a correct shutdown of the module in order not to leave any unnecessary traces of the past presence when the module is unloaded from the kernel. For these purposes, the library <linux / module.h>: <linux / init.h> has two macros module_init and module_exit , which take the name of the function for this purpose as a parameter. There are also MODULE_AUTHOR , MODULE_DESCRIPTION , MODULE_LICENSE macros to perpetuate your name :) There is also a very useful int printk output function (const char * fmt, ...) in the <linux \ kernel.h> library: <linux \ printk.h> . It is not much different from the usual printf (..) . Since the module is located in the kernel, and is not running in the console, the messages are respectively output to the logs (you can use the dmesg command to view). Messages can be displayed in various types:
#define KERN_EMERG "<0>" /* system is unusable */ #define KERN_ALERT "<1>" /* action must be taken immediately */ #define KERN_CRIT "<2>" /* critical conditions */ #define KERN_ERR "<3>" /* error conditions */ #define KERN_WARNING "<4>" /* warning conditions */ #define KERN_NOTICE "<5>" /* normal but significant condition */ #define KERN_INFO "<6>" /* informational */ #define KERN_DEBUG "<7>" /* debug-level messages */ #define KERN_DEFAULT "<d>" /* Use the default kernel loglevel */ Now we have all the information to write the frame of our first module:
#include <linux/module.h> #include <linux/kernel.h> MODULE_AUTHOR("Denis Dolgikh <sindo@sibmail.com>"); MODULE_DESCRIPTION("Module for the demonstration"); MODULE_LICENSE("GPL"); int Init(void) { printk(KERN_INFO "Init my module\n"); printk("Hello, World!\n"); return 0; } void Exit(void) { printk(KERN_INFO "Exit my module\n"); } module_init(Init); module_exit(Exit); I'll tell you a little more about how to compile and run all this. I have to say that I have Ubuntu 11.10 (x86) Kernel 3.0 installed.
The system has a directory / lib / modules / [kernel version] / it contains modules for the corresponding kernel version. Also there is a build - this is a symbolic link to the headers of the kernel libraries (kernel-headers), which are located in the / usr / src / linux-headers- [kernel version] / directory. If you do not already have kernel headers, then you need to download them ( sudo apt-get install linux-headers- [kernel version] ). To find out the version of the current kernel you are working in, you can issue the uname –r command. If you use a library with a version different from the version of the current kernel, then such a compiled module may work fine, or it may not start at best. It all depends on what changes have occurred in the kernel, and what you use in the function module.
To compile the module, write the Makefile . Let's create two goals: all (build the module) and clean (clean the project), for writing we will use the goals already written for us: modules and clean in the Makefile from the kernel-headers .
# # module_test.o – , module_test. obj-m += module_test.o # Makefile kernel-headers -, # /lib/modules/[ ]/build # modules obj-m # M=$(PWD) , all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean Now we can easily compile the module using the make command and clean the make clean project. As a result, we get a ready-made module module_test.ko , which can be immediately loaded into the kernel using the insmod command ./module_test.ko . There is another option for loading a module into the kernel - with the modprobe module_test command . To do this, put the module module_test.ko in the directory / lib / modules / [current kernel version] / [any directory] / and do not forget to run depmod , since This command creates a list of module dependencies in / lib / modules / . Even if the module has no dependencies, modprobe will not see the added module without depmod . The main differences between insmod and modprobe are as follows: modprobe automatically loads all modules on which it depends upon loading a module, but insmod can load a module from any directory. Remove module from kernel: rmmod module_test . View information about the module: modinfo module_test or modinfo ./module_test.ko .
Netfilter library
And so back to the proxy for https. Our task is to make the module view the network packets before DNAT (iptables) processes them. The Netfilter library will help us for this . (For a more detailed understanding, I recommend further reading about Netfilter in other sources, at least on Wikipedia ) Consider what the path of a network package looks like in the kernel:
More details can be found here .
Netfilter <linux / netfilter.h> provides 5 hook functions that give access to a network package in 5 different places:
- NF_INET_PRE_ROUTING - the function catches absolutely all input packets, before the packets have already passed simple checks (packets are not lost, IP checksum is OK, etc.);
The packet then goes through routing, which decides whether the packet is for a different interface or local process. Routing may drop a packet if it is not routable. - NF_INET_LOCAL_IN - called if the package is intended for a local process, before sending the package to it;
- NF_INET_FORWARD - when a packet is routed from one interface to another;
- NF_INET_LOCAL_OUT - trap for packages that create local processes;
- NF_INET_POST_ROUTING is the final point before sending the packet to the network card driver.
The kernel module can register its function in any of these 5 places. When registering, the module must indicate the priority of its function in this place. In the library <linux / netfilter_ipv4.h> you can find priority for various standard tasks:
enum nf_ip_hook_priorities { NF_IP_PRI_FIRST = INT_MIN, NF_IP_PRI_CONNTRACK_DEFRAG = -400, NF_IP_PRI_RAW = -300, NF_IP_PRI_SELINUX_FIRST = -225, NF_IP_PRI_CONNTRACK = -200, NF_IP_PRI_MANGLE = -150, NF_IP_PRI_NAT_DST = -100, NF_IP_PRI_FILTER = 0, NF_IP_PRI_SECURITY = 50, NF_IP_PRI_NAT_SRC = 100, NF_IP_PRI_SELINUX_LAST = 225, NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX, NF_IP_PRI_LAST = INT_MAX, }; The list shows that DNAT has a priority of -100, so any priority <-100 is suitable for our purpose. If the priority of the function is> -100, then it will receive packets with the already changed IP address of the destination (recipient).
Each registered function in any of the 5 points must return one of the following values, which determines the further fate of the packet passed to it:
#define NF_DROP 0 /* discarded the packet */ #define NF_ACCEPT 1 /* the packet passes, continue iterations */ #define NF_STOLEN 2 /* gone away */ #define NF_QUEUE 3 /* inject the packet into a different queue (the target queue number is in the high 16 bits of the verdict) */ #define NF_REPEAT 4 /* iterate the same cycle once more */ #define NF_STOP 5 /* accept, but don't continue iterations */ In my free translation it will sound like this:
- NF_DROP - remove this package
- NF_ACCEPT - the packet goes on, the iterations continue
- NF_STOLEN - drop this package (the kernel will no longer process it, the module must free up the memory allocated for this package)
- NF_QUEUE - put a package in a queue (usually for processing a package in user space)
- NF_REPEAT - repeat iteration (repeated function call with the same package)
- NF_STOP - skip package further, but do not continue iterations
With the theory figured out, now we continue to write the module. When a module is loaded into the kernel, you need to register the function, call it Hook_Func , which will scan all incoming packets, and upon completion, you must unregister this function, otherwise the kernel will try to call a non-existent function.
#include <linux/module.h> #include <linux/kernel.h> #include <linux/netfilter.h> #include <linux/netfilter_ipv4.h> /* ip */ struct nf_hook_ops bundle; int Init(void) { printk(KERN_INFO "Start module Shifter\n"); /* hook */ /* , */ bundle.hook = Hook_Func; /* , hook */ bundle.owner = THIS_MODULE; /* */ bundle.pf = PF_INET; /* , */ bundle.hooknum = NF_INET_PRE_ROUTING; /* */ bundle.priority = NF_IP_PRI_FIRST; /* */ nf_register_hook(&bundle); return 0; } void Exit(void) { /* hook */ nf_unregister_hook(&bundle); printk(KERN_INFO "End module Shifter\n"); } module_init(Init); module_exit(Exit); Now all we have to do is write the function Hook_Func . It should have the following prototype:
unsigned int Hook_Func(uint hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *) ) { /* firewall */ /* () :) */ return NF_DROP; } Consider its parameters:
- uint hooknum contains one of the following values: {NF_INET_PRE_ROUTING = 0, NF_INET_LOCAL_IN = 1, NF_INET_FORWARD = 2, NF_INET_LOCAL_OUT = 3, NF_INET_POST_ROUTING = 4} . This parameter is needed to find out from which place the function was called, since You can register the same function in several places.
- struct sk_buff * skb pointer to package structure.
- const struct net_device * in input interface information. If this is an outgoing packet, then the parameter is NULL.
- const struct net_device * out information about the output interface. If it is an incoming packet, then the parameter is NULL.
- int (* okfn) (struct sk_buff *) is a callback function that is called with the package when all iterations return a positive response.
Now more about the pointer to the packet struct sk_buff * skb .
sk_buff is a buffer for working with packages. As soon as a package arrives or it becomes necessary to send it, sk_buff is created, where the package is placed, as well as related information, where, where, for what ... Throughout the entire journey of the package, sk_buff is used in the network stack. As soon as the packet is sent, or the data is transmitted to the user, the structure is destroyed, thereby freeing memory.The sk_buff structure is described in <linux / skbuff.h> , and various functions are described there for pleasant work with it.
When working with tcp, you can use two more structures - this is a struct iphdr and a struct tcphdr .
As the name implies, these structures are designed to work with the IP header and, accordingly, with the TCP header . To get pointers to these structures from skb_buff, you can use two functions:
static inline unsigned char *skb_network_header(const struct sk_buff *skb); static inline unsigned char *skb_transport_header(const struct sk_buff *skb); In this place I would like to appeal to the reader. It remains unclear to me exactly who should set the transport_header pointer in the sk_buff structure, since at the NF_INET_PRE_ROUTING and NF_INET_LOCAL_IN points (with any priorities) I could not get a structure on the tcp header using skb_transport_header , although it worked perfectly at the other points. I had to manually specify the offset for transport_header from the pointer sk_buff-> data , using the void skb_set_transport_header (skb, offset) .
The sk_buff-> data pointer is a pointer to the package contents, i.e. points to the memory area after the Ethernet protocol, for example, immediately to the IP header structure, and then it can be followed by the TCP header structure or your own protocol.
Since pointers to data in the package itself are used everywhere, it is possible not only to read various fields, but also to change them. However, it must be remembered that when changing, for example, the IP address of the sender or recipient, it is necessary to recalculate the checksum in the IP packet header.
And so, our function will save the destination IP address only when it sees the IP-TCP packet going to port 443 (HTTPS) and containing the SYN flag, which says that the client wants to establish a TCP connection for the HTTPS protocol. And delete when packets containing FIN or RST flags appear that say that the tcp connection is broken and we do not need this IP address anymore.
#include <linux/skbuff.h> #include <linux/ip.h> #include <linux/tcp.h> #define uchar unsigned char #define ushort unsigned short #define uint unsigned int /* Hook_Func - , */ /* IP , : */ /* - tcp */ /* - 443 (HTTPS) */ /* - SYN ( tcp ) */ uint Hook_Func(uint hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *) ) { /* ip */ struct iphdr *ip; /* tcp */ struct tcphdr *tcp; /* IP */ if (skb->protocol == htons(ETH_P_IP)) { /* IP */ ip = (struct iphdr *)skb_network_header(skb); /* IP 4 TCP */ if (ip->version == 4 && ip->protocol == IPPROTO_TCP) { /* TCP */ /* ip->ihl - IP 32- */ skb_set_transport_header(skb, ip->ihl * 4); /* TCP */ tcp = (struct tcphdr *)skb_transport_header(skb); /* 443 (HTTPS) */ if (tcp->dest == htons(443)) { /* SYN, IP */ if (tcp->syn) AddTable((uint)ip->saddr, (ushort)tcp->source, (uint)ip->daddr); /* FIN RST, IP */ if (tcp->fin || tcp->rst) DelTable((uint)ip->saddr, (ushort)tcp->source, (uint)ip->daddr); } } } /* */ return NF_ACCEPT; } There are two functions AddTable and DelTable , which should save and delete the recipient's IP address from memory, for each IP and port of the sender. This is necessary so that the client-server Shifter can communicate with the Shifter module and use the ReadTable function to find out by the client's IP and port what IP address he really wanted to contact. I didn’t think much about the data type to save the IP and used the usual static array using the elementary hash function. The hash function ( KeyHash ) receives at the input ip and the port of the sender and returns the index of the array where the ip destination address is stored. It is written taking into account the fact that the client is behind the nat and has a subnet with a mask of 255.255.255.0, so I use only the last byte of the sender's ip, and this byte is also superimposed by 3 bits on two bytes of the port. As a result, I managed to compress the array to a size of 0x1FFFFF (~ 8 MB). Of course, you need to take into account that now, after loading into the kernel, this module will take at least 8 MB of memory, and this may be too much for some embedded systems. And we don’t forget about the collision :) But for my demo, it all pays off with simplicity and, in addition, DelTable is completely empty.
/* IP */ #define MaxTable 0x1FFFFF uint Table[MaxTable]; /* KeyHash - */ /* IP */ uint KeyHash(uint src_IP, ushort src_Port) { return (uint)(((src_IP & 0xFF000000) >> 11) ^ (uint)src_Port) % MaxTable; } /* AddTable - IP */ /* IP */ void AddTable(uint src_IP, ushort src_Port, uint dst_IP) { Table[KeyHash(src_IP, src_Port)] = dst_IP; } void DelTable(uint src_IP, ushort src_Port, uint dst_IP) { /* IP */ /* */ } /* ReadTable - IP */ /* IP */ uint ReadTable(uint src_IP, ushort src_Port) { return Table[KeyHash(src_IP, src_Port)]; } That’s the end of the article, and the only thing left is to connect the client-server Shifter with the core module Shifter.
Interaction with kernel module from user space (Netlink)
Now our goal is to create one socket in the Shifter and in the Shifter module and connect them together. The exchange protocol between the module and the Shifter server will be simple. Shifter will send 4 bytes of client IP and 2 bytes of client port, and the module will respond with 4 bytes of IP destination, taken from its table. To do this, use the library Netlink.
I want to note that the header <linux / netlink.h> for user applications is /usr/include/linux/netlink.h and for kernel modules is / usr / src / linux-headers- [kernel version] / include / linux / netlink. h has many differences .
Netlink in user space
With regard to netlink from the user space in the network a lot of information, for example, here:
RFC 3549 - Linux Netlink as a protocol for IP services
Working with NetLink on Linux. Part 1
A simple monitor of Linux network interfaces, using netlink.
Therefore, here I will tell only what we need to ensure the exchange of information between the kernel module and user-space programs.
Netlink socket is created by the usual function: int socket (PF_NETLINK, socket_type, netlink_family);
Where as socket_type can be used as SOCK_RAW , and SOCK_DGRAM ; nevertheless, the netlink protocol does not draw the line between datagram and raw sockets. And netlink_family selects a kernel module or netlink group for communication. The <linux / netlink.h> , you can view the complete list of families .
Netlink messages are a stream of bytes with one or more nlmsghdr headers (netlink message header). To access byte streams, only NLMSG_ * macros should be used . I also want to note that the netlink protocol does not provide guaranteed message delivery. If there is a shortage of memory or other errors, the protocol may drop packets.
Consider the sockaddr_nl, nlmsghdr (<linux / netlink.h>), iovec and msghdr (<sys / socket.h>) structures that we will work with:
struct sockaddr_nl - describes the netlink addresses for user programs and kernel modules. The structure is used to describe the sender or recipient of the data.
struct sockaddr_nl { sa_family_t nl_family; /* AF_NETLINK */ unsigned short nl_pad; /* */ __u32 nl_pid; /* 0, , */ __u32 nl_groups; /* netlink 32 multicast-. nl_groups , , */ }; struct nlmsghdr is the netlink message header and immediately after the structure the sent / received data is located in the memory, to access it, use the NLMSG_DATA (struct nlmsghdr *) macro.
struct nlmsghdr { __u32 nlmsg_len; /* */ __u16 nlmsg_type; /* () */ __u16 nlmsg_flags; /* */ __u32 nlmsg_seq; /* ( ) */ __u32 nlmsg_pid; /* (PID), */ }; struct iovec - located in msghdr , it will contain a pointer to the nlmsghdr structure .
struct iovec { void * iov_base; /* ( nlmsghdr) */ size_t iov_len; /* () */ }; struct msghdr - contains a pointer to the address ( sockaddr_nl ) and data ( iovec )
struct msghdr { void * msg_name; /* */ socklen_t msg_namelen; /* */ struct iovec * msg_iov; /* */ size_t msg_iovlen; /* */ void * msg_control; /* */ size_t msg_controllen; /* */ int msg_flags; /* */ }; Consider some Netlink macros:
int NLMSG_ALIGN(size_t len); Rounds the size of the netlink message to the nearest larger value aligned along the boundary. int NLMSG_LENGTH(size_t len); Accepts the size of the data field as a parameter and returns the size-aligned value for writing the nlmsghdr header to the nlmsg_len field. int NLMSG_SPACE(size_t len); Returns the size of the memory (in bytes) that the nlmsghdr structure will take plus the data of the specified length len (in bytes) in the netlink packet. void *NLMSG_DATA(struct nlmsghdr *nlh); Returns a pointer to the data associated with the nlmsghdr header passed. struct nlmsghdr *NLMSG_NEXT(struct nlmsghdr *nlh, int len); Returns the next part of a multi-part message. The macro accepts the following nlmsghdr header in a message consisting of many parts. The calling application should check for the NLMSG_DONE flag in the current nlmsghdr header — the function does not return NULL when the message processing is completed. The second parameter sets the size of the rest of the message buffer. The macro reduces this value by the size of the message header. int NLMSG_OK(struct nlmsghdr *nlh, int len); Returns the value TRUE (1) if the message was not truncated and it was successfully disassembled. int NLMSG_PAYLOAD(struct nlmsghdr *nlh, int len); Returns the size of the data associated with the nlmsghdr header.Part of the source code of the server Shifter with Netlink.
Netlink Kernel Space
When using the netlink library in kernel modules, there are some differences, for example, the nlmsghdr structure from <linux / netlink.h> remains the same, but is already wrapped in the well-known sk_buff structure . And instead of the usual functions for working with sockets, we will use a new set of functions. Consider some of them.
In a module, a socket is not represented as an int type , but as a sock structure from <net / sock.h> . struct sock is a very big one I will not describe it, besides its description is not needed.
To create a netlink socket, <linux / netlink.h> has the function netlink_kernel_create . It not only creates a netlink socket, but also registers a function that will be called whenever data arrives.
struct sock *netlink_kernel_create( struct net *net, int unit, unsigned int groups, void (*input)(struct sk_buff *skb), struct mutex *cb_mutex, struct module *module); To close the netlink socket and remove the "registration function" use:
void netlink_kernel_release(struct sock *sk); We also need functions from <net / netlink.h> , there you can find functions with an amazing description.
I will simply translate some of the necessary functions:
/** * nlmsg_new – netlink * @payload: * @flags: * * NLMSG_DEFAULT_SIZE, */ static inline struct sk_buff *nlmsg_new(size_t payload, gfp_t flags) { return alloc_skb(nlmsg_total_size(payload), flags); } /** * nlmsg_put - NetLink skb * @skb: netlink * @pid: * @seq: * @type: * @payload: ( ) * @flags: * * NULL, skb , * netlink , * netlink */ static inline struct nlmsghdr *nlmsg_put(struct sk_buff *skb, u32 pid, u32 seq, int type, int payload, int flags) /** * nlmsg_unicast – netlink * @sk: netlink * @skb: netlink * @pid: netlink */ static inline int nlmsg_unicast(struct sock *sk, struct sk_buff *skb, u32 pid) /** * nlmsg_data – * @nlh: netlink */ static inline void *nlmsg_data(const struct nlmsghdr *nlh) { return (unsigned char *) nlh + NLMSG_HDRLEN; } It remains to add Module Shifter.
Conclusion
In conclusion, in order to redirect packets to the proxy server, it is enough to add a rule to iptables on the gateway:
# nat (-A) PREROUTING # tcp 443 443 iptables -t nat -A PREROUTING -p tcp --dport 443 -j REDIRECT --to-port 443 Download Shifter source archive
The end.
Used and useful literature
NetFilter.org
Linux, Kernel, Firewall
Kernel Korner -
Linking Netlink as a protocol for IP services
Working with NetLink on Linux. Part 1
Linux netlink protocol
Source: https://habr.com/ru/post/138328/
All Articles