Multithreading in practice
Found somehow on stack overflow the question ( link ).
Transfer
In general, the idea was not difficult in principle. Because By the condition, you cannot use util.concurrent, then you need to implement your thread pool, plus write some tasks that will spin in this thread pool.
Also, I was not sure that with multi-threaded IO usage there will be an increase in performance.
At once I will say that the goal was not the fulfillment of the task, but the investigation of the problem, therefore not all the code will be beautiful.
In principle, the algorithm is similar to a recursive tree traversal, for example, its simple implementation link
')
For a start, let's check how fast a single-threaded implementation works, I’ll not give a single-threaded implementation code, it is in the archive.
The results are as follows:
154531 ms
Now we will try to do the same, but we will use a multi-threaded implementation of the algorithm.
To do this, instead of a recursive call, we will create some Task, which we will give to the execution of a thread pool. It is also necessary, so that by the result of the task, there was an opportunity to somehow report the results. Plus, you need to add a new task to the thread pool (instead of recursion).
Here we must immediately stop, why I chose precisely small tasks and a pool of threads, instead of creating new threads. Imagine that we have a lot of directories, and for each directory we will create a new thread? we can just fall by OOM (OutOfMemory) or just everything will start to slow down a lot because of switching between OS threads (especially if a single-core system). We will also spend time starting a new thread each time it is created.
First you need to create a class that will perform some action in the future thread pool.
Basic requirements for the class:
- the class should be inherited from Thread (in principle, you can only runnable interface, but it's easier)
- class must accept runnable objects for execution
- the class should not fall when any exceptions occur as a result of the task execution.
- if there are no tasks, Thread should not work in empty, but should go on waiting
- the procedure for adding new Runnable objects must be very fast, otherwise with a large number of small tasks, someone will either block the work of the thread, or wait for the opportunity to add a new task to the thread
- well, it should be ThreadSafe
Here is the code:
Now you need to create a ThreadPool that will distribute the work between its threads.
The requirements for the class are:
- ThreadSafe
- scalable
- uniform distribution between worker threads
- not blockable
The code is:
In principle, everything is clear, and probably nothing to comment on.
Now we need to write a task that will be executed in ThreadPool.
Unfortunately, the first version was lost for me, so I bring a quickly re-written version.
Now let's talk a little about profiler. What it is for, I will not describe, you can search yourself if you have not heard anything about such a little animal yet. When profiling multithreaded applications, the most attention should be paid to Monitor Usage (each profiler has such an opportunity). Usually this type of profiling should be started manually. It is of interest how much time certain threads hang in anticipation of locks. For example, you can create a bunch of threads, but they will all rest on some kind of lock, and the system performance will drop dramatically. It is also worth paying attention to using the CPU, for example, if the CPU uses 10-20%, this can also mean that threads expect more locks than perform any calculations (although this is not always the case).
Now let's see the result in the profiler:
program execution time:
total task: 78687
55188ms
As a result, the speed of work increased by about 3 times.
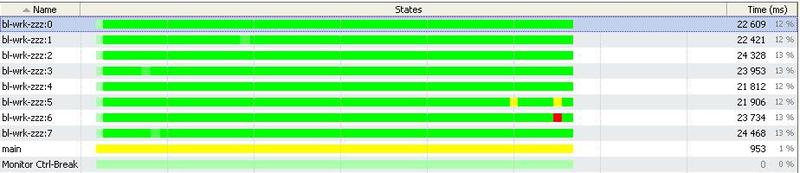
Here we see that all the threads in the trappool were busy working almost the entire time. Locking threads is almost not observed.

In the second picture, we see that the main CPU time is spent on IO.

Here we see that CPU usage is> 80%.
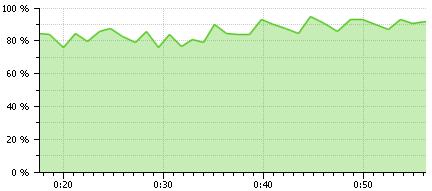
Here we see only one thread lock, which took less than 1 ms, with 78 thousand tasks a very good result.
As we see, in principle, we load the CPU, and we have no idle time, since all threads are almost fully loaded with work. There are no locks on the locks.
It will be interesting to look at the picture number 2. As we can see, the most “expensive” operation is java.io.File.isDirectory (), it takes about 46% of the total time. Googling about this problem, I did not find anything except the ability to use Java7, well, or dependency OS features. Therefore, the possibility of optimizing this part as I see no more. Next comes the parser - java.util.regex.Matcher.find (), but here you can speed it up. You can create another task, which will only deal with parsing. Those. we will separate the two most difficult operations:
1) work with the file system
2) name parsing
The third operation is again IO, and this is also difficult to speed up.
So we modify the first task a bit, and add a new one:
And run again:
total task: 221560
52328

As we can see, the result is not very different from the first run, but still a little faster, especially the gain will increase if there are directories with a large number of files. But with this approach, we have increased the number of tasks almost 3 times, which, for example, may affect the Garbage Collector. So here we must already choose what we want - maximum performance or savings in memory and resources.
Now we need to think about how to exit the program, and how to return the result. We have produced a bunch of tasks, and we do not know when they will all be fulfilled. I did not think of anything better, how easy it would be to count the total number of tasks, and wait until the counter reaches zero. To do this, we need a variable in which we will accumulate values. But here, too, things are not so simple. For example, if we take an ordinary variable, and we increment it when the task has been created, and decrement it when the task has ended. But with this approach, the result will be deplorable, because in java, the i ++ operation is not atomic, even if we deliver the coveted volatile modifier. It would be ideal to take AtomicIteger, but we cannot use the util.concurrent package by condition. Therefore, we will have to make our Atomic. If you delve into how Atomic works in java, then we stumble upon a native method. The atomic nature of a variable change itself is implemented as a processor command, so java invokes the native OS command, which already calls the processor command.
In principle, we can use normal synchronized. But with a large number of tasks, the Lock race will begin, and the performance will decrease (although of course it is not critical). Here is an example of code implementing the CAS algorithm (the code was found on the ibm website):
Here in the evening, that's all.
Source archive: link
PS I tested it on Linux, and on Windows on a 4-core processor. The optimal number of threads in the pool was calculated experimentally - 16, i.e. the number of cores * 4, once found on the Internet already such a formula, but I do not remember where. In Windows, there is a feature when you start it for the first time, it works for a very long time, and often everything hangs on IO, but already at the second start, everything works much faster, I think this is a feature of the OS to cache the file system. I tested everything with the second launch and further, then I looked at the CPU utilization in the profiler, if there was a failure in using the CPU somewhere, I considered this test to be inaccurate and did not use this test in statistics. I tested everything on the project folder (many large projects with CVS files).
PSS This is my first big topic on Habré, so please do not criticize too much in terms of design, I will fix it if possible.
Need to create java CLI programm that searchs for specific files matched some pattern. Need to use multi-threading approach without using util.concurrent package and to provide good performance on parallel controllers.Transfer
, - . , util.concurrent. .
In general, the idea was not difficult in principle. Because By the condition, you cannot use util.concurrent, then you need to implement your thread pool, plus write some tasks that will spin in this thread pool.
Also, I was not sure that with multi-threaded IO usage there will be an increase in performance.
At once I will say that the goal was not the fulfillment of the task, but the investigation of the problem, therefore not all the code will be beautiful.
In principle, the algorithm is similar to a recursive tree traversal, for example, its simple implementation link
import java.io.File; public class MainEntry { public static void main(String[] args) { walkin(new File("/home/user")); //Replace this with a suitable directory } /** * Recursive function to descend into the directory tree and find all the files * that end with ".mp3" * @param dir A file object defining the top directory **/ public static void walkin(File dir) { String pattern = ".mp3"; File listFile[] = dir.listFiles(); if(listFile != null) { for(int i=0; i<listFile.length; i++) { if(listFile[i].isDirectory()) { walkin(listFile[i]); } else { if(listFile[i].getName().endsWith(pattern)) { System.out.println(listFile[i].getPath()); } } } } } } ')
For a start, let's check how fast a single-threaded implementation works, I’ll not give a single-threaded implementation code, it is in the archive.
The results are as follows:
154531 ms
Now we will try to do the same, but we will use a multi-threaded implementation of the algorithm.
To do this, instead of a recursive call, we will create some Task, which we will give to the execution of a thread pool. It is also necessary, so that by the result of the task, there was an opportunity to somehow report the results. Plus, you need to add a new task to the thread pool (instead of recursion).
Here we must immediately stop, why I chose precisely small tasks and a pool of threads, instead of creating new threads. Imagine that we have a lot of directories, and for each directory we will create a new thread? we can just fall by OOM (OutOfMemory) or just everything will start to slow down a lot because of switching between OS threads (especially if a single-core system). We will also spend time starting a new thread each time it is created.
First you need to create a class that will perform some action in the future thread pool.
Basic requirements for the class:
- the class should be inherited from Thread (in principle, you can only runnable interface, but it's easier)
- class must accept runnable objects for execution
- the class should not fall when any exceptions occur as a result of the task execution.
- if there are no tasks, Thread should not work in empty, but should go on waiting
- the procedure for adding new Runnable objects must be very fast, otherwise with a large number of small tasks, someone will either block the work of the thread, or wait for the opportunity to add a new task to the thread
- well, it should be ThreadSafe
Here is the code:
import java.util.ArrayList; import java.util.List; class BacklogWorker extends Thread { /* */ private final LinkedList<Runnable> backlog = new LinkedList<Runnable>(); private static final int INITIAL_CAPACITY = 100; /* , */ private final List<Runnable> workQueue = new ArrayList<Runnable>(INITIAL_CAPACITY); BacklogWorker(String name) { super(name); } /* */ synchronized void enque(Runnable work) { if (work != null) { backlog.add(work); } notify(); } public void run() { while (!isInterrupted()) { /* , */ synchronized (this) { if (backlog.isEmpty()) { try { wait(); } catch (InterruptedException e) { interrupt(); } } int size = backlog.size(); for (int i = 0; i < INITIAL_CAPACITY && i < size; i++) { workQueue.add(backlog.poll()); } backlog.clear(); } for (Runnable task : workQueue) { try { task.run(); } catch (RuntimeException e) { e.printStackTrace(); } } workQueue.clear(); } } } Now you need to create a ThreadPool that will distribute the work between its threads.
The requirements for the class are:
- ThreadSafe
- scalable
- uniform distribution between worker threads
- not blockable
The code is:
import java.util.concurrent.Executor; public class BacklogThreadPool implements Executor/*i don't use anything from concurrent, just only one interface*/ { private final BacklogWorker workers[]; private final int mask; private static volatile int sequence; public BacklogThreadPool(int threadCount, String id) { int tc; for (tc = 1; tc < threadCount; tc <<= 1) ; mask = tc - 1; if (id == null) { id = Integer.toString(getSequence()); } workers = new BacklogWorker[tc]; for (int i = 0; i < tc; i++) { workers[i] = new BacklogWorker((new StringBuilder()).append("thead-pool-worker-").append(id).append(":").append(i).toString()); workers[i].start(); } } private synchronized int getSequence() { return sequence++; } public void shutdown() { for (int i = 0; i < workers.length; i++) workers[i].interrupt(); } @Override public void execute(Runnable command) { workers[command.hashCode() & mask].enque(command); } } In principle, everything is clear, and probably nothing to comment on.
Now we need to write a task that will be executed in ThreadPool.
Unfortunately, the first version was lost for me, so I bring a quickly re-written version.
import java.io.File; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WalkinTask1 implements BacklogTask { private List<File> dirs; private ParseHandler parseHandler; public WalkinTask1(List<File> dirs, ParseHandler parseHandler) { this.parseHandler = parseHandler; //this.parseHandler.taskStart(); this.parseHandler.taskStartUnblock(); this.dirs = dirs; } @Override public void run() { try { List<String> filePaths = new ArrayList<String>(); List<File> dirPaths = new ArrayList<File>(); for (File dir : dirs) { if (!dirPaths.isEmpty()) { dirPaths = new ArrayList<File>(); } if (!filePaths.isEmpty()) { filePaths = new ArrayList<String>(); } File listFile[] = dir.listFiles(); if (listFile != null) { for (File file : listFile) { if (file.isDirectory()) { dirPaths.add(file); } else { filePaths.add(file.getPath()); } } } if (!dirPaths.isEmpty()) { parseHandler.schedule(TaskFactory.createWalking1Task(parseHandler, dirPaths)); } if (!filePaths.isEmpty()) { Pattern pattern = parseHandler.getPattern(); List<String> result = new ArrayList<String>(); for (String path : filePaths) { Matcher matcher = pattern.matcher(path); while (matcher.find()) { String str = matcher.group(); if (!"".equals(str)) { result.add(str); } } } parseHandler.taskComplete(result); } } } finally { //parseHandler.taskFinish(); parseHandler.taskFinishUnblock(); } } @Override public int getTaskType() { return 1; //TODO } } Now let's talk a little about profiler. What it is for, I will not describe, you can search yourself if you have not heard anything about such a little animal yet. When profiling multithreaded applications, the most attention should be paid to Monitor Usage (each profiler has such an opportunity). Usually this type of profiling should be started manually. It is of interest how much time certain threads hang in anticipation of locks. For example, you can create a bunch of threads, but they will all rest on some kind of lock, and the system performance will drop dramatically. It is also worth paying attention to using the CPU, for example, if the CPU uses 10-20%, this can also mean that threads expect more locks than perform any calculations (although this is not always the case).
Now let's see the result in the profiler:
program execution time:
total task: 78687
55188ms
As a result, the speed of work increased by about 3 times.
Here we see that all the threads in the trappool were busy working almost the entire time. Locking threads is almost not observed.
In the second picture, we see that the main CPU time is spent on IO.
Here we see that CPU usage is> 80%.
Here we see only one thread lock, which took less than 1 ms, with 78 thousand tasks a very good result.
As we see, in principle, we load the CPU, and we have no idle time, since all threads are almost fully loaded with work. There are no locks on the locks.
It will be interesting to look at the picture number 2. As we can see, the most “expensive” operation is java.io.File.isDirectory (), it takes about 46% of the total time. Googling about this problem, I did not find anything except the ability to use Java7, well, or dependency OS features. Therefore, the possibility of optimizing this part as I see no more. Next comes the parser - java.util.regex.Matcher.find (), but here you can speed it up. You can create another task, which will only deal with parsing. Those. we will separate the two most difficult operations:
1) work with the file system
2) name parsing
The third operation is again IO, and this is also difficult to speed up.
So we modify the first task a bit, and add a new one:
import java.io.File; import java.util.ArrayList; import java.util.List; public class WalkinTask implements BacklogTask { private List<File> dirs; private ParseHandler parseHandler; public WalkinTask(List<File> dirs, ParseHandler parseHandler) { this.parseHandler = parseHandler; //this.parseHandler.taskStart(); this.parseHandler.taskStartUnblock(); this.dirs = dirs; } @Override public void run() { try { List<String> filePaths = new ArrayList<String>(); List<File> dirPaths = new ArrayList<File>(); for (File dir : dirs) { if (!dirPaths.isEmpty()) { dirPaths = new ArrayList<File>(); } if (!filePaths.isEmpty()) { filePaths = new ArrayList<String>(); } File listFile[] = dir.listFiles(); if (listFile != null) { for (File file : listFile) { if (file.isDirectory()) { dirPaths.add(file); } else { filePaths.add(file.getPath()); } } } if (!dirPaths.isEmpty()) { parseHandler.schedule(TaskFactory.createWalkingTask(parseHandler, dirPaths)); } if (!filePaths.isEmpty()) { parseHandler.schedule(TaskFactory.createParseTask(parseHandler, filePaths)); } } } finally { //parseHandler.taskFinish(); parseHandler.taskFinishUnblock(); } } @Override public int getTaskType() { return 1; //TODO } } import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; public class ParseTask implements BacklogTask { private ParseHandler handler; private List<String> paths; public ParseTask(ParseHandler hander, List<String> paths) { this.handler = hander; this.paths = paths; handler.taskStartUnblock(); } @Override public void run() { try { Pattern pattern = handler.getPattern(); List<String> result = new ArrayList<String>(); for (String path : paths) { Matcher matcher = pattern.matcher(path); while (matcher.find()) { String str = matcher.group(); if (!"".equals(str)) { result.add(str); } } } handler.taskComplete(result); } finally { handler.taskFinishUnblock(); } } @Override public int getTaskType() { return 0; } } And run again:
total task: 221560
52328
As we can see, the result is not very different from the first run, but still a little faster, especially the gain will increase if there are directories with a large number of files. But with this approach, we have increased the number of tasks almost 3 times, which, for example, may affect the Garbage Collector. So here we must already choose what we want - maximum performance or savings in memory and resources.
Now we need to think about how to exit the program, and how to return the result. We have produced a bunch of tasks, and we do not know when they will all be fulfilled. I did not think of anything better, how easy it would be to count the total number of tasks, and wait until the counter reaches zero. To do this, we need a variable in which we will accumulate values. But here, too, things are not so simple. For example, if we take an ordinary variable, and we increment it when the task has been created, and decrement it when the task has ended. But with this approach, the result will be deplorable, because in java, the i ++ operation is not atomic, even if we deliver the coveted volatile modifier. It would be ideal to take AtomicIteger, but we cannot use the util.concurrent package by condition. Therefore, we will have to make our Atomic. If you delve into how Atomic works in java, then we stumble upon a native method. The atomic nature of a variable change itself is implemented as a processor command, so java invokes the native OS command, which already calls the processor command.
In principle, we can use normal synchronized. But with a large number of tasks, the Lock race will begin, and the performance will decrease (although of course it is not critical). Here is an example of code implementing the CAS algorithm (the code was found on the ibm website):
public class SimulatedCAS { private volatile int value; public synchronized int getValue() { return value; } public synchronized int compareAndSwap(int expectedValue, int newValue) { int oldValue = value; if (value == expectedValue) value = newValue; return oldValue; } } public class CasCounter { private SimulatedCAS value = new SimulatedCAS(); public int getValue() { return value.getValue(); } public int increment() { int oldValue = value.getValue(); while (value.compareAndSwap(oldValue, oldValue + 1) != oldValue) oldValue = value.getValue(); return oldValue + 1; } public int decrement() { int oldValue = value.getValue(); while (value.compareAndSwap(oldValue, oldValue - 1) != oldValue) oldValue = value.getValue(); return oldValue - 1; } } Here in the evening, that's all.
Source archive: link
PS I tested it on Linux, and on Windows on a 4-core processor. The optimal number of threads in the pool was calculated experimentally - 16, i.e. the number of cores * 4, once found on the Internet already such a formula, but I do not remember where. In Windows, there is a feature when you start it for the first time, it works for a very long time, and often everything hangs on IO, but already at the second start, everything works much faster, I think this is a feature of the OS to cache the file system. I tested everything with the second launch and further, then I looked at the CPU utilization in the profiler, if there was a failure in using the CPU somewhere, I considered this test to be inaccurate and did not use this test in statistics. I tested everything on the project folder (many large projects with CVS files).
PSS This is my first big topic on Habré, so please do not criticize too much in terms of design, I will fix it if possible.
Source: https://habr.com/ru/post/137065/
All Articles