SqlBulkCopy - reloading big data without a crash or how to ride a wild horse (C #)

SqlBulkCopy is an effective solution for mass data loading into Microsoft SQL Server tables. The data source can be any, be it an xml-file, csv-file or another DBMS, for example, MySQL. It is enough to get data from the source as a DataTable object or implement the IDataReader interface over data access methods.
You do not have to create files on disk for further loading them using the BCP utility, you do not have to write code to generate multiple INSERT requests. When loading data, SqlBulkCopy works at a lower level, allowing you to insert millions of records in the shortest possible time.
Problem
Everything is good, SqlBulkCopy is so fast and crazy that it ignores any triggers, foreign keys and other restrictions and events when inserting data (you can turn it on if you like). He is also able to insert data in transactions for several blocks.
But SqlBulkCopy cannot handle exceptions that occur during data import. If at least one error occurs (duplication of keys, the inadmissibility of NULL values, the impossibility of type casting), then it will quickly finish its work without adding anything.
')
We will consider two tasks and their solutions:
1) How to use SqlBulkCopy with an arbitrary data source.
2) How to avoid exceptions when working with SqlBulkCopy.
Where to begin?
// IDateReader , . . var reader = GetReader(); var connectionString = @"Server={};initial catalog={ };Integrated Security=true"; // SqlBulkCopy, . using (var loader = new System.Data.SqlClient.SqlBulkCopy(connectionString)) { loader.DestinationTableName = "Persons"; loader.WriteToServer(reader); } In addition to the DestinationTableName property, an object of the SqlBulkCopy class also has the important BatchSize property (the number of rows uploaded to the server at a time is 0 by default and all data is loaded in one package), read more about it here .
Also, the second parameter of the SqlBulkCopy constructor can accept a variable of the SqlBulkCopyOptions type, pay attention to this if you need to enable triggers, constraints, or force NULL values when inserting. By default, this is nothing. Read more about the possible values of this parameter here .
Implementing the IDataReader Interface
Now let's look at a more practical example of how to implement the IDataReader interface for an arbitrary data source. In our example, the csv file will be the data source. Our task is to copy data from it into a SQL Server table.
We will import customers from a csv file, so our table in SQL Server looks like this:
The structure of the Customers table in T-SQL.
CREATE TABLE [Customers]( [ID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [SecondName] [nvarchar](50) NOT NULL, [Birthday] [smalldatetime] NULL, [PromoCode] [int] NULL ) ON [PRIMARY] Our csv file looks like this:
;;04.10.1974;65125 ;;12.12.1962;54671 ;; ; ;;10.12.1981;4FS2FGA Now it’s finally clear that when importing data we will have to solve the following problems:
- Provide correct data mapping. For example, the surname in the CSV document is listed first, unlike the SQL Server table. Also in the csv data there is no value for the ID, which is the primary automatically updated key.
- Bring data to SQL Server format and process invalid records. Look at the last line of the csv document, it does not contain a name, while in the SQL table this field is mandatory, or the value “not specified” in the third line, which does not lead to the type smalldatetime.
How SqlBulkCopy Works
- Connects to a SQL Server database and requests metadata for the specified table.
- Gets the number of columns using the IDadaReader interface's FieldCount property .
- Calculates where it will load it from (from which column of the data source to which column of the SQL Server table).
- Calls the Read () method and sequentially retrieves the values in the form object using the GetValue (int i) method — again, the IDadaReader interface.
- Calls one of the conversion methods, for example, Convert.ToInt32 (object value) , Convert.ToDateTime (object), and so on. Which method to call - SqlBulkCopy will be determined by the table metadata. The data type of the source does not interest him at all; if the conversion method throws an exception, the download will be interrupted.
Thus, if the data you want to import is far from ideal (as in our example), you have to do a little more work to load at least some of the data that is correct.
For the work!
It is quite simple to implement the IDataReader interface for SqlBulkCopy, you need to implement only 3 methods and one property, the rest are simply not needed, since they are not called by the SqlBulkCopy object. And so it is:
public int FieldCount
Returns the number of columns in the data source (csv file). Called first, before calling Read ().
public bool Read ()
Reads the next line. Returns true - if the end of the file / source is not reached, otherwise false.
public object GetValue (int i)
Returns the value with the specified index for the current row. It is always called after the Read () method.
public void Dispose ()
Freeing resources, SqlBulkCopy does not call this method, but it always comes in handy.
A simple implementation of the class for reading csv files that supports the IDataReader interface.
using System.Data; using System.IO; namespace SqlBulkCopyExample { public class CSVReader : IDataReader { readonly StreamReader _streamReader; readonly Func<string, object>[] _convertTable; readonly Func<string, bool>[] _constraintsTable; string[] _currentLineValues; string _currentLine; // CSV-. // , . // ( - , ). public CSVReader(string filepath, Func<string, bool>[] constraintsTable, Func<string, object>[] convertTable) { _constraintsTable = constraintsTable; _convertTable = convertTable; _streamReader = new StreamReader(filepath); _currentLine = null; _currentLineValues = null; } // , . // . public object GetValue(int i) { try { return _convertTable[i](_currentLineValues[i]); } catch (Exception) { return null; } } // . // , , // SqlBulkCopy, . public bool Read() { if (_streamReader.EndOfStream) return false; _currentLine = _streamReader.ReadLine(); // , ";" , // . _currentLineValues = _currentLine.Split(';'); var invalidRow = false; for (int i = 0; i < _currentLineValues.Length; i++) { if (!_constraintsTable[i](_currentLineValues[i])) { invalidRow = true; break; } } return !invalidRow || Read(); } // csv . // , 4, . public int FieldCount { get { return 4; } } // . . public void Dispose() { _streamReader.Close(); } // ... IDataReader, . } } Constraints table constraintsTable
The second parameter, constraintsTable, in the constructor, we passed an array of references to the methods that are used to quickly determine in advance whether SqlBulkCopy can correctly process the record or not. Each method takes the value of the corresponding column and returns the conclusion true or false. If at least one of the methods returns false, the string is skipped. Consider how to create an array of similar functions.
var constraintsTable = new Func<string, bool>[4]; constraintsTable[0] = x => !string.IsNullOrEmpty(x); constraintsTable[1] = constraintsTable[0]; constraintsTable[2] = x => true; constraintsTable[3] = x => true; We have four columns, so there are four methods. We set them through lambda expressions, so it is more convenient. The first method checks if the last name is valid (it should not be empty or be NULL), the second one does the same. Remember the schema of our table in SQl Server, the name and surname can not be NULL. The remaining methods always return true, since these are optional fields.
Note. You can avoid using constraint tables; instead, make all columns in a SQL Server table capable of storing null values. This will make inserting data faster.
ConvertTable conversion table
With the third parameter convertTable , we passed an array of references to the methods that are used to convert the values obtained from csv to those that SQL Server understands. In our case, SqlBulkCopy itself can do the same work, but it does not handle exceptions and cannot insert a NULL value if the conversion fails. We will facilitate his work.
var convertTable = new Func<object, object>[4]; // csv () convertTable[0] = x => x; // () convertTable[1] = x => x; // () // . convertTable[2] = x => { DateTime datetime; if (DateTime.TryParseExact(x.ToString(), "dd.MM.yyyy", CultureInfo.InvariantCulture, DateTimeStyles.None, out datetime)) { return datetime; } return null; }; // ( ) convertTable[3] = x => Convert.ToInt32(x); Name and first name do not need any conversion. They are already string values and their correctness is checked in the constraint tables. Date and number we are trying to convert. If an exception occurs, it will be caught in the GetValue () method.
Data mapping
Only one detail remained. By default, SqlBulkInsert will insert data as is, that is, from the first column of the source to the first column of the SQL Server table. We do not need this behavior, so we use the ColumnMappings property to set the insertion order.
// csv SQL Server . // . loader.ColumnMappings.Add(0, 2); loader.ColumnMappings.Add(1, 1); loader.ColumnMappings.Add(2, 3); loader.ColumnMappings.Add(3, 4); Now let's see how the call of our program will look like.
using System; using System.Data; using System.Data.SqlClient; using System.Globalization; namespace SqlBulkCopyExample { class Program { static void Main(string[] args) { // , . var reader = GetReader(); // . var connectionString = @"Server={};initial catalog={ };Integrated Security=true"; // SqlBulkCopy, . using (var loader = new SqlBulkCopy(connectionString, SqlBulkCopyOptions.Default)) { loader.ColumnMappings.Add(0, 2); loader.ColumnMappings.Add(1, 1); loader.ColumnMappings.Add(2, 3); loader.ColumnMappings.Add(3, 4); loader.DestinationTableName = "Customers"; loader.WriteToServer(reader); Console.WriteLine("!"); } Console.ReadLine(); } static IDataReader GetReader() { var sourceFilepath = AppDomain.CurrentDomain.BaseDirectory + "sqlbulktest.csv"; var convertTable = GetConvertTable(); var constraintsTable = GetConstraintsTable(); var reader = new CSVReader(sourceFilepath, constraintsTable, convertTable); return reader; } static Func<string, bool>[] GetConstraintsTable() { var constraintsTable = new Func<string, bool>[4]; constraintsTable[0] = x => !string.IsNullOrEmpty(x); constraintsTable[1] = constraintsTable[0]; constraintsTable[2] = x => true; constraintsTable[3] = x => true; return constraintsTable; } static Func<string, object>[] GetConvertTable() { var convertTable = new Func<object, object>[4]; // csv () convertTable[0] = x => x; // () convertTable[1] = x => x; // () // . convertTable[2] = x => { DateTime datetime; if (DateTime.TryParseExact(x.ToString(), "dd.MM.yyyy", CultureInfo.InvariantCulture, DateTimeStyles.None, out datetime)) { return datetime; } return null; }; // ( ) convertTable[3] = x => Convert.ToInt32(x); return convertTable; } } } As a result, in our Customers table we got the following result:
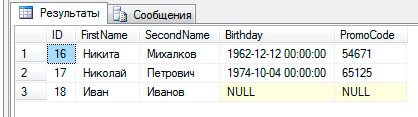
An invalid record was not added, and values that could not be cast to the required type were inserted as NULL.
Conclusion
We looked at how to programmatically using SqlBulkCopy to quickly insert data into a SQL Server table using a csv file as an example, implementing the decorator with the IDataReader interface, which handles problems encountered when inserting data. In real-world tasks, the amount of data is certainly more, but in these cases SqlBulkCopy will work just as well.
Additional materials
Learn about Microsoft 's recommendations for downloading large amounts of data from Microsoft.
You can see the full code in one list here .
Source: https://habr.com/ru/post/137038/
All Articles