Developing a compiler for the cool language in C # language under .NET (Part 2 + Bonuses)
Hi, Habrahabr!
In this article, I, as promised, will continue the description of the development of the compiler for the Cool language, begun in this article.
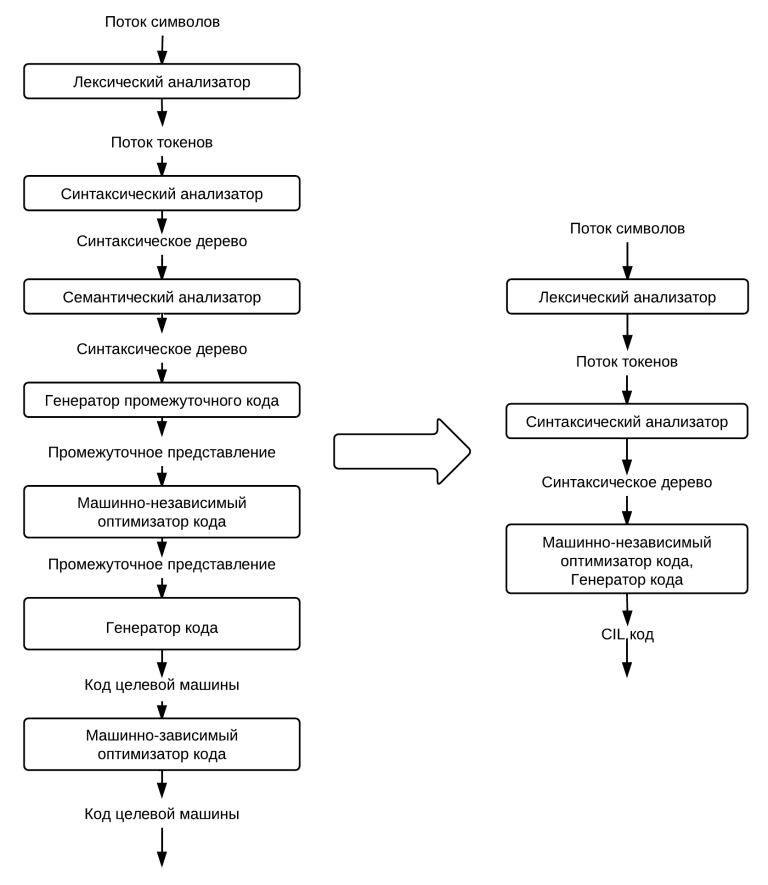
I recall that the compilation processfor Feng Shui includes several stages, which are depicted in the figure below to the left. My compiler contains only three stages, which are shown in the same figure to the right.
')
About lexical and parser it was told in the first article.
The main task of the semantic analyzer is to check the source program for semantic consistency with the definition of the language. This is mainly a type check , i.e. when the compiler checks if each operator has operands of the appropriate type.
The intermediate code generation is needed to generate an intermediate representation of the source code, which should be easily generated and easily translated into the target machine language. For example, a triaddress code is used as such a representation.
The machine-independent code optimization phase is used to make the intermediate code more qualitative (faster or, more rarely, short).
Code generation is a direct translation of the intermediate representation into a set of assembler or virtual machine commands.
The machine-dependent optimization phase is similar to machine-independent optimization, except that special instructions of the target machine (for example, SSE ) are used to optimize the code. It is clear that in our case the CLR takes on these responsibilities.
As can be seen from the diagram, in one stage I have combined three stages from the diagram on the left. This is explained both by the impossibility of generating an intermediate code using the System.Reflection.Emit tool (since a sequence of CIL instructions is generated that cannot be changed) and by the lack of attention to the architecture as a whole.
Wow, I don’t know where to start!
I will describe the stages of my code generator, which will be considered:
It is known that the source code in the Cool language is a set of classes. Naturally, there should be an entry point , and nothing will be done.
So, the entry point is the main function in the Main class. Both class and function need to be registered manually. But more on this later.
In System.Reflection.Emit there are special classes AssemblyBuilder and ModuleBuilder , which are used to build a dynamic assembly and generate CIL code.
To declare the description of any class method is used
In which className is the name of the class, attr is its attributes and parent is the parent (if any).
TypeBuilder is a dynamic type, which will then be used when generating code (for example, for the new operator).
So, at this stage, in the syntactic tree obtained from the parser, nodes with the type “class” are bypassed, as shown in the figure below, and all classes that are in the source code are determined using the method mentioned above.
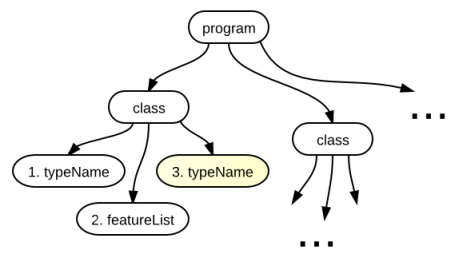
Optional symbols of the language are displayed in yellow (Here is the name of the parent class. If there is no parent, then the class is inherited from Object ).
I want to note that at this stage only class definitions are created, without their descriptions of the functions and fields within them. If, however, functions and fields are described immediately, then you may encounter an error that the class is not defined, although it is simply described later.
I also want to say that it would be more correct to sort the descriptions in the source code in the correct order before defining classes (for example, the description of class B, which is inherited from A, and then the description of class A). But this, unfortunately, is not implemented for me, therefore all classes should be described in the order in which they are used.
So, at this stage a dictionary has been received.
in which the key is the name of the class, and the value is its builder.
In conclusion, I want to say that after generating all the code, the dynamic types need to be finalized using the CreateType method (this is done in the FinalAllClasses function).
After determining the classes, in each class you need to define its functions and methods for further use. This is done using methods
and
respectively.
At the end of this stage, two-dimensional dictionaries are filled.
The key of the dictionary of the first dimension is the name of the class, the second is the name of the function or field. The values are the descriptors of a function or field, respectively (These classes will be discussed later).
The problem of sorting descriptions of functions and fields in the source code is not here, as it is when defining classes. Because at the stage of defining classes, information about other classes is used to determine inheritance, and it is used directly in the DefineType function. But, since information on other functions is not needed to define a function (code generation does not occur here), then references to other functions are not needed. So it is possible to generate definitions of functions and fields in any order.
And here we are at the most interesting. Here, a recursive traversal of the bodies of functions and constructors of all classes occurs directly.
So, from the previous step a dictionary of all method descriptors (MethodBuilder) for all classes was obtained.
To add a CIL instruction to a method, you must first obtain a special ILGenerator object using
There are many forms of the Emit method:
OpCode is a virtual .NET machine instruction. A good list of instructions with descriptions is listed here .
And the second argument (it is not always there) is the “builder” or the descriptor of the class or method that was obtained in the previous two stages.
The current function and the current class are the function and the class, respectively, in which the code is currently being generated (bypassing the syntax tree).
For a start, I will explain which classes in my code generator I entered to describe the arguments of functions, local variables, temporary local variables, and class fields. The base class is ObjectDef , which contains the abstract Load (), Remove () methods for loading, and freeing the corresponding object.
As you have already noticed, in Cool, every result is an expression. And inside each constructor and each function is also just one expr . This is the most important point of my code generator and for processing this design was introduced EmitExpression function (ITree expressionNode) . The code is shown below (I have shortened it, replacing some pieces with commented three points):
As you can see, depending on the type of tree node (expressionNode), the function responsible for the generation of instructions of this operator is called from a long case.
To return the result in the generated function, use the simple OpCodes.Ret instruction after generating the expression code (If the function returns nothing, for example, Main, you need to add OpCodes.Pop before Ret so that the stack does not overflow).
To determine the entry point , use the SetEntryPoint method (MethodInfo entryMethod) , which is defined in AssemblyBuilder . Also, the entry point method needs to specify the STAThreadAttribute attribute, which indicates that the application is running in the same thread. The code for defining the functions and entry points is in my DefineFunction.
Question : how to generate code for constructions of the following type:
math: Math ← new Math; (assignment to the field of some expression, here new Math).
Answer : First of all, you need to understand that the C # compiler and, accordingly, our compiler, does not generate any calculations on the fly - this is impossible. Those. I want to say that the expression on the right will be evaluated in the default constructor.
And after the expression code (here new Math) is generated, the instruction OpCodes.Stfld or OpCodes.Stsfld is added to the body of this constructor for non-static and static fields, respectively.
CIL is a stack language , which means all operations are performed using the stack. For example, the function call to count the Fibonacci number from the Math class is encoded as follows:
Here, the instance math is first loaded onto the stack, then the argument passed is of type int . After that, the function fibonacci is called using the OpCodes.callvirt instruction (A normal OpCodes.call instruction is used when calling the internal function of a class, then the class descriptor is not required to be passed). The last stloc.0 instruction stores the return value in a local variable numbered 0.
Well, in accordance with the above, I want to note that the first argument for any function is a pointer to an instance of the class from which it is called (this), even if there are no arguments in explicit form.
A more detailed description of CIL can be seen for example on Wikipedia.
, but I'd rather describe how to encode some syntactic constructs using Reflection.Emit.
These operations are simply encoded - first they are pushed onto the stack.
operands, and then the opcode : for arithmetic operations, these are OpCodes.Add, OpCodes.Sub, OpCodes.Mul, OpCodes.Div , and for comparison operations, OpCodes.Ceq, OpCodes.Clt, OpCodes.Cgt .
I want to note that in CIL there is no instruction for comparisons "less than or equal to" or "greater than or equal to", so three instructions are used to generate such comparisons, instead of one (here "<=" is equivalent to "not>"):
OpCodes.Ceq compares the two items in the stack and returns 1 if they are equal, and 0 if they are not equal.
Compared to the coding of arithmetic operations, there is a difficulty in coding this instruction, which consists in the need to somehow mark the labels of conditional and unconditional jumps. However, this is done easily. Using the DefineLabel method in the ILGenerator, labels are created, which must then be used to mark the code using the MarkLabel method. These labels are then used when encoding instructions for conditional and unconditional jumps. Accordingly, OpCodes.Brfalse is a conditional transition that occurs when the value of the top of the stack is zero. And OpCodes.Br is an unconditional transition. For clarity, I gave the code:
This design is a lot like If . Just do not forget that inside the body of this structure, you should always make Pop , because the inner expression is evaluated, and its result is not used. (In Cool, this operator always returns void).
The @ operator essentially corresponds to the expression (a as B) .methodName in C # code, and the Case statement uses dynamic type checking and it corresponds to the expression a is B in C #.
These operators, unfortunately, were not implemented by me.
However, I can say that a cast to a specific type is implemented using the castclass <class> instruction (A cast to a type and a method call is immediately implemented using constrained. <ThisType> [prefix] )
A check of dynamic types is implemented using the isinst <class> instruction.
If the type of the tree node corresponds to the type Id, then the following actions are performed (in the EmitIdValue function):
In this section, I described the CIL instructions and code generation for syntax structures that seem to be the most interesting and complex. For all other CIL instructions, you can refer to the wiki page, which is located at the end of the topic. And you can see the code generation in more detail in the source code.
Compiler errors are different:black, white, red lexical , syntactic , semantic, and general .
For all of them, the abstract class CompilerError was created, containing the error number, position in the code (line and column), type of error and its description.
It is impossible to control lexical and syntactic errors (at least in this project I did not begin to deal with error recovery at ANTLR at the lexer and parser levels ). Here, exceptions are simply caught and error instances corresponding to them are created. All this can be viewed in the file CoolCompier.cs
But the check for semantic errors, mainly type checking, is implemented in all functions “emitters”. Type checking is implemented in a banal way. However, this approach allows recognition of several semantic errors in a single pass. Here is an example: an arithmetic operation, even if an error was detected, the syntax tree traversal continues:
Well, to the errors of a general kind, I attributed the errors like “The file is occupied by another process”, “The entry point was not found”, etc. It is not very interesting to talk about them.
As a component for working with code, as I said, I used AvalonEdit under WPF.
For syntax highlighting, a special file with the .xshd extension is used, which describes the font styles for various words and rules.
For example, comments are indicated as:
Keywords like this:
There are also rules that are needed to determine which sequence of characters is a number or a string and how to highlight them:
All other highlighting rules can be found in the file CoolHighlighting.xshd .
Folding and unfolding of blocks is possible in this editor and implemented in CoolFoldingStrategy.cs . The code is not mine, so I will refrain from commenting on it. Let me just say that thanks to him, everything that is between curly braces can be collapsed or expanded. Maybe it will seem to someone not very correct, since cycles should not have such an opportunity.
Also, with the help of this component, you can make auto-completion, but I didn’t do it, because for that you had to do another architecture at the very beginning, which would allow generating a semantic tree regardless of the code generation.
Finally, on the part of the interface I will describe how to associate the errors found with lines of code. In the code shown below, a scroll occurs and the carriage returns to the place where a specific error occurred:
tbEditor is an instance of the editor component;
compilerError - error (described in the previous section);
And of course this section will not be complete without a screen of the compiler itself:

The code editor is on the upper left, the log and the list of errors are in the lower left. On the right are the buttons to compile the code (you can also just press F5 to compile and run, and F6 just to compile).
For clarity, the program displays a list of tokens and a syntax tree (on the right). When you double-click on a token or a syntactic structure, the cursor is moved and the carriage returns to the right place.
If I started writing a compiler for the Cool language again with the knowledge that I now have, and with sufficient motivation, I would probably single out two more compilation stages - the construction of a semantic tree and the generation of three- or four-address intermediate code.
The semantic tree, as I already said, will allow the implementation of auto substitution and verification of semantic errors in real time before code generation.
The three-address intermediate code will allow the use of optimization techniques that cannot be applied with the current approach. For example, the convolution of commands of this kind and other optimizations:
I decided to post acollection of bydlokod all the labs that I had on the course “Designing Compilers” in 2011 at Moscow State Technical University. N. Bauman (11 option). I think they will be useful to someone.
Description of all laboratory:
, , Microsoft.GLEE . , - , , . (, ).
, .
Those. , .
,
Edge, ( , , .)
, Microsoft :)
lucidchart.com .
, , , .
«. , , 2008, . , . , , . ».
List of CIL instructions , .
Everything!
Introduction
In this article, I, as promised, will continue the description of the development of the compiler for the Cool language, begun in this article.
I recall that the compilation process
')
About lexical and parser it was told in the first article.
The main task of the semantic analyzer is to check the source program for semantic consistency with the definition of the language. This is mainly a type check , i.e. when the compiler checks if each operator has operands of the appropriate type.
The intermediate code generation is needed to generate an intermediate representation of the source code, which should be easily generated and easily translated into the target machine language. For example, a triaddress code is used as such a representation.
The machine-independent code optimization phase is used to make the intermediate code more qualitative (faster or, more rarely, short).
Code generation is a direct translation of the intermediate representation into a set of assembler or virtual machine commands.
The machine-dependent optimization phase is similar to machine-independent optimization, except that special instructions of the target machine (for example, SSE ) are used to optimize the code. It is clear that in our case the CLR takes on these responsibilities.
As can be seen from the diagram, in one stage I have combined three stages from the diagram on the left. This is explained both by the impossibility of generating an intermediate code using the System.Reflection.Emit tool (since a sequence of CIL instructions is generated that cannot be changed) and by the lack of attention to the architecture as a whole.
Architecture
Wow, I don’t know where to start!
I will describe the stages of my code generator, which will be considered:
- Class definition
- Definition of functions and fields
- Generating code constructors and functions
Class definition
It is known that the source code in the Cool language is a set of classes. Naturally, there should be an entry point , and nothing will be done.
So, the entry point is the main function in the Main class. Both class and function need to be registered manually. But more on this later.
In System.Reflection.Emit there are special classes AssemblyBuilder and ModuleBuilder , which are used to build a dynamic assembly and generate CIL code.
To declare the description of any class method is used
TypeBuilder ModuleBuilder.DefineType(string className, TypeAttributes attr, Type parent) In which className is the name of the class, attr is its attributes and parent is the parent (if any).
TypeBuilder is a dynamic type, which will then be used when generating code (for example, for the new operator).
So, at this stage, in the syntactic tree obtained from the parser, nodes with the type “class” are bypassed, as shown in the figure below, and all classes that are in the source code are determined using the method mentioned above.
Optional symbols of the language are displayed in yellow (Here is the name of the parent class. If there is no parent, then the class is inherited from Object ).
I want to note that at this stage only class definitions are created, without their descriptions of the functions and fields within them. If, however, functions and fields are described immediately, then you may encounter an error that the class is not defined, although it is simply described later.
I also want to say that it would be more correct to sort the descriptions in the source code in the correct order before defining classes (for example, the description of class B, which is inherited from A, and then the description of class A). But this, unfortunately, is not implemented for me, therefore all classes should be described in the order in which they are used.
So, at this stage a dictionary has been received.
Dictionary<string, TypeBuilder> ClassBuilders_; in which the key is the name of the class, and the value is its builder.
In conclusion, I want to say that after generating all the code, the dynamic types need to be finalized using the CreateType method (this is done in the FinalAllClasses function).
Definition of functions and fields
After determining the classes, in each class you need to define its functions and methods for further use. This is done using methods
public FieldBuilder DefineField(string fieldName, Type type, FieldAttributes attributes) and
public MethodBuilder DefineMethod(string name, MethodAttributes attributes, Type returnType, Type[] parameterTypes); respectively.
At the end of this stage, two-dimensional dictionaries are filled.
protected Dictionary<string, Dictionary<string, FieldObjectDef>> Fields_; protected Dictionary<string, Dictionary<string, MethodDef>> Functions_; The key of the dictionary of the first dimension is the name of the class, the second is the name of the function or field. The values are the descriptors of a function or field, respectively (These classes will be discussed later).
The problem of sorting descriptions of functions and fields in the source code is not here, as it is when defining classes. Because at the stage of defining classes, information about other classes is used to determine inheritance, and it is used directly in the DefineType function. But, since information on other functions is not needed to define a function (code generation does not occur here), then references to other functions are not needed. So it is possible to generate definitions of functions and fields in any order.
Generating code constructors and functions
And here we are at the most interesting. Here, a recursive traversal of the bodies of functions and constructors of all classes occurs directly.
So, from the previous step a dictionary of all method descriptors (MethodBuilder) for all classes was obtained.
To add a CIL instruction to a method, you must first obtain a special ILGenerator object using
var ilGenerator = methodBuilder.GetILGenerator() , and then use the Emit method of this generator.There are many forms of the Emit method:
void Emit(OpCode opcode); void Emit(OpCode opcode, int arg); void Emit(OpCode opcode, double arg); void Emit(OpCode opcode, ConstructorInfo con); void Emit(OpCode opcode, LocalBuilder local); void Emit(OpCode opcode, FieldInfo field); void Emit(OpCode opcode, MethodInfo meth); void Emit(OpCode opcode, Type cls); OpCode is a virtual .NET machine instruction. A good list of instructions with descriptions is listed here .
And the second argument (it is not always there) is the “builder” or the descriptor of the class or method that was obtained in the previous two stages.
The current function and the current class are the function and the class, respectively, in which the code is currently being generated (bypassing the syntax tree).
For a start, I will explain which classes in my code generator I entered to describe the arguments of functions, local variables, temporary local variables, and class fields. The base class is ObjectDef , which contains the abstract Load (), Remove () methods for loading, and freeing the corresponding object.
- FieldObjectDef - used to describe a field of any class (in a Cool field, this is a feature). When generating code for functions and constructors of the current class, an array of field descriptions is used, which was described above.
- LocalObjectDef - used to describe all local variables in the body of the current function or constructor (In Cool, local variables are declared using the let operator).
- ValueObjectDef is a kind of local variable for storing data transmitted by values. In Cool, such classes are Int, String, Bool.
- ArgObjectDef - the argument of the current function. Contains the number, name and type of the argument.
As you have already noticed, in Cool, every result is an expression. And inside each constructor and each function is also just one expr . This is the most important point of my code generator and for processing this design was introduced EmitExpression function (ITree expressionNode) . The code is shown below (I have shortened it, replacing some pieces with commented three points):
ObjectDef result; switch (expressionNode.Type) { case CoolGrammarLexer.ASSIGN: result = EmitAssignOperation(expressionNode); break; // ... case CoolGrammarLexer.EQUAL: result = EmitEqualOperation(expressionNode); break; case CoolGrammarLexer.PLUS: case CoolGrammarLexer.MINUS: case CoolGrammarLexer.MULT: case CoolGrammarLexer.DIV: result = EmitArithmeticOperation(expressionNode); break; //... case CoolGrammarLexer.Term: if (expressionNode.ChildCount == 1) result = EmitExpression(expressionNode.GetChild(0)); else result = EmitExplicitInvoke(expressionNode); break; case CoolGrammarLexer.ImplicitInvoke: result = EmitInplicitInvoke(expressionNode); break; case CoolGrammarLexer.IF: result = EmitIfBranch(expressionNode); break; case CoolGrammarLexer.Exprs: for (int i = 0; i < expressionNode.ChildCount - 1; i++) { var objectDef = EmitExpression(expressionNode.GetChild(i)); objectDef.Remove(); } result = EmitExpression(expressionNode.GetChild(expressionNode.ChildCount - 1)); break; //... case CoolGrammarLexer.INTEGER: result = EmitInteger(expressionNode); break; } return result; As you can see, depending on the type of tree node (expressionNode), the function responsible for the generation of instructions of this operator is called from a long case.
To return the result in the generated function, use the simple OpCodes.Ret instruction after generating the expression code (If the function returns nothing, for example, Main, you need to add OpCodes.Pop before Ret so that the stack does not overflow).
To determine the entry point , use the SetEntryPoint method (MethodInfo entryMethod) , which is defined in AssemblyBuilder . Also, the entry point method needs to specify the STAThreadAttribute attribute, which indicates that the application is running in the same thread. The code for defining the functions and entry points is in my DefineFunction.
Question : how to generate code for constructions of the following type:
math: Math ← new Math; (assignment to the field of some expression, here new Math).
Answer : First of all, you need to understand that the C # compiler and, accordingly, our compiler, does not generate any calculations on the fly - this is impossible. Those. I want to say that the expression on the right will be evaluated in the default constructor.
And after the expression code (here new Math) is generated, the instruction OpCodes.Stfld or OpCodes.Stsfld is added to the body of this constructor for non-static and static fields, respectively.
Description of some CIL instructions and designs
CIL is a stack language , which means all operations are performed using the stack. For example, the function call to count the Fibonacci number from the Math class is encoded as follows:
ldsfld class Math Main::math ldsfld int32 Main::i callvirt instance int32 Math::fibonacci(int32) stloc.0 Here, the instance math is first loaded onto the stack, then the argument passed is of type int . After that, the function fibonacci is called using the OpCodes.callvirt instruction (A normal OpCodes.call instruction is used when calling the internal function of a class, then the class descriptor is not required to be passed). The last stloc.0 instruction stores the return value in a local variable numbered 0.
Well, in accordance with the above, I want to note that the first argument for any function is a pointer to an instance of the class from which it is called (this), even if there are no arguments in explicit form.
A more detailed description of CIL can be seen for example on Wikipedia.
, but I'd rather describe how to encode some syntactic constructs using Reflection.Emit.
Arithmetically operations and comparison operations
These operations are simply encoded - first they are pushed onto the stack.
operands, and then the opcode : for arithmetic operations, these are OpCodes.Add, OpCodes.Sub, OpCodes.Mul, OpCodes.Div , and for comparison operations, OpCodes.Ceq, OpCodes.Clt, OpCodes.Cgt .
I want to note that in CIL there is no instruction for comparisons "less than or equal to" or "greater than or equal to", so three instructions are used to generate such comparisons, instead of one (here "<=" is equivalent to "not>"):
OpCodes.Cgt OpCodes.Ldc_I4_0 OpCodes.Ceq OpCodes.Ceq compares the two items in the stack and returns 1 if they are equal, and 0 if they are not equal.
If construct
Compared to the coding of arithmetic operations, there is a difficulty in coding this instruction, which consists in the need to somehow mark the labels of conditional and unconditional jumps. However, this is done easily. Using the DefineLabel method in the ILGenerator, labels are created, which must then be used to mark the code using the MarkLabel method. These labels are then used when encoding instructions for conditional and unconditional jumps. Accordingly, OpCodes.Brfalse is a conditional transition that occurs when the value of the top of the stack is zero. And OpCodes.Br is an unconditional transition. For clarity, I gave the code:
protected ObjectDef EmitIfBranch(ITree expressionNode) { var checkObjectDef = EmitExpression(expressionNode.GetChild(0)); checkObjectDef.Load(); checkObjectDef.Remove(); var exitLabel = CurrentILGenerator_.DefineLabel(); var elseLabel = CurrentILGenerator_.DefineLabel(); CurrentILGenerator_.Emit(OpCodes.Brfalse, elseLabel); var ifObjectDef = EmitExpression(expressionNode.GetChild(1)); ifObjectDef.Load(); ifObjectDef.Remove(); CurrentILGenerator_.Emit(OpCodes.Br, exitLabel); CurrentILGenerator_.MarkLabel(elseLabel); var elseObjectDef = EmitExpression(expressionNode.GetChild(2)); elseObjectDef.Load(); elseObjectDef.Remove(); CurrentILGenerator_.MarkLabel(exitLabel); return LocalObjectDef.AllocateLocal(GetMostNearestAncestor(ifObjectDef.Type, elseObjectDef.Type)); } While construct
This design is a lot like If . Just do not forget that inside the body of this structure, you should always make Pop , because the inner expression is evaluated, and its result is not used. (In Cool, this operator always returns void).
Operators '@' and 'Case'
The @ operator essentially corresponds to the expression (a as B) .methodName in C # code, and the Case statement uses dynamic type checking and it corresponds to the expression a is B in C #.
These operators, unfortunately, were not implemented by me.
However, I can say that a cast to a specific type is implemented using the castclass <class> instruction (A cast to a type and a method call is immediately implemented using constrained. <ThisType> [prefix] )
A check of dynamic types is implemented using the isinst <class> instruction.
Processing Id Tokens
If the type of the tree node corresponds to the type Id, then the following actions are performed (in the EmitIdValue function):
- Identifier search in local variables, if not found, then
- Identifier search in function arguments, if not found, then
- Search for identifier in the fields of the current class, if not found, then
- Generate an error that Id is not defined
In this section, I described the CIL instructions and code generation for syntax structures that seem to be the most interesting and complex. For all other CIL instructions, you can refer to the wiki page, which is located at the end of the topic. And you can see the code generation in more detail in the source code.
Error processing
Compiler errors are different:
For all of them, the abstract class CompilerError was created, containing the error number, position in the code (line and column), type of error and its description.
It is impossible to control lexical and syntactic errors (at least in this project I did not begin to deal with error recovery at ANTLR at the lexer and parser levels ). Here, exceptions are simply caught and error instances corresponding to them are created. All this can be viewed in the file CoolCompier.cs
But the check for semantic errors, mainly type checking, is implemented in all functions “emitters”. Type checking is implemented in a banal way. However, this approach allows recognition of several semantic errors in a single pass. Here is an example: an arithmetic operation, even if an error was detected, the syntax tree traversal continues:
protected ObjectDef EmitArithmeticOperation(ITree expressionNode) { var returnObject1 = EmitExpression(expressionNode.GetChild(0)); var returnObject2 = EmitExpression(expressionNode.GetChild(1)); if (returnObject1.Type != IntegerType || returnObject1.Type != returnObject2.Type) CompilerErrors.Add(new ArithmeticOperatorError( returnObject1.Type, returnObject2.Type, CompilerErrors.Count, expressionNode.Line, expressionNode.GetChild(1).CharPositionInLine, expressionNode.GetChild(0).CharPositionInLine)); ... } Well, to the errors of a general kind, I attributed the errors like “The file is occupied by another process”, “The entry point was not found”, etc. It is not very interesting to talk about them.
Interface
Syntax highlighting
As a component for working with code, as I said, I used AvalonEdit under WPF.
For syntax highlighting, a special file with the .xshd extension is used, which describes the font styles for various words and rules.
For example, comments are indicated as:
<Span color="Comment" begin="--" /> <Span color="Comment" multiline="true" begin="\(\*" end="\*\)" /> Keywords like this:
<Color name="Keywords" foreground="Blue" /> ... <Keywords color="Keywords"> <Word>classWord> <Word>elseWord> <Word>falseWord> ... Keywords> There are also rules that are needed to determine which sequence of characters is a number or a string and how to highlight them:
<Rule foreground="DarkBlue"> \b0[xX][0-9a-fA-F]+ # hex number |\b ( \d+(\.[0-9]+)? #number with optional floating point | \.[0-9]+ #or just starting with floating point ) ([eE][+-]?[0-9]+)? # optional exponent Rule> All other highlighting rules can be found in the file CoolHighlighting.xshd .
Folding and autocompletion
Folding and unfolding of blocks is possible in this editor and implemented in CoolFoldingStrategy.cs . The code is not mine, so I will refrain from commenting on it. Let me just say that thanks to him, everything that is between curly braces can be collapsed or expanded. Maybe it will seem to someone not very correct, since cycles should not have such an opportunity.
Also, with the help of this component, you can make auto-completion, but I didn’t do it, because for that you had to do another architecture at the very beginning, which would allow generating a semantic tree regardless of the code generation.
Finally, on the part of the interface I will describe how to associate the errors found with lines of code. In the code shown below, a scroll occurs and the carriage returns to the place where a specific error occurred:
tbEditor.ScrollTo((int)compilerError.Line, (int)compilerError.ColumnStart); int offset = tbEditor.Document.GetOffset((int)compilerError.Line, (int)compilerError.ColumnStart); tbEditor.Select(offset, 0); tbEditor.Focus(); tbEditor is an instance of the editor component;
compilerError - error (described in the previous section);
And of course this section will not be complete without a screen of the compiler itself:
The code editor is on the upper left, the log and the list of errors are in the lower left. On the right are the buttons to compile the code (you can also just press F5 to compile and run, and F6 just to compile).
For clarity, the program displays a list of tokens and a syntax tree (on the right). When you double-click on a token or a syntactic structure, the cursor is moved and the carriage returns to the right place.
Further architecture improvements
If I started writing a compiler for the Cool language again with the knowledge that I now have, and with sufficient motivation, I would probably single out two more compilation stages - the construction of a semantic tree and the generation of three- or four-address intermediate code.
The semantic tree, as I already said, will allow the implementation of auto substitution and verification of semantic errors in real time before code generation.
The three-address intermediate code will allow the use of optimization techniques that cannot be applied with the current approach. For example, the convolution of commands of this kind and other optimizations:
stloc.0
ldloc.0Source Description (Bonuses)
I decided to post a
Description of all laboratory:
- Task 1. Splitting grammar. In this lab, the grammar splitting algorithm is implemented. A detailed description and sequence of steps can be found in the textbook “Aho A., Ulman J. Theory of syntactic analysis, translation and compilation” in the second volume on page 102. I can only add that they use algorithms for removing useless (RemoveUselessSymbols) and unreachable (RemoveUnreachableSymbols a) characters from grammar.
I remember that at that time I was still playing with LINQ. So the code in these functions is far from efficient and beautiful, but rather short. :) - Task 2. Recognition of chains of a regular language. Here are the following subtasks:
- The solution of the standard system with regular coefficients.
Explanation : You need to build a regular expression from the left-side grammar. Those. “Solve” a system with regular coefficients (RMS). Ratios are terminals, and unknowns are non-terminals.
For example, for such a grammar:Σ = {0, 1}
N = {S, A, B}
P = {S → 0∙A|1∙S|λ, A → 0∙B|1∙A, B → 0∙S|1∙B}
S = S
The following expression is obtained (there is a small error, but not the essence):S = 1*+1*∙0∙1*∙0∙1*∙0∙1*+1*∙0∙1*∙0∙(0∙1*∙0∙1*∙0)*∙0∙1*
A = 1*∙0∙1*∙0∙1*+1*∙0∙(0∙1*∙0∙1*∙0)*∙0∙1*
B = 1*∙0∙1*+(0∙1*∙0∙1*∙0)*∙0∙1*
When working on this laba it struck me that by overloading the usual operations in algebra '+', '*', '/', to the corresponding operations 'or', 'concatenation' and 'iteration' in the context of regular expressions, it is possible to solve the IBS method Gauss as well as we solve the usual SLAU! The only thing is that in order to optimize something has been changed.
However, overloading these operations is also a non-trivial task, because these are not numbers, but strings and rules are different here: during concatenation, you need to “glue” strings, for operation 'or' you just need to leave them in the same form, zero is the empty set (Ø), the unit is lambda (λ). Accordingly, it is necessary to optimize these lines in the case of multiplication or addition by 0 or 1, otherwise they will quickly “swell”. - Using a regular expression, which is a solution to the standard system of equations with regular coefficients, construct an NFA (Nondeterministic State Machine).
- Deterministic to simulate the NKA. In short, this is a modified depth search.
- The solution of the standard system with regular coefficients.
- Problem 3. Coca-Younger-Kasami algorithm
Here it was required to implement a syntactic parsing using the Coca-Younger-Kasami algorithm
, , . , , .
. - 4.
. LL(*) ( ANTLR). . .
- 5-8. Cool
----Cool .NET, .
, , Cool, , , : - , ( .pdf):
- Evaluating Simple C Expressions — - .
- iFlop — iFlop .
, , Microsoft.GLEE . , - , , . (, ).
, .
Edge AddEdge(string source, string target) , source — , target — .Those. , .
,
Edge AddNode(string nodeId)Edge, ( , , .)
, Microsoft :)
lucidchart.com .
Literature
, , , .
«. , , 2008, . , . , , . ».
List of CIL instructions , .
GitHub
Everything!
Source: https://habr.com/ru/post/136714/
All Articles