Tarantool: how to handle 1.5 billion requests per day?
Report “ Tarantool: how to handle 1.5 billion requests per day? "- another in a series of transcripts from the Mail.Ru Technology Forum 2011 . For details on how the report decryption system works, see the article “Reverse” of the Mail.Ru Technologies Forum: High-tech in event-management . There, as well as on the Forum website ( http://techforum.mail.ru ) - links to transcripts of other reports.
( Download video version for mobile devices - iOS / Android H.264 480 × 368, size 170 Mb, video bitrate 500 kbps, audio - 64 kbps)
( Download video version of higher resolution H.264 624 × 480, size 610 Mb, video bitrate 1500 kbps, audio - 128 kbps)
( Download presentation slides, 520K)
It is difficult to present this speaker because everyone knows him. Each of you, I am sure, use products to which Kostya had a hand. This is, first of all, MySQL. For many years Kostya has been developing this popular database, which is used, if not 100%, then 90% of Russian sites for sure. Today Kostya works in the Mail.Ru Group company . Kostya today will tell us about what we have done, how it works and, most importantly, what kind of performance this will allow to get on your services.

')
Good day. You are very much today. Thank you for coming! I have already been introduced, so I would just like to add that I am still an engineer at heart and in the case. Rather, I do not lead, but actively participate in the development of Tarantool, so if you are interested, today you have the opportunity to learn everything about him. Anyway, this report, in addition to philosophizing on the topic of the future of the DBMS, about Tarantool. Therefore, I would like to understand the people who came here today, to understand why you did it.
Who came to this report to try Tarantool, to learn more about it in this forum? There are such people?
This is great because, on the whole, Tarantool is a system that is developed in Mail.Ru Group and is most actively used in our company, but has a much wider applicability. This is an open-source system, which is well, in my opinion, documented, we have connectors to many programming languages - Python, Ruby, Perl. Recently, just two days ago, one of the community members wrote a new connector for Python. Therefore, I hope that the result of our conversation today will be that you try Tarantool. And, maybe, you will tell, why it sucks - it will be pleasant to me to hear also such response.

What will I talk about? Since the topic of the report is rather ambitious, I will talk about the place of Tarantool in the database ecosystem: why we now have so many different data storage solutions, why this number is adequate. Then we go directly to the system, to the analysis of what it can do. I will finish with a story about my plans, about the plans of the team, about what features we will add to the product, etc.

There is such a picture, I literally half an hour dragged all these logos. Who among you knows more than half of these logos? Minority. Those. many of you know MySQL, maybe Memcached, maybe PostgreSQL. That's all, actually.
Today we heard a report on Hadoop and saw that in fact all these systems are very widely used and very popular. And this is all open source system. We see that the world of system software is increasingly moving toward open source. The only non-open source system developed by former Yahoo programmers is Citrusleaf. This is a fairly feature-rich commercial system.
If we analyze this slide in terms of the characteristics of the data for which the systems mentioned are intended, we will find two dimensions. The first dimension is the amount of data. We see - Cassandra, Hadoop, Voldemort - these are systems that are designed to manage a huge amount of data. On the other side of the picture we see systems that often work with not very large amounts of data, but they provide very high-performance access to this data. The second dimension is the level of data structure. And these are only two metrics by which we can compare these systems. In fact, the dimensions of the NoSQL world are much larger. Why did the NoSQL movement arise at all and why do we see this wealth? In my opinion, there are 3 main unsolved problems in the world of traditional DBMS. Problems can be found 10, 20, but the main and really poorly solved problems of relational databases are as follows:

The first problem, the problem of horizontal scaling, is that secondary keys, complex queries, stored procedures are rather poorly scaled into a cluster of tens or hundreds of computers, i.e. you cannot simply add nodes, like, say, in the previous report you heard that you can simply add new nodes to Hadoop. In principle, the problem is solved. There are enough scalable SQL systems, which, however, are very expensive - NonStop SQL, Teradata. They are used, for example, in the banking sector. That is, there are SQL systems that scale horizontally well, but so far these solutions are not open source.
The second problem is relational DBMS: they are designed for the fact that you first define your data schema, and then you can write ad-hoc queries to the data. Those. you can write an arbitrary SELECT, an arbitrary JOIN, etc. It often happens the other way around. The data schema changes very dynamically, but the requests are more or less fixed - they change with the data schema, but that’s all.
Well, ultimately, problem number 3 is performance. It's like the price for gasoline, that is, if it was one 20 years ago and the engines were
And, despite the fact that the problems of traditional DBMS are generally understood, studied, and recognized by the community of scientists and practitioners, the world of NoSQL responded not just with new solutions to these problems, but with a fresh start, an explosion of ideas and often where to actually blow up do not need anything. For example, in a field such as data models. Those. NoSQL world rejected the famous model of Edgar Codd and proposed paradigms such as, for example, Column Storage - column-oriented storage, Key-Value Storage, JSON and XML formats.
Also, different data consistency models are reviewed and applied in practice. Here we can recall the previously mentioned today CAP-theorem, which determines the ratio of consistency, data accessibility and the stability of a DBMS cluster to splitting, that is, dividing into unrelated segments. As many try to interpret this theorem, an application programmer needs to choose two properties of the data model from three. For example, we can choose the consistency of data on each node, and eventual consistency between the nodes, when eventually all the nodes will be consistent with each other.
New data access languages are also actively being offered, for example, but these are more likely examples from history, Object Query Language , XQL, NQL, etc. Ten years ago XML DBMS were very popular, but where are they now?
And finally, we are witnessing a constant evolution of data storage algorithms, which is always very important, and the creation of a huge number of new scaling methods, such as consistent hashing , master replication , etc.
What is the future of the DBMS world, what will the NoSQL movement lead to? In my opinion, the world of storage solutions will expand, and application engineers will be forced to know that there are NoSQL storage, there are relational storage and there are distributed clusters like Hadoop. Thus, from the variety of products in the future, three niches are formed, three basic solution clusters, one of which is relational DBMS, which, naturally, will remain for a long time.
What will be the result of numerous experiments with data models? Take, for example, the Redis paradigm, also known as data structures server, will this approach be spread? In my opinion, data models will also be forced to stabilize around two principal approaches: an approach that implies the presence of model abstraction from presentation, and there is still no better abstraction than the relational model, and the data representation model itself.
At this point I would like to complete the review of the world of modern DBMS. The forecast is a thankless task, but in order to give an idea of the place of Tarantool in the world of NoSQL DBMS, I decided to give some general picture.
Tarantool is a high-performance storage that stores all data in RAM. Often at first you hear such an objection - “but this is very expensive.” But, if you compare RAM with flash memory, then it turns out that RAM is cheaper than Flash.
Tarantool is a persistent repository. Data is stored in RAM, but all data changes are atomic, i.e. everything in Tarantool is written to disk.
Here I would like to digress a little and give an example from the past. If we recall the history of MySQL, then it all started from the very beginning, because the MySQL user community did not need transactions, reliability and atomicity of data storage was not necessary. MySQL
Based on the MySQL experience, I was convinced that transactions are required for any modern industrial storage system. This is a fundamental parameter that determines the remaining parameters of the system architecture, and therefore Tarantool now supports atomic operations and at the moment we are developing full transaction support. In the next version we will have it already.
In the area of the data access language, the Tarantool solution is a SQL language, although there is support for other programming languages.
However, it should be understood that in terms of the data model, Tarantool is a key-value storage, i.e. our main data access scenario is to get the value by key. Thus, not all SQL functionality is implemented.
In addition to simple INSERT / UPDATE / SELECT / DELETE queries, we support Lua stored procedures that allow you to be very flexible in determining which data access scripts you have. The presence of stored procedures allows you to turn Tarantool from a data server into a business logic server, since it becomes possible to program an arbitrary data storage format, arbitrary data consistency invariants, arbitrary queries.
Question from the audience:
How is data persistence maintained?
We use logging, i.e. all records are logged to disk. Now I will talk about this, but first about the data model.
Our data model is not an invention. I would describe it as a simplified relational model. The basic element of storage is a tuple. A tuple has any dimension; it’s just an arbitrarily long list of fields associated with a unique key. Each tuple belongs to some space (space). You can define indices by the fields of a tuple. If we draw analogies with relational DBMS, then “space” corresponds to the table, and “fields” correspond to columns. We support two types of data — integers and strings — and two types of indices: hashes and binary trees.
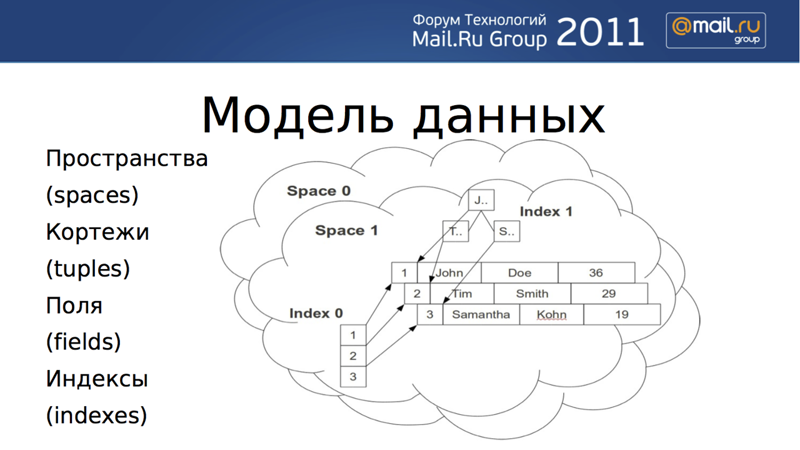
Indices can be both simple and compound, and any index can be used for searching. However, in each space, a simple primary key must be specified, which should be accessed when it is inserted, updated, or deleted. You can access by a composite secondary key, for example, by fields 3 and 5, or by fields 7, 9, 11.


Again, we are not any ideologists in the field of data access language - our client implements SQL access, and in the area of connectors from other programming languages we follow agreements from the world of traditional DBMS. This is what PHP looks like:
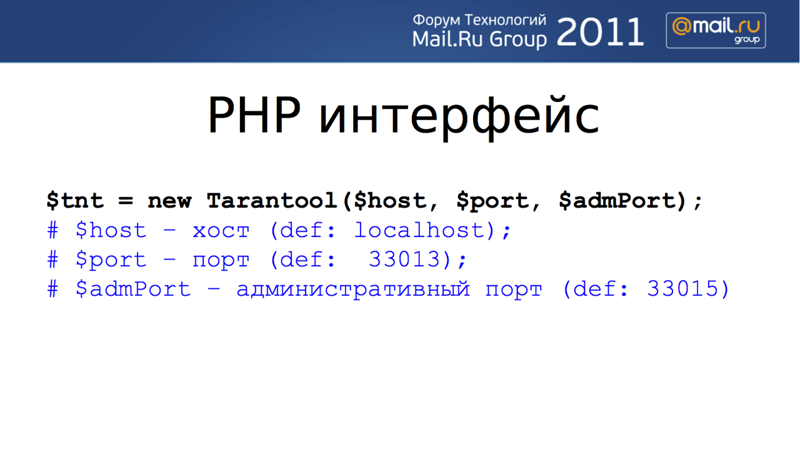
To get started, you need to establish a connection to the database. To execute the query, it is necessary to determine which space of the tuples is addressed. At this stage, all spaces and all objects in Tarantool are numbered, accessed by the object number. There is an index number, a space number, and so on. In the next slide, we see how after the connection is established, the tuple is inserted, then the tuple is accessed by the primary key, and the data is returned, in the case of PHP, as a simple array. You can also update the tuple in the desired space using the key.

In the case of sampling tuples, we select the key number for which the request is made — either the primary key with the number 0, or other keys.

After giving a general overview of the functionality, I would like to move on to how we differ from other NoSQL systems with which you probably already worked.
I'll start with the performance. In general, since this is an in-memory data warehouse, the performance is initially substantially higher than that of traditional DBMS, such as, for example, MySQL. We use asynchronous I / O and asynchronous support for multiple connections. We easily hold 10,000 active compounds. Our performance on one machine, despite the fact that we write all the changes to write ahead log, i.e. log all changes to disk, up to 100,000 UPDATEs and INSERTs per second. For read requests on this machine, we achieved a performance of 260,000 SELECTs per second. These are not such super numbers: they are comparable to the performance of Memcache or Redis.

And what is leytencie? How much is the delay in response?
The question is very good.
The benchmark referenced by the slide was made in 10 threads and each thread sent 10 requests at a time. The benchmark was built in such a way that the client side received multiple requests in a batch mode and sent answers in parallel. As soon as the server sent the packet, the client read the packet. Why did we choose such a performance measurement scheme? Because we had only two machines at our disposal, whereas in order to load the Tarantool, we still need a cluster, a hundred or more machines. With this approach to measuring performance, latency is, of course, higher than what can be observed on real workload. In fact, the time it takes to execute a single query depends very much on whether it modifies data or not. At SELECT, latency is minimal: the server simply reads data from memory by key and sends it to the client, there are no locks.
Generally speaking, Tarantool is a lock-free system, access to all data, at the level of data structures and caches, is performed sequentially, while at the network level, of course, parallel processing of multiple connections is supported. To implement this approach, we use the so-called coroutines, also known as "light" or "green" streams.
If the request changes the data, then the changes must be recorded on the disk. To implement packet writing, an algorithm is used that is often referred to as “group commit” in serious DBMS, that is, simultaneous recording of several accumulated changes to disk. The easiest way to imagine this is as a train connecting two stations - the frontend and the backend. All requests that need to be recorded on the disk are accumulated on the “apron” of the process responsible for working with the network (frontend). Then all these requests are “immersed in the train,” that is, buffered and written to disk. As soon as one group of requests is written to disk, the “train” returns after the next group of requests. Thus, the delay in performing an INSERT / UPDATE / DELETE query depends on the moment at which you are on the platform. The maximum on modern equipment is 0.01 seconds, the recording time of an arbitrary block on an arbitrary cylinder of a hard disk.
What file system are you using?
We use any file system. If you are on this particular, for example, Linux, ZFS works - please. In this case, we use the POSIX API for working with files. The only non-POSIX call we use is the fallocate () call, which, in my opinion, is supported on JFS, XFS and EXT4.
Why do we use fallocate ()? This is due to the way the modern file system works. It needs to be explained in more detail, let me do it later.
A more specific question regarding clients is how we access simultaneously 1000 GETs of the same key from one place, from one client. Can we somehow proxy this case? Do not send 1000 requests to ...
How does GET work and can it be proxied? Tarantool has a client protocol. For example, Memcache supports text and binary protocol. We have done a similar way. Mostly used is a binary protocol in which GET is one of the commands. The command code takes 4 bytes in the packet header with the request, the entire header takes 12 bytes. The second four bytes of the header contain the Request ID. Request ID is a means for marking, unique identification of a specific request. In response to a request, the server returns the request id transmitted to it. This allows you to proxy requests is quite simple, and Mail.Ru Group is actively used. , , Tarantool, request-id Tarantool' .
commit, ?
, . . group commit, . wal_fsync_delay — 0.01 . , Linux. Tarantool, MySQL. , , NUMA- MySQL, . — . , - Mail.Ru wal_fsync_delay 0.01 , .
Tarantool?
Yes there is. .
, Tarantool MySQL?
. , Tarantool, MySQL, Mail.Ru Group, . MySQL, .
. . , GET, , 700 . . , .
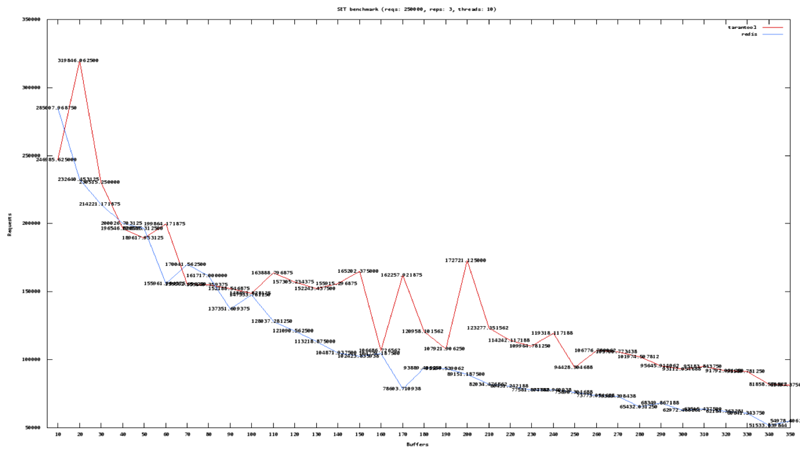
SET' . , (Intel Core I7, 7200 ), 300 000 700 000 .
, . 1.5 1.4. UPDATE's. , UPDATE'. .
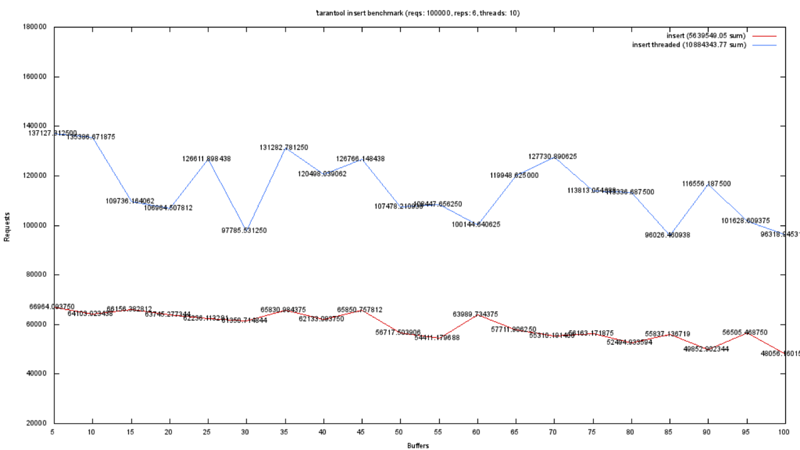
, , , . Tarantool Key-Value, Trantool , .
auto-increment. PHP, NoSQL Tarantool, - -. UPDATE, , , . , . -, , , . .


Tarantool, . , , — .. space 0. , . , — , .

, , . , Tarantool .
« = tuple ()». Because , . : № 0 — , № 1 — , .. . № 2 , , , , . , . , . top bottom, UPDATE , box.update() — , callback . , UPDATE , , , printf(). , , =p=p=p, '=' () 1 'p' ( ) top, '=' () 2 'p' ( ) bottom, '=' () top val.

UPDATE, , , , , . , . .

, , Lua. , Lua . Javascript…
. , LuaJIT — just-in-time compiler, open source . — . Lua , , , - . , GitHub Tarantool, .
, , , - — ?
, -, - . , , 2 2 max+1.
, . , . Tarantool . ? , , WAL. 1 Tarantool 1 . , fiber', coroutines - , -. , ; , , , multi-threaded , . ? nodes, Tarantool.
? Mail.Ru Group.
- , , . , , , , . Those. , . — Memcache, Memcache- Memcache expiry — , , , , Lua. Mail.Ru. 4 , 2 Tarantool'. 2 , 2 . 60 100 , Mail.Ru .
, , , Tarantool , Tarantool , , , . , . , , , . - , 400 , . , . Tarantool 120 , , . , 2 , 60 . production , , . , , 20%.
. MongoDB. Mongo , . , . , ..
Mongo ? Mongo — , c Write Ahead Log', ?
, .
, Tarantool . Tarantool snapshot', . , , . copy-on-write, Redis. Write Ahead Log. , Write Ahead Log'. , 0.01 .
MySQL , , , . Tarantool ?
. Tarantool, , MSQL? MSQL , Write Ahead Log, , .. MSQL . Tarantool Write Ahead Log — . : Write Ahead Log . , , , . Write Ahead Log (log sequence number, LSN), , , , .
— , : 5, 8. , , , , . ?
, . , . , .

, — , .
, 6, 83, 1, 21, 8 .. : « 44 , 83 ». ? : , , friend-requests .. 5. . 30 friend-requests, 20, .. 20. .
Tarantool. 5 . 2 , — « ». Tarantool , . , , , . , SQL- ? .
— « ». , , , . .
, .
notification_push() . — user_id, . MySQL, , MySQL, .
notification id . .
GitHub.
notification_push(). unread count, UPDATE . .

. , Tarantool — , , . , -, , , , . , , CAP-.

Tarantool, , Voldemort, Riak, , . , 100 — , Mail.Ru, , 4, 6 , .. . , .
, , , , --, . : . Thank.

This text is a transcript of Osipov Konstantin's report at the Mail.Ru 2011 Technology Forum , held on November 16 in the center of Infospace. Details about the technology of creating texts of reports based on video recordings can be found here: “Wrong side” of the Mail.Ru Technologies Forum: High-tech in event-management . Video versions of other reports (including versions for mobile devices) are available on the Forum website - techforum.mail.ru . Text versions of the reports will be published here and on the Forum website every week or less often in a similar format. Please report in the "lichku" about typos in the text.
Source: https://habr.com/ru/post/136288/
All Articles