Go: gorutin performance
Introduction
In this post we will look at the performance of goroutine. The gorutines are something of a kind of very cheap and lightweight flow. Most of all, they probably resemble the processes in Erlang.
According to the documentation, we can use hundreds of thousands of gorutin in our programs. And the purpose of the article is to verify and specify it.
Memory
The size of the memory allocated for the gorutina is not documented (it says only that it is several kilobytes), but tests on different machines and a lot of confirmations on the Internet allows us to specify this number to 4 - 4.5 kilobytes . That is 5 GB to you with a reserve will be enough for 1 million gorutin.
Performance
It remains to determine how much CPU time we lose when we select the code in the mountain. Let me remind you that for this you only need to put the go keyword before a function call.
')
go testFunc()Gorutiny - is primarily a means of achieving multitasking. By default, if the GOMAXPROCS variable is not set on the system, the program uses only one stream. To use all processor cores, you need to write their number in it: export GOMAXPROCS = 2. The variable is read at runtime, so you will not have to recompile the program after each change.
It turns out that time is spent on creating gorutin, switching between them, and sometimes even moving to another stream and sending messages between the gorutines in different streams. To avoid the latter, we start testing with just one thread.
All actions are performed on a nettop with:
- Atom D525 Dual Core 1.8 GHz
- 4Gb DDR3
- Go r60.3
- Arch Linux x86_64
Technique
Here is the generator of the functions studied:
func genTest (n int) func (res chan <- interface {}) {
return func (res chan <- interface {}) {
for i: = 0; i <n; i ++ {
math.Sqrt (13)
}
res <- true
}
} But the set of functions obtained subtracting the root from 13 to 1, 10, 100, 1000 and 5000 times respectively:
testFuncs := [] func (chan <- interface {}) { genTest(1), genTest(10), genTest(100), genTest(1000), genTest(5000) }Now, I run each function X times in a loop, and then in X Gortinins . And then I compare the time spent. Also, do not forget about garbage collection. In order to minimize the impact on the results, I obviously call her after all the gorutines work out and only then mark the end of the operation.
Well and, of course, for accuracy, each test is carried out many times. The total time to complete the program took about 16 hours.
One thread
export GOMAXPROCS= 1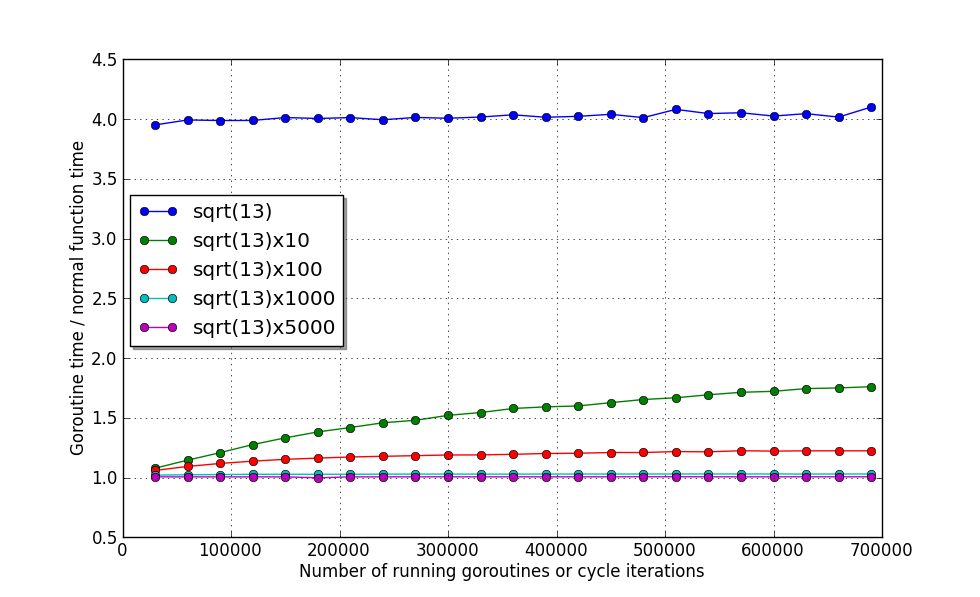
It can be seen from the graph that the function, the execution time of which is approximately equal to the calculation of the root , will spend approximately 4 times more time when it is allocated to mountain science.
Consider the 4 remaining functions in more detail:

It can be seen that even with 700 thousand simultaneously working Gorutin productivity does not fall by more than 80%. The great thing is that even with the function running time approximately equal to calculating sqrt (13) 1000 times , the overhead head is only ~ 2% . And at 5000 times - only 1%! And these values, it seems, practically do not depend on the number of working gorutin! That is the only limitation - memory.
Conclusion:
If an independent section of the code will be executed (including the waiting time) is more than the calculation of 10 roots, and you want to execute it in parallel, then boldly select it into a mountain. Although if you can safely collect 10 or even 100 such sites together, then the performance loss will be only 20% or 2%, respectively.
Multiple threads
Now consider the situation when we want to use several processor cores at once. In my case there are only 2 of them:
export GOMAXPROCS= 2Now run the test program again:
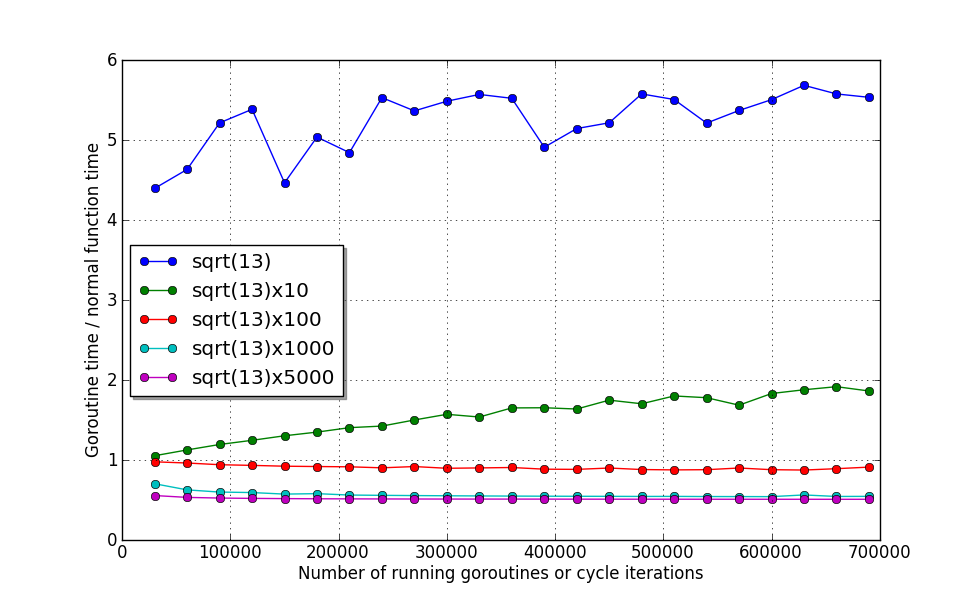
It is clearly seen here that despite the fact that the number of cores has doubled, the time of the first two functions has been working - on the contrary, it has worsened! Albeit slightly. This is explained by the fact that the cost of transferring them to another thread is more than the execution :)
So far the planner cannot resolve such situations, but the Go authors promise to correct such a flaw in the future.
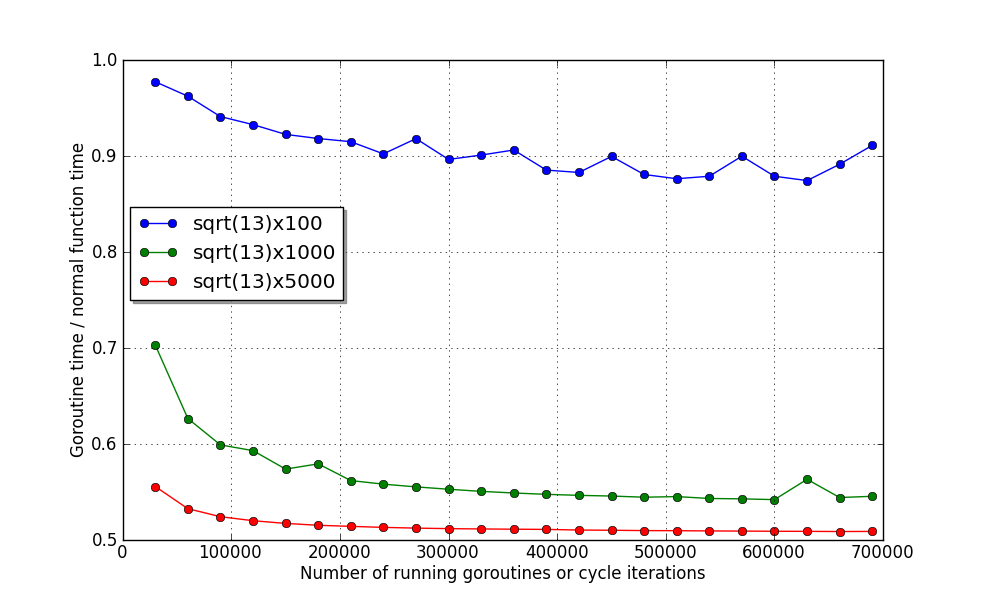
And here you can see that the last two functions use both cores almost to the fullest. On my nettop, every single function is performed in ~ 45µs and ~ 230µs, respectively.
Conclusion
Even though the youth of the language and the temporary implementation of the scheduler is not enough, the performance is very good. Especially in combination with ease of use.
As an advice, I can suggest that you try not to use functions that are less than 1 microsecond as gorutin. And feel free to use working more than 1 millisecond :)
PS It would be nice to see similar tests in other languages, such as Erlang. Wikipedia reports successful attempts to run up to 20 million processes on it!
Source: https://habr.com/ru/post/135587/
All Articles