Crackme Analysis # 1 by PE_Kill
Foreword
I haven't been researching anything for a long time, so to speak, I retired. But then I came across another hand-made article of many well-known in certain circles PE_Kill'a. Because I had the opportunity to solve his previous work in the framework of CRACKL @ B Contest 2010 , which, in turn, was quite interesting, I decided to look at his new “brainchild”.
What awaits you under the cut: fake CRC32, brute key for RC4, factorization for RSA, as well as the use of collisions for MD4 and the generation of two different messages with the same hashes. All this and more under the cut.
The article is not designed for a beginner, I will not chew all actions. The purpose of which is to write keygen.
Introduction
As mentioned above, for a long time I didn’t do the locating. Therefore, it was necessary to spend some time on the “swing”. Also partially restore your toolkit, because I only have OllyDbg and IDA . The latter will not be used. And recalling his task from the contest, I was waiting for something interesting that would make me activate my brain much more than usual. And I was not mistaken.
')
To battle
Receiving intelligence
Well, first we need crackme itself. We open it in Ollydbg and see that it is packed with UPX, well, now they hardly frighten anyone. I took the path of least resistance, and unpacked it with QUnpack . Further, following my technique developed over the years, I decided to analyze it using different crypto, hash, cheksum algorithms. For this, I used the SnD Reverser Tool , which told me that I had found CRC32 , RC4 , MD4 . Now, knowing all this, you can proceed to more active actions.
In the rear of the enemy
So, having finished the static analysis, we proceed to the dynamic analysis, i.e. Let's go debug. Again, open the crackme (hereinafter - the crack) in OllyDbg (hereinafter - olka), but not the original, but unpacked. Press Ctrl + G and enter GetDlgItemTextA, so we go to the beginning of this function, set a breakpoint and start it. Enter the name and some license for the test and click Check. So we started at our stopping point, press Alt + F9 and get into the code of our quacks right after calling the function to get the name.
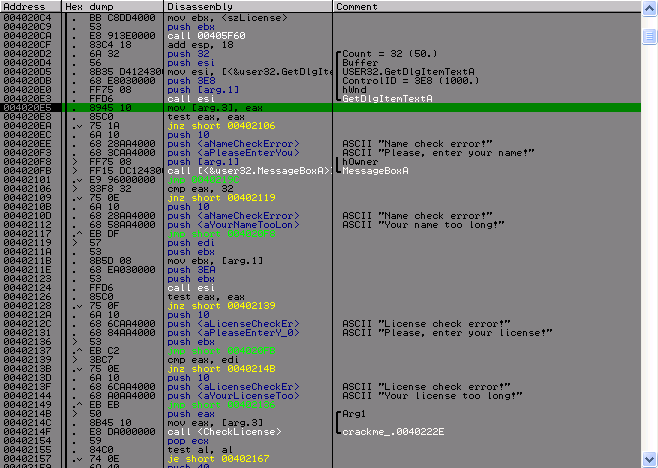
Then there are two checks of the length of the name, the first is that the name was entered, and the second is meaningless. In the second check, if the length of the name is 50, we are informed that the name is long and exit. Why it is meaningless, but because the name is obtained as follows:
GetDlgItemTextA(hDlg, IDC_NAME, szName, 50); This means that the maximum it can read is a string no longer than 50 characters, where the 50th character is the end of line character, and we have that the length of the string will never exceed 49 characters. Similarly, with the license, but it is not critical. After all this, there is a cherished function, in which all the most interesting happens, I called it - CheckLicense.
In enemy trenches
And so we are in the heart. The first couple of functions is the translation of the characters of the license into upper case, and then the transfer of the license into an array of bytes and there is already a check on the length of the license.
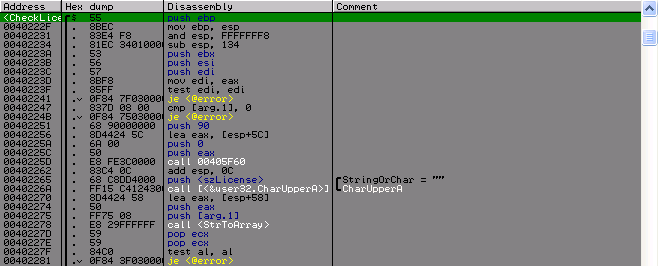
In the line feed function it will be seen that it checks the license for alphabetical compliance (0–9, AF), i.e. A license is some kind of data array, translated into a hex, and at the end it is checked whether the resulting array is not equal to 0 × 90 bytes. It follows that the license must be 0 × 90 * 2 = 0 × 120 (288) characters long.
After all this, we return to the main function. Next comes the check sum of the first 0 × 8C bytes of this array (hereinafter, we will call this array a license) with a 4 byte number that is at the end of the license.

And then there are 10 circles of manipulations with the name, the result of each circle is placed in a separate element of the array of 4 byte numbers. Looking ahead to say that this array will be the key for RC4, so I will call it a key.
Round 0–2:

All circles except Round1 are used once, therefore they were perceived by the compiler as inline functions, but round1 itself will still be used twice at the end as a kind of function for getting the control data.
Round 3-4:
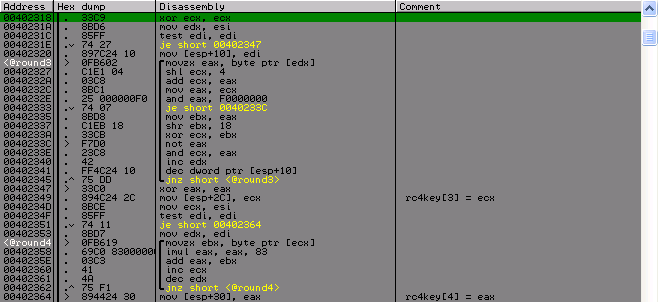
Round 5–7:
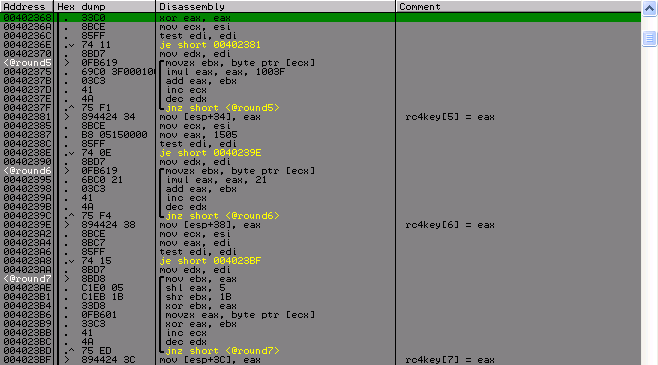
Round 8–9:

As you can see, round9 is identical to the calculation of the control sum of the license, which was at the very beginning.
After all this, with a key, by simple manipulations, we find the values for the subsequent xor of the same key. Also, this value will be used in another check after decrypting the very first 0 × 8C bytes of the license using RC4 and with the key we received from the name. And in another manipulation, the result of which we need further.
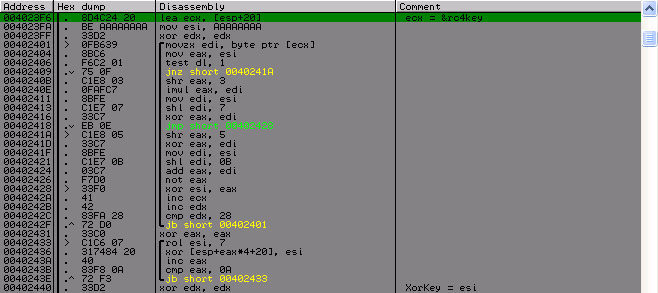
Then we get two more values that we need next. With XorKey, we get the number of bits to shift, and from the key we need the byte, which we should receive when shifting a certain value by the number of bits that we received above. Well, actually the very decoding on RC4. As I determined that this is it, well, first of all I know the list of possible algorithms that are used here, and secondly by the key initialization algorithm, who have met this algorithm more than once, I also think that I would quickly recognize it.
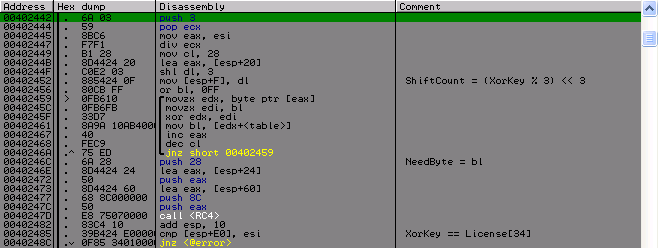
And here is the test where this value was needed. After decryption, we should be in the License [34] (if we consider the license as an array of 4 byte values, which we will continue to do) the value is identical to XorKey. This ends the easiest part of this crack. It took me much more time and effort to go further.
Next comes the CRC32 count of 8 bytes of the license, which should be 0xFFB97FE0. If everything passes, then further these 8 bytes serve as a key to decrypt two hard-coded values using the RC4 algorithm and the output should receive two faces. So, here is the first interesting place that is in the quacks. Googling, I did not find any collisions for RC4 that would help me find the key, so the decision was made to crack. But getting 8 bytes in the forehead is a bit silly and long. It is good that I have already dealt with a fake CRC32 and I understood in which direction to walk. For those who do not know, in a couple of words, it sounds like this - “with any data you can get the CRC32 we need, you just need to add / replace 4 necessary bytes”. Details about this can be found here . From here we have that now it is necessary to not 8 bytes, but 4, which makes life much easier for us. I decided not to write abstruse brutere using different technologies, multithreading, parallelization of calculations. I wrote a simple single-stream brutere, which on my AMD II X2 250 found the key in 15 minutes.
This is what my brutera looks like:
int main() { uint32_t key[2] = {0, 0}; uint8_t *pkey = (uint8_t *)&key; rc4_key skey; uint32_t rc4_data[2]; do { fix_crc_end(pkey, 8, 0xFFB97FE0); prepare_key(pkey, 8, &skey); rc4_data[0] = 0xE6C5D5E1; rc4_data[1] = 0x41C98EAB; rc4((uint8_t *)rc4_data, 8, &skey); if (rc4_data[0] == 0xFACE0001 && rc4_data[1] == 0xFACE0002) { printf("Key: "); for (int i = 0; i < 8; i++) { printf("%02X", *pkey++); } printf("\n"); break; } } while (key[0]++ <= 0xFFFFFFFF); printf("\n\n\t\tFin!\n"); return 0; } 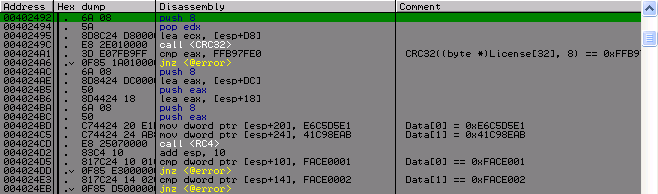
I found the right key, now I can generate keys that will pass all the checks passed above. Knowing all this, you can present a general view of the license:
typedef struct _LICENSE { unsigned char M1[0x40]; unsigned char M2[0x40]; unsigned int FaceKey1; unsigned int FaceKey2; unsigned int AfterXorKey; unsigned int LicenseCheckSum; } LICENSE, *LPLICENSE; The last 4 values have already been disassembled, only the first 0 × 80 bytes of the license remain, looking ahead to say that these are two messages of 0 × 40 bytes.
After the face immediately goes the call of the function to which the pointer to the license is transmitted, I have already signed it as RSA . I will try to explain a little how I understood it. After entering inside this function, 3 identical functions go in succession, into which a pointer to the data array, its size and a pointer to the buffer with the result are passed. This function reads from the array byte-by-byte and in reverse order, i.e. from the last element of the array to the first. This is very similar to the initialization of large numbers. This is the first thing that occurred to me.

The second call to this function only confirmed my guess when I looked at the dump on the array from which initialization is going, I saw these cherished three bytes 01 00 01. This value is very often used as an exponent in the RSA decoding implementation. It follows that the first function initialized the public key N. Then I pulled it from the dump and factorized it, for factorization I used msieve under the GPU. The key is small, only 256 bits on its factorization took a little more than 4 minutes.
I used to always try to adhere to the rule that you need to use the same libraries and classes in keygens as in the victim. So I decided to look for clues that the library for large numbers was used for. A little bit of tracing came across such a message, having typed in the text of the message in Google quickly found the library that is being used, it turned out to be BigDigits .

After that there is a check that the 6th element of the first message equals the same element of the second one. And also that this value when shifting to the right on the ShiftCount bit had the low byte is the same as NeedByte. All these two values we obtained above.
After that there is a check that the CRC32 of the first and second messages were not equal, then the same comparison is only a function of round1. After everything is disassembled, you can see that there seems to be nothing special about this part of the crack, as well as the next.
And at the very end are the MD4 hashes of the first and second messages, and if they are equal, then we successfully passed the test. But wait, if these messages should have a different checksum for the two functions, then the messages should be different, but they should have the same hash, which does not fit.
And here Google again comes into play with the query “md4 collisions”, and the truth about infa for MD4 is, and different, there are voluminous articles, and there are superficial ones. And in one of these articles I find that the Chinese were able to create two different messages of 0 × 40 bytes with the same hashes, here it is. Now we go to Google with the following request “md4 collisions sources” and true, there are sources for finding two such messages, but they were written under Linux, where the random function returns a 4-byte number, and in rand returns just 0 and RAND_MAX ( 32767). Because of what I had problems for a long time, why it generates the wrong messages for me. After the prompt, I rewrote the random function with Delphi, and it all worked out with a bang.
We write keygen
I will not describe all the steps in writing keygens, and only pay attention to some important points. First we create a key for RC4 from the name, I will omit it, there is nothing complicated there, for the lazy, you can simply rip this whole part. Next you need to find the value for the key key and poxorize the key itself, then from this value find ShiftCount and NeedByte. This part can also be ripped, to find the desired byte, you also need to rip the table of 256 bytes. Write the XorKey value to the license according to the structure above. You can also write down two values, which are the key for finding faces, they will be constant and the same for all. After that, you need to generate two messages, but the fact is that there, if you remember, the 6th element must have a certain format. The function of generating messages itself has no parameters, but since you need to transfer two values to it, it is ShiftCount and NeedByte. We change the prototype and add a couple more lines to the code of this function itself. It was:
if(X0[ 5] != X1[ 5]) continue; And it became:
if(X0[ 5] != X1[ 5]) continue; else if (((X0[5] >> c) & 0xFF) != b) continue; where c is ShiftCount, b is NeedByte.
Then the messages are placed in X0 and X1, respectively. Then we combine these messages into one big one and thrust it into RSACrypt. The decoding itself goes in blocks of 0 × 20 bytes, so we will encrypt it. But because of this, I also had problems, who do not know, the message (M is our block of 0 × 20 bytes) should be less than the public key (N), in cracks it is not taken into account, and it decrypts everything. Therefore, we must take this into account. I added a check to the encryption function, if N <M, then we exit and generate new messages, because of which the license generation time is delayed to 15 seconds. After everything has been successfully encrypted using RSA, we encrypt the entire license without the last value in the structure using RC4 with the key we received from the name. And the last step is to calculate the checksum of the part of the license that was encrypted using RC4 and write it to the last value of the structure and translate the entire license to a hex string.
That's all!
Materials
• www.rsdn.ru/article/files/classes/SelfCheck/crcrevrs.pdf - fake CRC32
• www.en.wikipedia.org/wiki/MD4#Collision_Attacks - MD4 collisions
• www.google.com
• www.wikipedia.org
Sources
• github.com/reu-res/Keygen-for-CrackMe-1-by-PE_Kill - Bruter and keygen
PS Keygen accepts Cyrillic, but it depends on how the console is configured. I personally did not accept from the console, and if you are hard-coded, then everything is fine. I was lazy to rewrite under the windows.
Source: https://habr.com/ru/post/135255/
All Articles