Hidden Markov models in speech recognition
The most rapid and effective interaction between people occurs through oral communication. With the help of speech can be conveyed various feelings and emotions, and most importantly - useful information. The need to create computer-based interfaces for audio input-output is beyond doubt, since their effectiveness is based on almost unlimited possibilities of formulation in the most diverse areas of human activity.
The first electronic machine, synthesizing English speech, was presented in New York at a trade show in 1939 and was called voder, but the sound that it reproduced was extremely unclear. The very first speech recognition device came out in 1952 in the second year and was able to recognize numbers.
The process of speech recognition can distinguish the following difficulties: arbitrary, naive user; spontaneous speech, accompanied by agrammatism and speech "garbage"; the presence of acoustic noise and distortion; the presence of speech interference.
')
Of the variety of methods in this article, we will consider the possibility of creating a statistical model using hidden Markov models (SMM).
When analyzing a natural language, the first step is to determine: to which part of the speech each of the words in the sentence refers. In English, the task at this stage is called Part-Of-Speech tagging. How can we determine the part of speech of an individual sentence? Consider the sentence in English: "The can will rust." So, the – definite article or particle “order”; can - can simultaneously be a modal verb, and a noun, and a verb; will - modal verb, noun and verb; rust - noun or verb. In the statistical approach, it is necessary to construct a table of probabilities of using words in each grammatical meaning. This problem can be solved on the basis of test texts, analyzed manually. And one can immediately identify one of the problems: the word “can” is in most cases used as a verb, but sometimes it can also be a noun. Given this shortcoming, a model was created that takes into account the fact that an adjective or noun follows after the article:
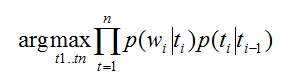
Where:
t - tag (noun, adjective, etc.)
w - word in the text (rust, can ...)
p (w | t) is the probability that the word w corresponds to the tag t
p (t1 | t2) is the probability that t1 comes after t2
From the proposed formula it is clear that we are trying to pick up tags so that the word matches the tag, and the tag matches the previous tag. This method allows to determine that “can” acts as a noun, and not as a modal verb.
This statistical model can be described as ergodic SMM:

Ergodic Markov model

Ergodic Markov model in practice
Each vertex in this scheme denotes a separate part of speech in which pairs are recorded (the word; the probability that the word refers specifically to this part of speech). Transitions show the possible probability of following one part of speech after another. For example, the probability that there will be 2 articles in a row, provided that the article is encountered, will be equal to 0.0016. This stage of speech recognition is very important, as the correct definition of the grammatical structure of the sentence allows you to choose the correct grammatical structure for expressive coloring of the reproduced sentence.
There are also n-gram models of speech flow recognition. They are based on the assumption that the probability of using the next word in a sentence depends only on n-1 words. Today, the most popular bigram and trigram language models. Search in such models occurs on the big table (case). Despite the fast-running algorithm, such models are not able to grasp semantic and syntactic links, if the dependent words are 5 words apart. Using the same n-gram models, where n is greater than 5, requires tremendous power.
As noted above, the most popular model today is the trigram model. The conditional probability of observing the sentence w1, ... wn is close to:
P (w1, ..., wn) = ΠP (wi | w1, ..., w2) ≈ ΠP (wi | wi- (n-1), ..., wi-1)
For example, consider the sentence “I want to go home”. The probability of this sentence can be calculated from the n-gram frequency count (in this example we take n = 3):
P (I, want, to, go, home) ≈ P (I) * P (want | I) * P (to | I, want) * P (go | want, to) * P (home | to, go )
It is worth noting that the long-range trigram model, in which the analysis is conducted not only by the two preceding words, but by any pair of words that are nearby. Such a trigram model can skip low-informative words, thereby improving the predictability of compatibility in the model.
The first electronic machine, synthesizing English speech, was presented in New York at a trade show in 1939 and was called voder, but the sound that it reproduced was extremely unclear. The very first speech recognition device came out in 1952 in the second year and was able to recognize numbers.
The process of speech recognition can distinguish the following difficulties: arbitrary, naive user; spontaneous speech, accompanied by agrammatism and speech "garbage"; the presence of acoustic noise and distortion; the presence of speech interference.
')
Of the variety of methods in this article, we will consider the possibility of creating a statistical model using hidden Markov models (SMM).
Part-of-speech tagging
When analyzing a natural language, the first step is to determine: to which part of the speech each of the words in the sentence refers. In English, the task at this stage is called Part-Of-Speech tagging. How can we determine the part of speech of an individual sentence? Consider the sentence in English: "The can will rust." So, the – definite article or particle “order”; can - can simultaneously be a modal verb, and a noun, and a verb; will - modal verb, noun and verb; rust - noun or verb. In the statistical approach, it is necessary to construct a table of probabilities of using words in each grammatical meaning. This problem can be solved on the basis of test texts, analyzed manually. And one can immediately identify one of the problems: the word “can” is in most cases used as a verb, but sometimes it can also be a noun. Given this shortcoming, a model was created that takes into account the fact that an adjective or noun follows after the article:
Where:
t - tag (noun, adjective, etc.)
w - word in the text (rust, can ...)
p (w | t) is the probability that the word w corresponds to the tag t
p (t1 | t2) is the probability that t1 comes after t2
From the proposed formula it is clear that we are trying to pick up tags so that the word matches the tag, and the tag matches the previous tag. This method allows to determine that “can” acts as a noun, and not as a modal verb.
This statistical model can be described as ergodic SMM:
Ergodic Markov model
Ergodic Markov model in practice
Each vertex in this scheme denotes a separate part of speech in which pairs are recorded (the word; the probability that the word refers specifically to this part of speech). Transitions show the possible probability of following one part of speech after another. For example, the probability that there will be 2 articles in a row, provided that the article is encountered, will be equal to 0.0016. This stage of speech recognition is very important, as the correct definition of the grammatical structure of the sentence allows you to choose the correct grammatical structure for expressive coloring of the reproduced sentence.
N-gram models
There are also n-gram models of speech flow recognition. They are based on the assumption that the probability of using the next word in a sentence depends only on n-1 words. Today, the most popular bigram and trigram language models. Search in such models occurs on the big table (case). Despite the fast-running algorithm, such models are not able to grasp semantic and syntactic links, if the dependent words are 5 words apart. Using the same n-gram models, where n is greater than 5, requires tremendous power.
As noted above, the most popular model today is the trigram model. The conditional probability of observing the sentence w1, ... wn is close to:
P (w1, ..., wn) = ΠP (wi | w1, ..., w2) ≈ ΠP (wi | wi- (n-1), ..., wi-1)
For example, consider the sentence “I want to go home”. The probability of this sentence can be calculated from the n-gram frequency count (in this example we take n = 3):
P (I, want, to, go, home) ≈ P (I) * P (want | I) * P (to | I, want) * P (go | want, to) * P (home | to, go )
It is worth noting that the long-range trigram model, in which the analysis is conducted not only by the two preceding words, but by any pair of words that are nearby. Such a trigram model can skip low-informative words, thereby improving the predictability of compatibility in the model.
Source: https://habr.com/ru/post/134954/
All Articles