Memory Technologies in vSphere 5.0
At habrahabr, memory technologies used in various hypervisors have been repeatedly discussed. These technologies are often taken under the common name - Memory Overcommitment.
Objectives that usually tend to achieve using memory overcommitment are two:
When running multiple virtual machines, some of them may contain identical memory pages. Page sharing allows you to keep such pages in the physical memory of the hypervisor in only one instance. As a result, if the memory page is used, for example, by two virtual machines (they run similar code), they both work with only one memory page. In other words, pages are deduplicated. The method used is the calculation of the hash of each page used and their comparison in the hash table. If a match occurs, the bit-matching process is additionally started. This generic page is read only. If one of the machines needs to change the content of the page, the creation of a private copy is initiated and the page is replaced. Only after remaping recording is allowed. Therefore, the insignificant decrease in performance, which is usually attributed to TPS (slightly less than 1%), lies precisely in the procedure for playing such a substitution for recording. TPS is enabled and works by default with 4KB guest memory pages. For pages the size of 2MB is turned off.
It turns on when the value of the free memory of the host decreases overcoming the 4% threshold. Allows you to displace already allocated, but not used memory pages. At best, these are the pages that the operating system usually marks in its “free” list (the operating system, roughly speaking, puts the pages of guest physical memory in two lists - “allocate” and “free”). From the pseudo-device vmmemctl, which is the driver in the VMware Tools bundle, the OS receives a request to allocate the required amount of memory, after receiving it, the pages of this volume are reported to the hypervisor as free.
The technology is compression of memory pages. It is activated along with the swapping of virtual machines (not to be confused with the OS swap) when the value of the free memory of the host overcomes the 2% threshold.
The method is to create a special memory area for each virtual machine - compression cache, which is designed to contain compressed memory pages. This area is initially empty and grows as it accumulates. When a decision is made to swap a page of memory, first it is analyzed for the level of compression. If the level is more than 50%, the page is compressed and placed in the compression cache.
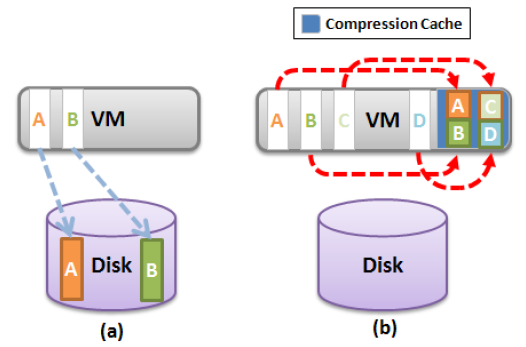
Thus, the page does not immediately fall into the swap (Figure a), but continues to be the physical memory of the host, but in a compressed form (Figure b). Thus, at least twice as much memory is available at the cost of access to it.
If this page is needed, it is decompressed from the cache and becomes available again in the guest memory. This significantly reduces the page retrieval time, compared to swap.
The volume of compression cache has a default size of 10% of the configured memory of the virtual machine. When the cache is filled, pages that have not been accessed for a long time are retrieved through decompression and fall into the swap. From compression cache, the pages never move to a swap in a compressed form.
When it is necessary to free up even that memory area which is used under compression cache (in case of extreme memory shortage), then all compressed pages are extracted and drop into the swap, and the area becomes free.
It is also important to note that the amount of memory used under the compression cache is attributed to the guest memory of the virtual machine. That is, this volume is not allocated separately, as is the memory for the overhead projector. Therefore, it is important to observe the optimal value of the maximum size of the compression cache. If the size is too modest, many compressed pages of memory will fall into the swap, significantly negating the advantages of memory compression. If it is too large, there will be too many pages in the cache that may not be in demand for a long time, and the bloated cache will simply waste the amount of guest memory. The behavior of the technology is governed by advanced parameters, the name of which begins with Mem.MemZip. For example, the cache size is primarily controlled by the Mem.MemZipMaxPc parameter.
')
In the case when using TPS, ballooning and memory compression, the hypervisor fails to exceed the host's free memory line by 2%, ESXi actively uses virtual machine swapping (pages start to drop into the .swap file created on the disk storage when the virtual machine starts).
As a rule, if we consider swapping virtual machines by themselves, it allows us to guarantee the release of a certain value of memory for a certain time, but it has such serious disadvantages:
Compare the performance dropdown of the Sharepoint configuration with and without memory comression:
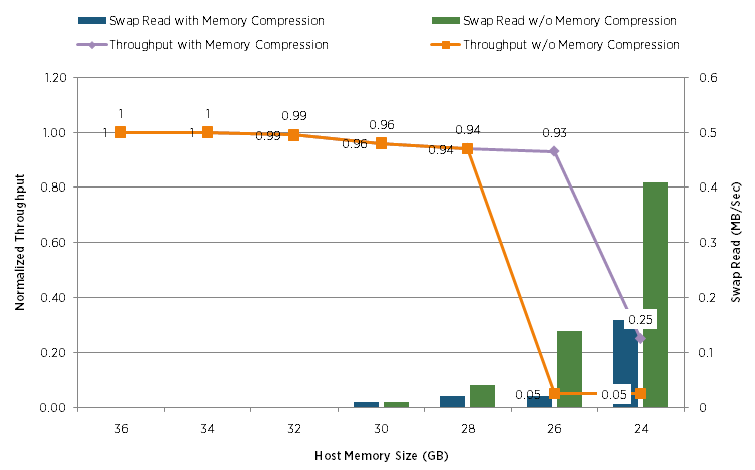
Horizontally, the amount of physical memory available to the hypervisor was gradually reduced. And along the vertical to the left you can trace the performance drop.
In this test, the drop in performance of Swingbench loads was compared in the same way :

And in this test, compare the performance drop with the use of Host Cache on SSD drives and without:
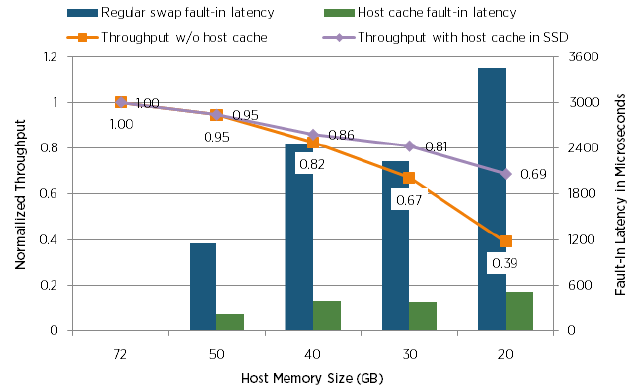
Unfortunately, it still remains and it is not clear what kind of disk was used in the test without Host Cache.
Additionally, all the graphs above show the value of swapping, which makes it easy to follow the work of the TPS and ballooning technologies, which were also included in these tests. For detailed tests of TPS and ballooning technologies, see the links below.
In this topic, I also think it should be remembered about the feature Memory fault isolation stated in ESXi 5.0. The hypervisor is able to detect failed memory regions and isolate them. So, if a bad region was detected among the pages of guest memory, the virtual machine is restarted. But the ESXi magenta screen will now fall only when such a region is occupied by the hypervisor code.
According to the materials:
www.petri.co.il/memory-compression-in-vsphere-4-1.htm
www.vmware.com/pdf/Perf_Best_Practices_vSphere5.0.pdf
www.vmware.com/files/pdf/mem_mgmt_perf_vsphere5.pdf
www.vmware.com/support/vsphere5/doc/vsphere-esx-vcenter-server-50-new-features.html
Objectives that usually tend to achieve using memory overcommitment are two:
- Increase utilization of physical memory of hosts with mainly active guest memory pages as much as possible;
- Increase the overall importance of consolidating virtual machines.
Transparent page sharing (TPS)
When running multiple virtual machines, some of them may contain identical memory pages. Page sharing allows you to keep such pages in the physical memory of the hypervisor in only one instance. As a result, if the memory page is used, for example, by two virtual machines (they run similar code), they both work with only one memory page. In other words, pages are deduplicated. The method used is the calculation of the hash of each page used and their comparison in the hash table. If a match occurs, the bit-matching process is additionally started. This generic page is read only. If one of the machines needs to change the content of the page, the creation of a private copy is initiated and the page is replaced. Only after remaping recording is allowed. Therefore, the insignificant decrease in performance, which is usually attributed to TPS (slightly less than 1%), lies precisely in the procedure for playing such a substitution for recording. TPS is enabled and works by default with 4KB guest memory pages. For pages the size of 2MB is turned off.
Ballooning
It turns on when the value of the free memory of the host decreases overcoming the 4% threshold. Allows you to displace already allocated, but not used memory pages. At best, these are the pages that the operating system usually marks in its “free” list (the operating system, roughly speaking, puts the pages of guest physical memory in two lists - “allocate” and “free”). From the pseudo-device vmmemctl, which is the driver in the VMware Tools bundle, the OS receives a request to allocate the required amount of memory, after receiving it, the pages of this volume are reported to the hypervisor as free.
Memory Compression
The technology is compression of memory pages. It is activated along with the swapping of virtual machines (not to be confused with the OS swap) when the value of the free memory of the host overcomes the 2% threshold.
The method is to create a special memory area for each virtual machine - compression cache, which is designed to contain compressed memory pages. This area is initially empty and grows as it accumulates. When a decision is made to swap a page of memory, first it is analyzed for the level of compression. If the level is more than 50%, the page is compressed and placed in the compression cache.
Thus, the page does not immediately fall into the swap (Figure a), but continues to be the physical memory of the host, but in a compressed form (Figure b). Thus, at least twice as much memory is available at the cost of access to it.
If this page is needed, it is decompressed from the cache and becomes available again in the guest memory. This significantly reduces the page retrieval time, compared to swap.
The volume of compression cache has a default size of 10% of the configured memory of the virtual machine. When the cache is filled, pages that have not been accessed for a long time are retrieved through decompression and fall into the swap. From compression cache, the pages never move to a swap in a compressed form.
When it is necessary to free up even that memory area which is used under compression cache (in case of extreme memory shortage), then all compressed pages are extracted and drop into the swap, and the area becomes free.
It is also important to note that the amount of memory used under the compression cache is attributed to the guest memory of the virtual machine. That is, this volume is not allocated separately, as is the memory for the overhead projector. Therefore, it is important to observe the optimal value of the maximum size of the compression cache. If the size is too modest, many compressed pages of memory will fall into the swap, significantly negating the advantages of memory compression. If it is too large, there will be too many pages in the cache that may not be in demand for a long time, and the bloated cache will simply waste the amount of guest memory. The behavior of the technology is governed by advanced parameters, the name of which begins with Mem.MemZip. For example, the cache size is primarily controlled by the Mem.MemZipMaxPc parameter.
')
Hypervisor swapping
In the case when using TPS, ballooning and memory compression, the hypervisor fails to exceed the host's free memory line by 2%, ESXi actively uses virtual machine swapping (pages start to drop into the .swap file created on the disk storage when the virtual machine starts).
As a rule, if we consider swapping virtual machines by themselves, it allows us to guarantee the release of a certain value of memory for a certain time, but it has such serious disadvantages:
- The hypervisor does not really know which memory pages are best suited as the operating system knows about them;
- For the same reason, there is the problem of double swapping. When the OS memory management manager decides to zapvapirovat the same page, which the hypervisor has already managed to zavapirovat, the page is retrieved by the hypervisor, and immediately falls into the operating system swap;
- And of course, swapping is very expensive for a virtual machine. Delays during which pages are extracted from a swap can reach up to ten milliseconds. This leads to a serious drop in performance.
- Reducing the effect of intersection with the work of the OS memory management manager by randomly selecting memory pages for swapping;
- Applications Memory Compression to reduce the number of pages sent to the swap;
- The use of SSD drives for storage swap. So, having transferred a swap to an SSD, whose reading speed is much higher than that of regular disks, you can significantly reduce the delay in extracting pages from the swap. The name given to this approach is Host Cache, and it is recommended to use local SSDs rather than to use on remote storage.
Some results of tests conducted by VMware
Compare the performance dropdown of the Sharepoint configuration with and without memory comression:
Horizontally, the amount of physical memory available to the hypervisor was gradually reduced. And along the vertical to the left you can trace the performance drop.
In this test, the drop in performance of Swingbench loads was compared in the same way :
And in this test, compare the performance drop with the use of Host Cache on SSD drives and without:
Unfortunately, it still remains and it is not clear what kind of disk was used in the test without Host Cache.
Additionally, all the graphs above show the value of swapping, which makes it easy to follow the work of the TPS and ballooning technologies, which were also included in these tests. For detailed tests of TPS and ballooning technologies, see the links below.
In this topic, I also think it should be remembered about the feature Memory fault isolation stated in ESXi 5.0. The hypervisor is able to detect failed memory regions and isolate them. So, if a bad region was detected among the pages of guest memory, the virtual machine is restarted. But the ESXi magenta screen will now fall only when such a region is occupied by the hypervisor code.
According to the materials:
www.petri.co.il/memory-compression-in-vsphere-4-1.htm
www.vmware.com/pdf/Perf_Best_Practices_vSphere5.0.pdf
www.vmware.com/files/pdf/mem_mgmt_perf_vsphere5.pdf
www.vmware.com/support/vsphere5/doc/vsphere-esx-vcenter-server-50-new-features.html
Source: https://habr.com/ru/post/134631/
All Articles