Kinect for remote control
We at Redmadrobot in the intervals between playing the Xbox are watching with interest what is already being done and what else can be done with the help of Microsoft Kinect. Well, of course, we are also conducting our own experiments - I'll tell you about one such.
With the development of buttonless, wireless, and later generally contactless ways of interacting with devices, the interfaces provide the user with less and less feedback: first, he was deprived of pragmatic confidence in switching the switches, then the already small feedback from pressing the button was taken away, and now even tactile sensations go into the background.
The Internet is gradually beginning to be filled with solutions that recognize gestures with the help of Kinect, but almost all of them do not provide any information at all in the process of executing the gesture, and only when the action has been completed do they reflect any reaction to it. This is what we wanted to fix, and this is what happened:
')
So, the task before me was to make the user see what he was doing right in the process of making the gesture with his hands.
In the choice of gestures, I was guided by those that each of us observes in most mobile phones with a touchscreen: scrolling in four directions, click (and all this is separate for each hand), pinch-zoom. Also, of course, there is a cursor mode when the active elements are selected by pointing and holding.
The option to recognize the gesture after the fact, that is, to react when the user has already “wound a circle in the air”, does not suit us. To do it differently, you need to somehow decide on the choice of the moment when the user begins to perform the gesture.
For such purposes, you can use a certain “starting” posture ( you can read about the posture detector and its implementation), you can precede any “control” gesture (only after which the hand gesture and its progress will be monitored), and you can select the “active zone” in monitor user actions.
I went the last way, and this is how this zone looks like schematically:

I will make a reservation that you can still experiment with this: for example, make a sector of a disk, or for each hand to come up with their own zone, and not just one common. The main thing is that this zone is “tied” to the user and moves along with it.
We have reduced the dimension and now, in fact, we are dealing with the movement of points on a plane. We obtain the initial coordinates of the point and, dynamically, the trajectory of its movement:
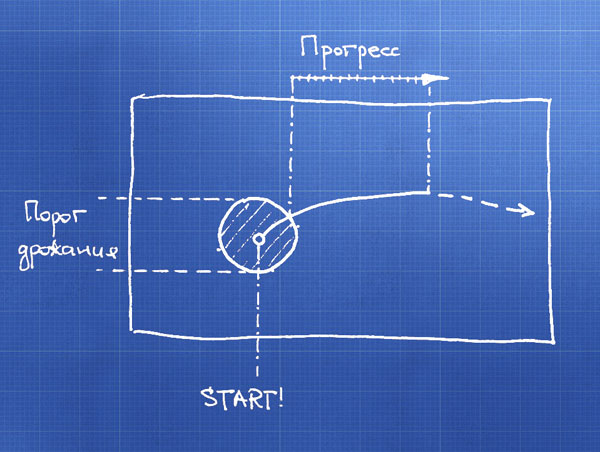
First of all, we level the hand shake and the error of the coordinates detection by the sensor - if the movement occurs inside the “shake threshold”, then we don’t react to this, we believe that the hand is not moving. When a point leaves this zone, we determine the type of gesture according to which direction the arm is offset from the center.
You can begin to animate the interface - we already know what the user is doing, and simply monitor the progress. For pinch gestures, we measure the distance between the hands and the dynamics of its change.
We immediately limited the area under consideration to the requirement to determine the progress of the gesture in the process of its implementation. But if you don’t bother about this, you can fasten the hidden Markov models, the intersection of virtual spheres in space, and many other interesting things.
If you are interested, see the topic with instructions , attend and participate in the Microsoft Research Kinect application development contest .
PS Questions, including work with the sensor, are welcome
Interaction problem
With the development of buttonless, wireless, and later generally contactless ways of interacting with devices, the interfaces provide the user with less and less feedback: first, he was deprived of pragmatic confidence in switching the switches, then the already small feedback from pressing the button was taken away, and now even tactile sensations go into the background.
The Internet is gradually beginning to be filled with solutions that recognize gestures with the help of Kinect, but almost all of them do not provide any information at all in the process of executing the gesture, and only when the action has been completed do they reflect any reaction to it. This is what we wanted to fix, and this is what happened:
')
Requirements
So, the task before me was to make the user see what he was doing right in the process of making the gesture with his hands.
In the choice of gestures, I was guided by those that each of us observes in most mobile phones with a touchscreen: scrolling in four directions, click (and all this is separate for each hand), pinch-zoom. Also, of course, there is a cursor mode when the active elements are selected by pointing and holding.
About the process
The option to recognize the gesture after the fact, that is, to react when the user has already “wound a circle in the air”, does not suit us. To do it differently, you need to somehow decide on the choice of the moment when the user begins to perform the gesture.
For such purposes, you can use a certain “starting” posture ( you can read about the posture detector and its implementation), you can precede any “control” gesture (only after which the hand gesture and its progress will be monitored), and you can select the “active zone” in monitor user actions.
I went the last way, and this is how this zone looks like schematically:
I will make a reservation that you can still experiment with this: for example, make a sector of a disk, or for each hand to come up with their own zone, and not just one common. The main thing is that this zone is “tied” to the user and moves along with it.
We have reduced the dimension and now, in fact, we are dealing with the movement of points on a plane. We obtain the initial coordinates of the point and, dynamically, the trajectory of its movement:
First of all, we level the hand shake and the error of the coordinates detection by the sensor - if the movement occurs inside the “shake threshold”, then we don’t react to this, we believe that the hand is not moving. When a point leaves this zone, we determine the type of gesture according to which direction the arm is offset from the center.
You can begin to animate the interface - we already know what the user is doing, and simply monitor the progress. For pinch gestures, we measure the distance between the hands and the dynamics of its change.
What else?
We immediately limited the area under consideration to the requirement to determine the progress of the gesture in the process of its implementation. But if you don’t bother about this, you can fasten the hidden Markov models, the intersection of virtual spheres in space, and many other interesting things.
If you are interested, see the topic with instructions , attend and participate in the Microsoft Research Kinect application development contest .
PS Questions, including work with the sensor, are welcome
Source: https://habr.com/ru/post/134467/
All Articles